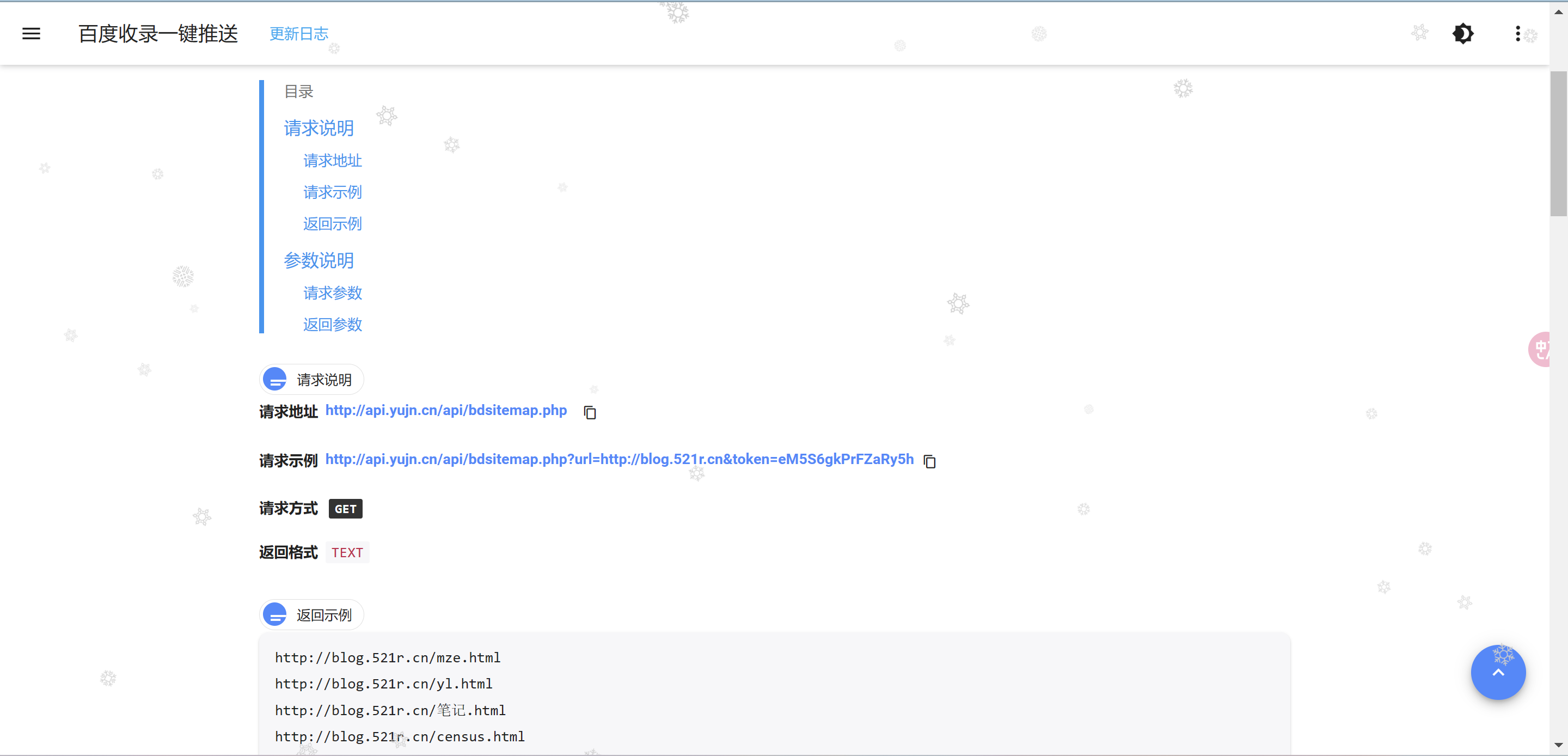
搜索到
47
篇与
的结果
-
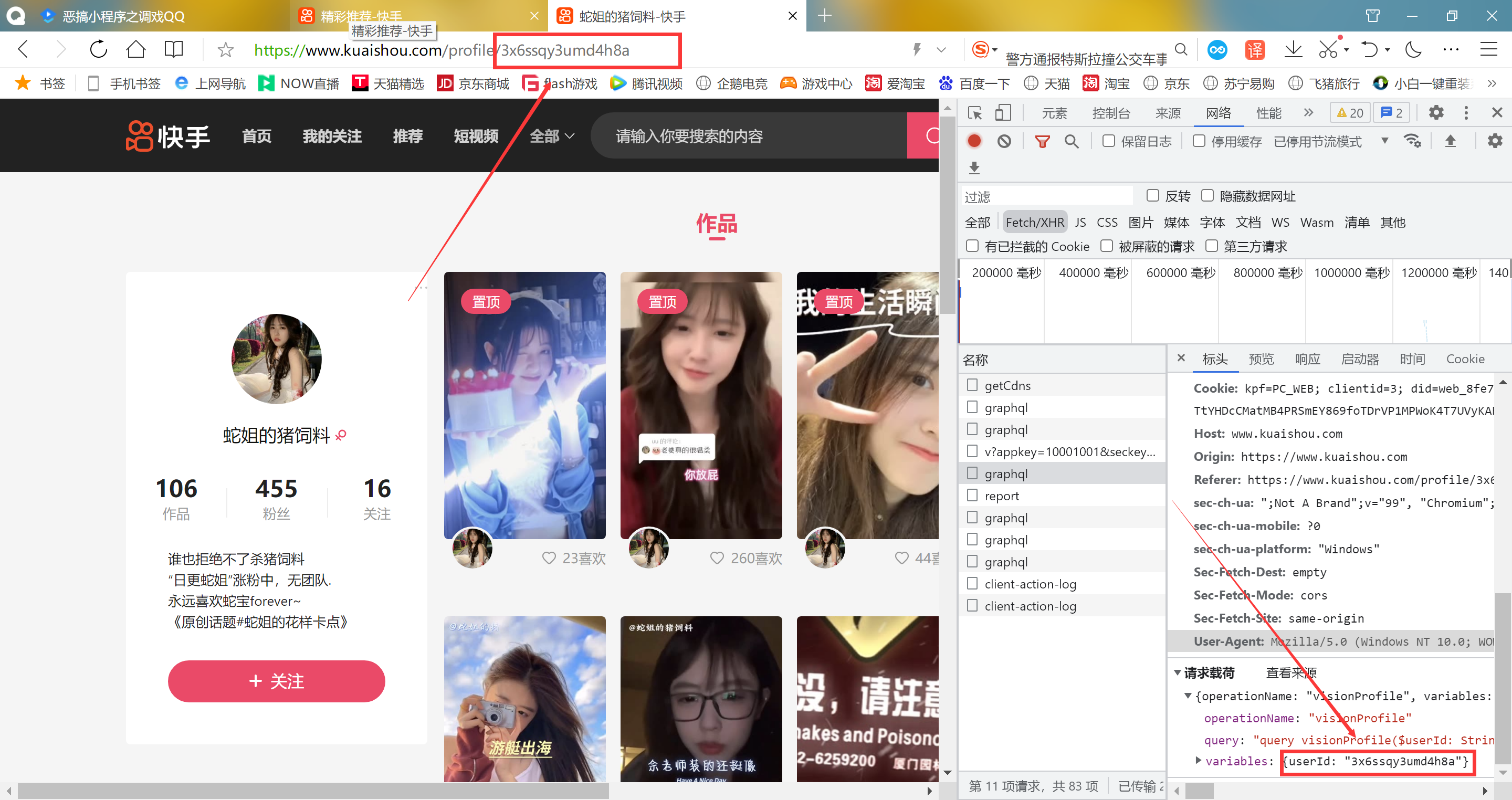
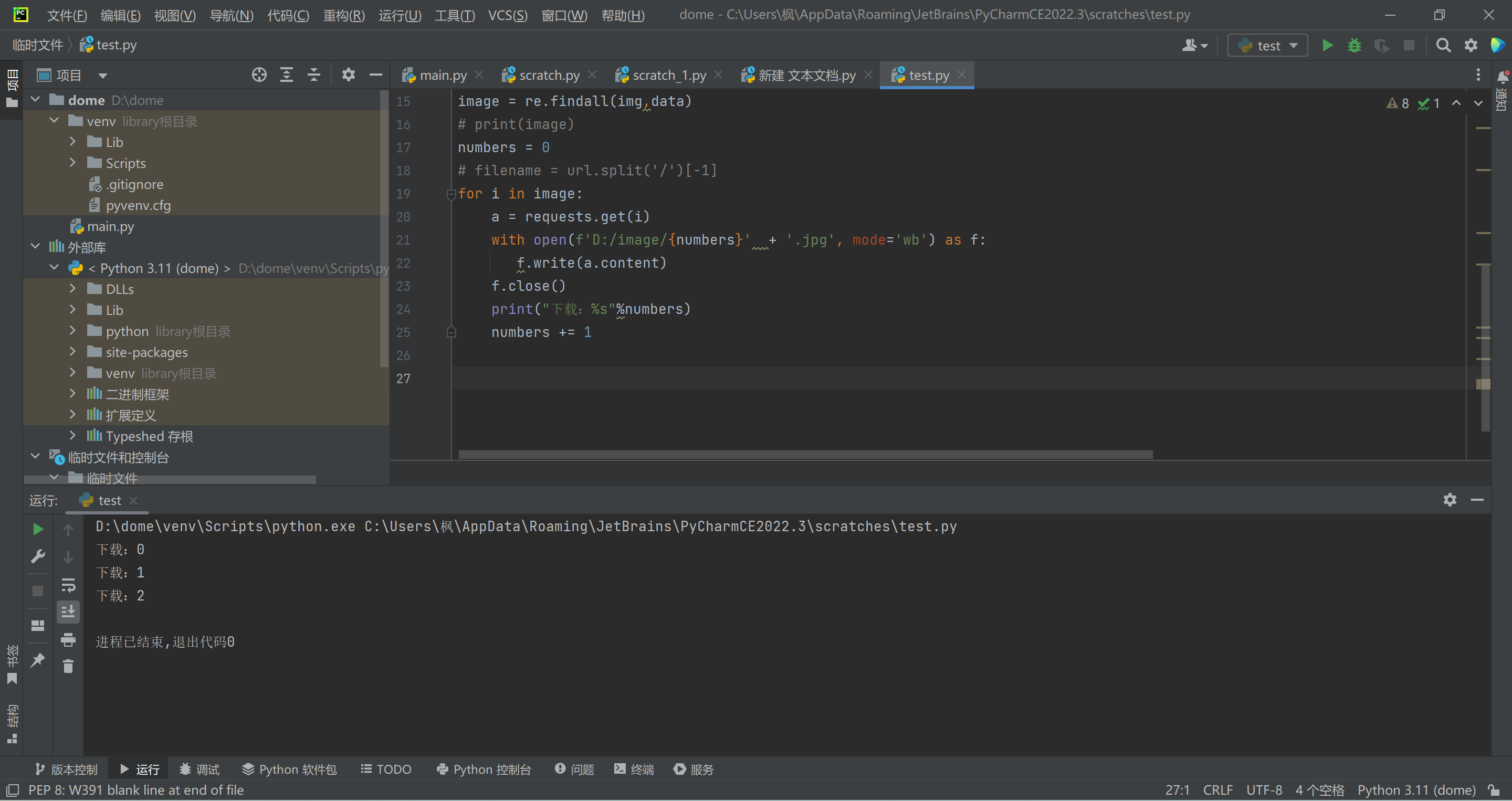
 Python 批量爬取快手点赞视频 前言 好久没有分享爬虫了,随便分享一个之前写的吧,也没看见有人发布这种爬虫,代码也很简单,这个只能批量爬取 自己点赞视频。嗯嗯...是需要抓取cookie的,就是快手喜欢列表cookie,直接看截图:抓包按F12进入开发人员就可以抓了,记得刷新页面才会出现数据包说明 模块自己导入,视频默认保存到D:/video/文件夹,可以自己更改 下面代码自带了cookie,需要更换自己抓包效果代码import requests import re import os cookie ='kpf=PC_WEB; clientid=3; did=web_36aa4b497d25f5a44d48448da60afe50; didv=1687578212131; clientid=3; kpf=PC_WEB; kpn=KUAISHOU_VISION; _did=web_244010593DBE3F9B; ksliveShowClipTip=true; userId=3561544837; kpn=KUAISHOU_VISION; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqAB7j4FNJ3gbkzArjNtSCbdWOMoNmx1qbzusHDTZFf8CLiaBK0j0p7Sy5980HE9Q6WZ1LIU2oMY6zpVG0ETh8k6WOwYNPPKtBNmaPhN92KIHFPL6EPhpd7YKqcbeCopAZVjDsVBohAyZT9oAAtnvlHO4YpC2kitedh_ohGIblSJnrrAtdOvWc1xoEi-RjY0ms0ZD73nxvS3hmz1gJx_Qc7bChoStEyT9S95saEmiR8Dg-bb1DKRIiAId7DYCn2lhOUlYHyKsUDE-ZpLEcSd42tmMjdhGFiBRSgFMAE; kuaishou.server.web_ph=cd2589031aefc1a54981a4d60e57e7033071' ## 这里填你自己的cookie值,自己抓包吧 if not os.path.exists('D:/video/'): os.mkdir(('D:/video/')) ## 这里可修改保存地址 def get_next(pcursor): json = { 'operationName': "visionProfileLikePhotoList", 'query': "fragment photoContent on PhotoEntity {\n id\n duration\n caption\n originCaption\n likeCount\n viewCount\n commentCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n musicBlocked\n __typename\n}\n\nfragment feedContent on Feed {\n type\n author {\n id\n name\n headerUrl\n following\n headerUrls {\n url\n __typename\n }\n __typename\n }\n photo {\n ...photoContent\n __typename\n }\n canAddComment\n llsid\n status\n currentPcursor\n tags {\n type\n name\n __typename\n }\n __typename\n}\n\nquery visionProfileLikePhotoList($pcursor: String, $page: String, $webPageArea: String) {\n visionProfileLikePhotoList(pcursor: $pcursor, page: $page, webPageArea: $webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n ...feedContent\n __typename\n }\n hostName\n pcursor\n __typename\n }\n}\n", 'variables': {"userId": 'id', "pcursor": pcursor, "page": "profile"""} } headers = { 'Cookie': cookie, 'Host': "www.kuaishou.com", 'Origin': "https://www.kuaishou.com", 'Referer': f"https://www.kuaishou.com/profile/{id}", 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.68", } url = 'https://www.kuaishou.com/graphql' response = requests.post(url=url, headers=headers, json=json) json_data = response.json() feeds = json_data['data']['visionProfileLikePhotoList']['feeds'] pcursor = json_data['data']['visionProfileLikePhotoList']['pcursor'] len_num = len(feeds) for feed in range(0, len_num): photoUrl = feeds[feed]['photo']['photoUrl'] originCaption = feeds[feed]['photo']['originCaption'] originCaption = re.sub('[\\/:*?<>|\\n#@)\》\."\《(\r]', '', originCaption) print(originCaption, photoUrl) with open(f'D:/video/{originCaption}''.mp4',mode='wb')as f: video = requests.get(photoUrl).content f.write(video) if pcursor=='no_more': return '' get_next(pcursor) get_next("")
Python 批量爬取快手点赞视频 前言 好久没有分享爬虫了,随便分享一个之前写的吧,也没看见有人发布这种爬虫,代码也很简单,这个只能批量爬取 自己点赞视频。嗯嗯...是需要抓取cookie的,就是快手喜欢列表cookie,直接看截图:抓包按F12进入开发人员就可以抓了,记得刷新页面才会出现数据包说明 模块自己导入,视频默认保存到D:/video/文件夹,可以自己更改 下面代码自带了cookie,需要更换自己抓包效果代码import requests import re import os cookie ='kpf=PC_WEB; clientid=3; did=web_36aa4b497d25f5a44d48448da60afe50; didv=1687578212131; clientid=3; kpf=PC_WEB; kpn=KUAISHOU_VISION; _did=web_244010593DBE3F9B; ksliveShowClipTip=true; userId=3561544837; kpn=KUAISHOU_VISION; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqAB7j4FNJ3gbkzArjNtSCbdWOMoNmx1qbzusHDTZFf8CLiaBK0j0p7Sy5980HE9Q6WZ1LIU2oMY6zpVG0ETh8k6WOwYNPPKtBNmaPhN92KIHFPL6EPhpd7YKqcbeCopAZVjDsVBohAyZT9oAAtnvlHO4YpC2kitedh_ohGIblSJnrrAtdOvWc1xoEi-RjY0ms0ZD73nxvS3hmz1gJx_Qc7bChoStEyT9S95saEmiR8Dg-bb1DKRIiAId7DYCn2lhOUlYHyKsUDE-ZpLEcSd42tmMjdhGFiBRSgFMAE; kuaishou.server.web_ph=cd2589031aefc1a54981a4d60e57e7033071' ## 这里填你自己的cookie值,自己抓包吧 if not os.path.exists('D:/video/'): os.mkdir(('D:/video/')) ## 这里可修改保存地址 def get_next(pcursor): json = { 'operationName': "visionProfileLikePhotoList", 'query': "fragment photoContent on PhotoEntity {\n id\n duration\n caption\n originCaption\n likeCount\n viewCount\n commentCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n musicBlocked\n __typename\n}\n\nfragment feedContent on Feed {\n type\n author {\n id\n name\n headerUrl\n following\n headerUrls {\n url\n __typename\n }\n __typename\n }\n photo {\n ...photoContent\n __typename\n }\n canAddComment\n llsid\n status\n currentPcursor\n tags {\n type\n name\n __typename\n }\n __typename\n}\n\nquery visionProfileLikePhotoList($pcursor: String, $page: String, $webPageArea: String) {\n visionProfileLikePhotoList(pcursor: $pcursor, page: $page, webPageArea: $webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n ...feedContent\n __typename\n }\n hostName\n pcursor\n __typename\n }\n}\n", 'variables': {"userId": 'id', "pcursor": pcursor, "page": "profile"""} } headers = { 'Cookie': cookie, 'Host': "www.kuaishou.com", 'Origin': "https://www.kuaishou.com", 'Referer': f"https://www.kuaishou.com/profile/{id}", 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.68", } url = 'https://www.kuaishou.com/graphql' response = requests.post(url=url, headers=headers, json=json) json_data = response.json() feeds = json_data['data']['visionProfileLikePhotoList']['feeds'] pcursor = json_data['data']['visionProfileLikePhotoList']['pcursor'] len_num = len(feeds) for feed in range(0, len_num): photoUrl = feeds[feed]['photo']['photoUrl'] originCaption = feeds[feed]['photo']['originCaption'] originCaption = re.sub('[\\/:*?<>|\\n#@)\》\."\《(\r]', '', originCaption) print(originCaption, photoUrl) with open(f'D:/video/{originCaption}''.mp4',mode='wb')as f: video = requests.get(photoUrl).content f.write(video) if pcursor=='no_more': return '' get_next(pcursor) get_next("") -
Chatgtp API接口白嫖方法 介绍 有一些gtp网页是可以抓到它的数据接口的,打开网页,按F12进行抓包,获取他的接口,实现白嫖的方法,也可以利用这个接口自己搭建个API接口,白嫖 ::(滑稽)抓包站点:https://ai.haircv.com/ 很显然这是他的数据包,post请求,也可以看到他响应的内容{card-list}{card-list-item}{/card-list-item}{/card-list}代码下面是获取接口,然后再调用成一个API,自己新建一个php文件,就可调用了 <?php $msg = $_GET['msg'];//需要提问的内容 // 构建 POST 请求的数据 $data = array( 'messages' => array( array( 'role' => 'system', 'content' => 'IMPORTANT: You are a virtual assistant powered by the gpt-3.5-turbo model, now time is ' ), array( 'role' => 'user', 'content' => $msg ) ), 'stream' => true, 'model' => 'gpt-3.5-turbo', 'temperature' => 0.5, 'presence_penalty' => 0 ); // 发送 POST 请求 $curl = curl_init(); $url = 'https://ai.haircv.com/api/openai/v1/chat/completions'; //这里填你抓到的接口 curl_setopt($curl, CURLOPT_URL, $url); curl_setopt($curl, CURLOPT_POST, true); curl_setopt($curl, CURLOPT_POSTFIELDS, json_encode($data)); curl_setopt($curl, CURLOPT_RETURNTRANSFER, true); curl_setopt($curl, CURLOPT_HTTPHEADER, array('Content-Type: application/json')); $response = curl_exec($curl); curl_close($curl); //数据处理 $pattern = '/content\":\"(.*?)\"}/'; preg_match_all($pattern, $response, $matches); foreach ($matches[1] as $result) { echo $result; }
-
宝塔 Linux 面板V7.9.10开心版 介绍本脚本未加密,有没有后门大家自己看就知道了,仅仅将官方的脚本本地化了,未经任何修改,请放心使用!本次脚本支持:Centos 7、Debian、Ubuntu、Fedora!安装指令{callout color="#4da4ef"}Linux面板 7.9.10 升级企业版命令 1{/callout}curl https://io.bt.sy/install/update_panel.sh|bash{callout color="#4da4ef"}Linux面板 7.9.10 升级企业版命令 2{/callout}curl http://io.bt.sy/install/update6.sh|bash注意:从官方版切换到开心版后重新登陆面板会密码错误 (因加密机制不同,登陆密码被重置成随机的)需要大家bt5修改下密码!{dotted startColor="#ff6c6c" endColor="#1989fa"/}如果使用了官方版有安装了数据库切换到开心版数据库的root密码同样错误(需要自己修改下数据库的root密码)不是被黑了哦!!!!
-
CTF-Web基础题 CTF介绍{card-default label="CTF简介" width=""} CTF(Capture The Flag)中文一般译作夺旗赛,在网络安全领域中指的是网络安全技术人员之间进行技术竞技的一种比赛形式。CTF起源于1996年DEFCON全球黑客大会,以代替之前黑客们通过互相发起真实攻击进行技术比拼的方式。发展至今,已经成为全球范围网络安全圈流行的竞赛形式,2013年全球举办了超过五十场国际性CTF赛事。而DEFCON作为CTF赛制的发源地,DEFCON CTF也成为了目前全球最高技术水平和影响力的CTF竞赛,类似于CTF赛场中的“世界杯”{/card-default}{message type="success" content="web 主要是向目标服务器发送 http 请求,返回 flag"/}1.直接查看源代码{card-list}{card-list-item}http://lab1.xseclab.com/base1_4a4d993ed7bd7d467b27af52d2aaa800/index.php{/card-list-item}{card-list-item}直接查看源代码就可以找到key值{/card-list-item}{/card-list}2.查看HTTP请求或响应头{card-list}{card-list-item}http://lab1.xseclab.com/base7_eb68bd2f0d762faf70c89799b3c1cc52/index.php{/card-list-item}{card-list-item}可在响应头里面查看到key{/card-list-item}{/card-list}3.修改或添加HTTP请求头1、Referer来源伪造{card-describe title=" "}例如:在 www.google.com 里有一个 www.baidu.com 超链接,当点击这个链接跳转到baidu的时候,浏览器向baidu发出的请求信息里就有:Referer=http://www.google.com{/card-describe}通过brup拦截,再使用Reapter修改Referer为想指定的URL2、 X-Forwarded-For:IP伪造客户端向服务器发送请求时,会发送自己的IP地址使用brup拦截请求包,在Proxy里面发送到Repeater,将Http头中的X-Forwarded-For改为想改的ip{card-list}{card-list-item}{/card-list-item}{/card-list}4.User-Agent:用户代理(就是用什么浏览器什么的)http://lab1.xseclab.com/base6_6082c908819e105c378eb93b6631c4d3/index.php5.Cookie的修改{card-default label="cookies介绍" width=""} cookies是由网络服务器存储在你电脑硬盘上的一个txt类型的小文件,它和你的网络浏览行为有关,所以存储在你电脑上的cookies就好像你的一张身份证,你电脑上的cookies和其他电脑上的cookies是不一样的;cookies不能被视作代码执行,也不能成为病毒,所以它对你基本无害。cookie可以在报文头的前面进行设置。{/card-default}6.302跳转的中转网页有信息{card-list}{card-list-item}http://lab1.xseclab.com/base8_0abd63aa54bef0464289d6a42465f354/index.php{/card-list-item}{card-list-item}{/card-list-item}{/card-list}7.robots.txt文件获取信息{card-default label="robots介绍" width=""} robots协议是网站跟爬虫间的协议,用简单直接的txt格式文本方式告诉对应的爬虫被允许的权限,也就是说robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。{/card-default}{card-list}{card-list-item}http://lab1.xseclab.com/base12_44f0d8a96eed21afdc4823a0bf1a316b/index.php{/card-list-item}{card-list-item}{/card-list-item}{/card-list}{abtn icon="" color="#ff6800" href="https://blog.csdn.net/weixin_52182264/article/details/124322526?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168240703516800197013335%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=168240703516800197013335&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-4-124322526-null-null.142^v86^insert_down1,239^v2^insert_chatgpt&utm_term=php%20web%E5%9F%BA%E7%A1%80&spm=1018.2226.3001.4187" radius="17.5PX" content="转载CTF-Web基础题"/}
-
宝塔最新企业版加美化模版 介绍{message type="warning" content=" 资源收集于网络,更多请自行测试 :@(汗) "/}宝塔企业7.9.9指令yum install -y wget && wget -O install.sh http://jsjs.xn--n6q058g.tk/down.php/65f0164d0846e99b28c9416a65b66bdd.sh && sh install.shcurl https://io.bt.sy/install/update_panel.sh|bash美化模版指令wget -O btpanel_theme.zip https://www.baota.me/script/btpanel_theme/BTPanel_theme_linux_799.zip && unzip -o btpanel_theme.zip -d /www/server/ && /etc/init.d/bt restar效果{card-list}{card-list-item}{/card-list-item}{/card-list}
-
白嫖又拍云代金券(云存储+https证书) 又拍云{card-default label="介绍" width=""} 想必都知道,该站点从建站起,就用的又拍云,来存放网站的图片、CSS、JS等静态资源。而且就从建站初,我就申请了又拍云联盟,一年送65元代金券。所以,我在又拍云上花费的资源总计不超过一元。 :@(皱眉) 那么接下来就告诉大家如何通过又拍云联盟来申请又拍云代金券,总价值65元,时常为一年。到期后,可以再次申请。{/card-default}介绍{tabs}{tabs-pane label="详细介绍"} 又拍云官方关于又拍云联盟的描述为:免费存储空间10GB,每月免费15GB CDN流量。经过实测,又拍云联盟只会给你发送65元代金券,至于流量什么的,都包含在代金卷里面。自己做个图床API什么的完全没有问题,还送https免费证书,cdn加速! :@(脸红) 我这已经存储30多个G的文件,一天也就几毛钱,都是扣代金券的 :@(邪恶) {/tabs-pane}{/tabs}又拍云联盟申请{card-default label=" " width=""}一、先去官方网站注册: 又拍云官网 {message type="success" content="ps:需要实名认证、扫脸,这些都是大企业,不要担心信息泄露什么的,本人一直在用"/}{lamp/}二、官方给的申请方式,需要在你的网站页面添加又拍云logo以及又拍云联盟地址比如:代码:<span style="line-height:10px;">本网站由<a href="https://www.upyun.com/?utm_source=lianmeng&utm_medium=referral" target="_blank" rel="nofollow"><img src="http://cloud.521r.cn/view.php/6bdb8361db95808e6d8d196d37d8cbcc.png"style="width:50px;height:30px;"></a>提供云存储服务 {lamp/}三、然后去又拍云联盟申请:又拍云联盟 填上你要申请的网址,基本一天左右会出结果{lamp/}四、这是规则,申请了就不要删除链接{lamp/}{/card-default}总结 又拍云真的很良心,之前也用过腾讯云、七牛云,一天存储流量好几块,对于新手来讲真的很贵,但又拍云真的是免费 ::(滑稽)
-
Typecho 批量更换文章中的图片地址 前言 最近,博客将图片都上传到了又拍云对象存储了(关于本站图床的一些配置),本地服务器的图片也删除了。那么,如何批量修改文章中那么多的图片地址呢?批量修改图片地址这里用phpMyAdmin工具进行演示,当然也可以用navicat等数据库管理工具,都是一样的。首先我们需要确定要更换的地址,要注意路径,比如原本本地服务器存储的域名地址是https://www.xxxx.cn/image/2023/。然后你将2023路径下的所有图片,都上传到了对象存储,地址是:https://img.xxxx.cn/image/2023/ 那么这个时候你只需要批量将原本的https://www.xxx.cn/image/ 更改成https://img.xxxx.cn/image (为什么要带上image呢主要防止有些地方链接非图片,被误更改了)。然后打开数据库管理工具,选择 typecho 的数据库,打开 typecho_contents 表,点击SQL,执行下列sql语句。(这里是 更改文章内图片 的)UPDATE typecho_contents SET text = REPLACE(text,'旧域名地址','新域名地址');然后再去 typecho_fields 表执行下列sql语句(这里是 更改封面图片 的)UPDATE typecho_fields SET str_value = REPLACE(str_value,'旧域名地址','新域名地址');执行后,显示批量更改成功,然后就可以返回博客的文章中查看图片链接是否正确,是否能被访问啦!
-
ChatGPT账号共享 介绍 ChatGPT最近有多火爆,大家应该都是有目共睹的,可以说是很神奇的功能,完全超过你的想象,你能跟它进行交流,ChatGPT的运算速度远快于人类,学习速度超级快速并且不断迭代。吸引无数人去试用它,想要正常使用还需要注册,这里分享一下共享账号,资源来源网络,我也不能确定能不能使用 :@(狂汗) 。ChatGPT共享账号{card-list}{card-list-item}账号1:vickye89@hotmail.com密码:LeZ25X5dwL账号2:eugeniev552@hotmail.com密码2:4w95MnvIvc账号3:ayakonewuyo@hotmail.com密码3:q8UCd2lST4账号4:ludmillasteb9@hotmail.com密码4:7sb54Oii8I账号5:chr89kuchto@hotmail.com密码5:Cea7IQj5ud账号6:emil03mk@hotmail.com密码6:ENC82hip2A账号7:lydiavn9ktutoky@hotmail.com密码7:6351VsZz25账号8:tulagj3@hotmail.com密码8:Wx99eCqer7账号9:prue56zjehle@hotmail.com密码9:8398k84X85账号10:vernitagq2@hotmail.com密码10:geFfr4H0x9账号11:kirstiealtqw@hotmail.com密码11:1FBbV8OJg9账号12:ralphnamer32d@hotmail.com密码12:F85T86YtbL账号13:celinabullievmu@hotmail.com密码13:OqTz0lj525账号14:chanafdidelaet@hotmail.com密码14:6x3CM4pPYY账号15:alita07pbogdon@hotmail.com密码15:Umppl1ylc0账号16:averilltxgt@hotmail.com密码16:94cymN2p42账号17:mobyfotohy7@hotmail.com密码17:c8iJi0Fd账号18:muficylequ9@hotmail.com密码18:5p0KWJf1D账号19:naehahogujo0@hotmail.com密码19:xgH5o3jKV账号20:naejexelibu@hotmail.com密码20:fZg44fVeh{/card-list-item}{/card-list}以下是100个账号,各位可以自行体验账号格式:账号---密码(-为分隔符不要输入){card-list}{card-list-item}vickye89@hotmail.com---LeZ25X5dwLeugeniev552@hotmail.com---4w95MnvIvcayakonewuyo@hotmail.com---q8UCd2lST4ludmillasteb9@hotmail.com---7sb54Oii8Ichr89kuchto@hotmail.com---Cea7IQj5udemil03mk@hotmail.com---ENC82hip2Alydiavn9ktutoky@hotmail.com---6351VsZz25tulagj3@hotmail.com---Wx99eCqer7prue56zjehle@hotmail.com---8398k84X85vernitagq2@hotmail.com---geFfr4H0x9kirstiealtqw@hotmail.com---1FBbV8OJg9ralphnamer32d@hotmail.com---F85T86YtbLcelinabullievmu@hotmail.com---OqTz0lj525chanafdidelaet@hotmail.com---6x3CM4pPYYalita07pbogdon@hotmail.com---Umppl1ylc0averilltxgt@hotmail.com---94cymN2p42kaeleeviarla@hotmail.com---GUR00fTOS5johniehsro@hotmail.com---Env5d4Cd1Tshizuebrf0c@hotmail.com---7f2b55JRGQgloryx5fo@hotmail.com---qYSZn2J2eHjackalynashxa@hotmail.com---g40KT0c2aAtisaphkgwes@hotmail.com---94c9G550lmbrm3hort@hotmail.com---7wRRzS3PjUemiliel0al@hotmail.com---pXGh4yLZz5nwsmayton@hotmail.com---5DPuVWcw4efaithtyrub@hotmail.com---VzRJlm1nS8lashonda01kou@hotmail.com---01XKYgn2o7ossielukena0x@hotmail.com---i5aW60i51Gclitus8haxe@hotmail.com---11n370pKrxtiav2zk4@hotmail.com---b2PsID8X8Qrokorvinlgy0@hotmail.com---olOR1G3k6Wmariesowardu1@hotmail.com---jMh68mz2A9irvinglgd@hotmail.com---VnqYMuc2Jcdelorawwuhusch@hotmail.com---GrGhPP830lbeckisatowpkm@hotmail.com---7Rsc5K8lz6samanthamilc3@hotmail.com---jZ71fWSMW9asavagells@hotmail.com---xfxbFQFfX8danaeju2kaut@hotmail.com---yQlw96OaeKtanalb4br@hotmail.com---d7d7GiWxsgarlinda8r0g@hotmail.com---WLk1COUGStkatelynsz6y@hotmail.com---99vYa3hienaileenyditiw@hotmail.com---O8ySz2TT79kittyapoch5q@hotmail.com---1kb8MbO5m9andyvenz1d@hotmail.com---oA99Pqq9I3lakiamcmnwuh@hotmail.com---QPytS87q0imandaekins3wd@hotmail.com---Hd89v6nU05arianne5t40kup@hotmail.com---ehMtR379iwmaryannasgu@hotmail.com---3uyZmI118Xkathec873@hotmail.com---2yQ9qy7n19inesllva@hotmail.com---3bkkLA05d6geritc9jz@hotmail.com----I1wfh8rS61jerrybergock4i@hotmail.com----BJ5KJQ0DlKcamillavvlgri@hotmail.com---3AKOLwANcDlucreciat2est@hotmail.com---yBJ60bP54Scharissauptrdu@hotmail.com---p2YF90AH9Fclfultz37vi@hotmail.com---CC26qH3V0Ujasmyny8so@hotmail.com---YPP188M965lasfacioqbj@hotmail.com---F0z8cd090Sarnoldhwx9s@hotmail.com---13GcrRSLRypercivalwilsm@hotmail.com----RT25f10uKvnievesfavors9cb@hotmail.com----3mVRN6YmgNeugeniev552@hotmail.com----4w95MnvIvcayakonewuyo@hotmail.com----q8UCd2lST4ludmillasteb9@hotmail.com----7sb54Oii8Ichr89kuchto@hotmail.com----Cea7IQj5udemil03mk@hotmail.com----ENC82hip2Alydiavn9ktutoky@hotmail.com-----6351VsZz25tulagj3@hotmail.com----Wx99eCqer7prue56zjehle@hotmail.com----8398k84X85volodya.suslov.2024@mail.ru----N01LRY2umaks.koshkin.2024@mail.ru----z5P2A9QEYXvityusha.popov.2024@mail.ru----l1kcBRj9P4aslanov----2024@mail.rumitya.suvorov.1994@mail.ru----eDhyUmEcY3maksim.naumov.2024@mail.ru----FnD8LI6Oyoleg_baranov_2024@mail.ru----307ih4Rnpfeliks.kalashnikov.89@mail.ru----rfTY6DI9FZvladik.golofast@mail.ru----7w0tOWRjTYtima.nikiforov.2024@mail.ru----TJILFvyddima.safronov.2024@mail.ru----pHX27cN0strakhov.2024@mail.ru----BWYw3fvOGppetr.titov.2003@mail.ru----unxkfIbBRLtosha.kornev.2024@mail.ru----hzY9qQlevladimir.goncharov.2024@mail.ru----ZdW14pDJazamat.stepanov.06@mail.ru----vyQK6LjWvakhrushev_2024@mail.ru----Fs0P87e6xsannikov_2024@mail.ru----Ml2ITAdJvanyusha.ushakov.2005@mail.ru----pFfLHt6sIzilyukha.fedorov.1995@mail.ru----lMS6bNBfpmisha.kulikov.2024@mail.ru----w0n1ciFHsasha.anokhin.2024@mail.ru----pKzjMcUYTbaturin.2024@mail.ru----lc3XgDFsA6khaziyev2024@mail.ru----8EhRtZUnPepavel.denisov.2024@mail.ru----npVIdoMyNvovochka.shklyayev@mail.ru----YMdjyP2gwsashuta.kulikov.2024@mail.ru----d9mNk3o2Rshestopalov.2024@mail.ru----QC0TyBFYeduard.vinokurov.2024@mail.ru----RKmY6dkWFeolezhka.litvinov.2024@mail.ru----a72QBPKhFkotov_aleksandr_1980_15_6@mail.ru----g5GWDcmk{/card-list-item}{/card-list}ChatGPT是一个神奇的东西,它在整个互联网上造成的轰动效应。从去年11月发布至今,可谓是火得一塌糊涂,立即成为了年轻人追求膜拜的对象。相信后面对人们帮助会更多。
-
网页跳转 介绍 更换域名,为了让老站的流量转过来,所以做了一个跳转的代码,非常简洁明了。下面是食用方法,直接将代码直接保存为index.html,修改网址就可以了。代码 <html lang="en"> <head> <meta charset="UTF-8"> <title>5秒后跳转到另一个页面</title> </head> <script> var t = 5; var s = '.'; timeID=setInterval("countDown()",1000); function countDown(){ time.innerHTML= t +"秒后跳转"+s; t--; s+='.'; if (t==0) { location.href="http://521r.cn/";; //跳转目标网址 clearInterval(timeID); } } </script> <body> <div><font ID="time" face="impact" color="#272822" size="7">即将跳转</font> </div> </body> </html>
-
Python批量爬取抖音主页视频 介绍{card-describe title=" "} 这个比之前的比较方便,输入主页链接即可自动爬取主页全部视频。👀 然后这个使用了 selenium模块,这个模块使用比较麻烦,配置的东西也比较多,我尽量写清楚{/card-describe}{lamp/}保存路径修改保存路径自己在这里修改 模块导入所需模块: {card-default label="模块:selenium==3.141.0" width=""}模块:requests{/card-default}cmd 复制输入下面安装命令回车: {card-list}{card-list-item}pip install -i https://pypi.doubanio.com/simple/ selenium==3.141.0pip install -i https://pypi.doubanio.com/simple/ requests{/card-list-item}{/card-list}浏览器驱动使用的是谷歌浏览器,查看你自己的浏览器版本,下载对应的驱动器,驱动器链接:https://registry.npmmirror.com/binary.html?path=chromedriver{collapse}{collapse-item label="驱动配置设置" open}查看这里跟你差不多的版本,我选择的是下面的版本然后下载这个win谷歌浏览器驱动,解压之后把这个chromedriver.exe放在python解释器同级目录python同级目录,然后复制这个chromedriver.exe位置链接,放在下面代码路径进行了这里填你的绝对路径,不填会报错这里获取链接{/collapse-item}{/collapse}效果代码import re import requests import time import os from selenium import webdriver #引用模块 selenium==3.141.0 data_url = input('输入你要爬取抖音博主主页链接') driver= webdriver.Chrome(r'D:\python\chromedriver.exe') # 引用chromedriver.exe程序,填你自己的路径 driver.get(f'{data_url}') def drop_down(): for x in range(1, 30, 4): time.sleep(2) #延时 j = x / 9 js = 'document.documentElement.scrollTop=document.documentElement.scrollHeight * %f'%j #下滑 driver.execute_script(js) drop_down() lis = driver.find_elements_by_css_selector('.Eie04v01') #selenium取值 if not os.path.exists('D:/video/'): os.mkdir(('D:/video/')) for li in lis: try: url = li.find_element_by_css_selector('a').get_attribute('href') #下面路径 print(url) headers ={ 'cookie': 'douyin.com; ttwid=1%7CWi46JI7KdSaF9yqta1kL28XUbEiDv91IIfMOxY-EhZ0%7C1675841330%7C89a9430cc447d8576d53d4fbc9546dfa417bc4e88d586762cbe878514cc1df57; passport_csrf_token=9d7dab91f7a045a68d9fa2deb1f60b0c; passport_csrf_token_default=9d7dab91f7a045a68d9fa2deb1f60b0c; s_v_web_id=verify_ldvcnlvk_10t9slUd_4n0m_42o1_8p9b_8ZRx0cAV4nv5; home_can_add_dy_2_desktop=%220%22; xgplayer_user_id=646767496422; passport_assist_user=CkGmgQ_jszMN1m-PPWYjH_QNdsf_8klBB_8wS0bJsZWcfTnMc97HC73w9WNOnHbLoE1PnrcXtGsuQy6FV7HUCWBMZhpICjxihoJBypQ-JpI9KH--ZN_-TY41fsc-wLsvlbmXM97JsrDcbP2eTP44_kJCdfLHGFu-6P8ZZJ6MfHQMHRAQsrKpDRiJr9ZUIgEDDUbOBg%3D%3D; n_mh=1a3e5XCqMARKIH9Y88jP23zsLolfuhxxp5ZQomXRvOY; sso_uid_tt=c2f6884d45856a3a866e96b167c36a10; sso_uid_tt_ss=c2f6884d45856a3a866e96b167c36a10; toutiao_sso_user=ab04894ee6c7df3eeecec15922d832ea; toutiao_sso_user_ss=ab04894ee6c7df3eeecec15922d832ea; sid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; ssid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; odin_tt=fc686e88a993cd8b3c475705e2e286b79bea48c0f1571b1d71907cb4bc263bd8e81c55f29d0d2d82e6f2f828e0f9322ffc9a0c11a8d50f931542468903f614d5; passport_auth_status=f7cba991b8c1ae560c1f55df240d23f4%2C; passport_auth_status_ss=f7cba991b8c1ae560c1f55df240d23f4%2C; uid_tt=4b64917790b6f7fa2f4452c2c2322ae0; uid_tt_ss=4b64917790b6f7fa2f4452c2c2322ae0; sid_tt=052095ac92e67fd17382c560a00588f4; sessionid=052095ac92e67fd17382c560a00588f4; sessionid_ss=052095ac92e67fd17382c560a00588f4; sid_guard=052095ac92e67fd17382c560a00588f4%7C1676475573%7C5183995%7CSun%2C+16-Apr-2023+15%3A39%3A28+GMT; sid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; ssid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; LOGIN_STATUS=1; store-region=cn-hn; store-region-src=uid; douyin.com; strategyABtestKey=%221677080469.918%22; bd_ticket_guard_client_data=eyJiZC10aWNrZXQtZ3VhcmQtdmVyc2lvbiI6MiwiYmQtdGlja2V0LWd1YXJkLWNsaWVudC1jZXJ0IjoiLS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tXG5NSUlDRkRDQ0FicWdBd0lCQWdJVVpoK2V0RUhDZlB4SjBJUnhGMFFKcGhhRXVjMHdDZ1lJS29aSXpqMEVBd0l3XG5NVEVMTUFrR0ExVUVCaE1DUTA0eElqQWdCZ05WQkFNTUdYUnBZMnRsZEY5bmRXRnlaRjlqWVY5bFkyUnpZVjh5XG5OVFl3SGhjTk1qTXdNakUxTVRVek9UTXdXaGNOTXpNd01qRTFNak16T1RNd1dqQW5NUXN3Q1FZRFZRUUdFd0pEXG5UakVZTUJZR0ExVUVBd3dQWW1SZmRHbGphMlYwWDJkMVlYSmtNRmt3RXdZSEtvWkl6ajBDQVFZSUtvWkl6ajBEXG5BUWNEUWdBRUpHUW1kaWNMU1hHQXl4QzE2ZlplVFNhdXpqNjI4T3o2RUYydTJaaG1HUTh0NnRCS1BZZjRGSnkrXG52S3ZEWTBTNExwMHg4T2NXSnpHM1p0bHdvcnV3SXFPQnVUQ0J0akFPQmdOVkhROEJBZjhFQkFNQ0JhQXdNUVlEXG5WUjBsQkNvd0tBWUlLd1lCQlFVSEF3RUdDQ3NHQVFVRkJ3TUNCZ2dyQmdFRkJRY0RBd1lJS3dZQkJRVUhBd1F3XG5LUVlEVlIwT0JDSUVJTGkxVmVSK01UVElWQ3NEMzQ4ZitCNDBwYkNxUTZvaVBvbGIyQ0c4ckxKbU1Dc0dBMVVkXG5Jd1FrTUNLQUlES2xaK3FPWkVnU2pjeE9UVUI3Y3hTYlIyMVRlcVRSZ05kNWxKZDdJa2VETUJrR0ExVWRFUVFTXG5NQkNDRG5kM2R5NWtiM1Y1YVc0dVkyOXRNQW9HQ0NxR1NNNDlCQU1DQTBnQU1FVUNJUUNtS3MwTktNZ1BUaVdiXG4wRzdNN2s0K2ZOckNIRmRMc0FCVmErUnpwWUZBR1FJZ0E4czE4dS95MHZKOEd0YVlGVjNHQzdTVXJ3bTdITVZBXG5XTkV0ZTVTUkw3cz1cbi0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS1cbiJ9; csrf_session_id=a20f3074e912cd7499eb53ecdc4db1a9; _tea_utm_cache_1243=undefined; MONITOR_WEB_ID=0d0f5307-22e5-4da5-9733-509ce9a07bff; __ac_nonce=063f637ba00a0a8d51802; __ac_signature=_02B4Z6wo00f017RWXlgAAIDDNFSkGepfEH-0dlrAAI7sBLimHJxVv1T5BysGBkNlcpvr3LeKyLCmY4XZwDrZ0jqSxokT6IUn7HfSFn.hlK-QNAZuu532oIbDVIs0LIs4.MYYg6YpRUbfLUFk66; VIDEO_FILTER_MEMO_SELECT=%7B%22expireTime%22%3A1677685307532%2C%22type%22%3A1%7D; tt_scid=77Cu9dRAW7f0mFfa6zzUUQROFT8L1BR0CaDGGuTexi1Q8PTvg7FzDpvupBEHERJq5644; download_guide=%221%2F20230222%22; FOLLOW_LIVE_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F0%2F1677081445546%22; FOLLOW_NUMBER_YELLOW_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F1677080845546%2F0%22; msToken=1KOGSu7iKfb2VJQJ89TVgUWYYeX3eXGQof9T1ZSz027OKe8TVsgg_okULDbFjWGCq6MUnIo-5aUW6cgPiYGVHZQy1xSFwiE5HoBgl5gh5PrLoGvRpTmtGdJ3hU9-StVk; msToken=FbYQeqlbqNPVPa6dRII68yh3bHHd67y1lWGYIVDyOlYcydKxzxSC80eRqQR2bC_P4W75pjmlT3eZSD2gMMXYmpvA5KweN62l-c_nq7O0iSO6yo0e_KhyglwRWCwESIM=; passport_fe_beating_status=false', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.190.400 QQBrowser/11.5.5240.400' } # url = 'https://www.douyin.com/video/6950985129997126952' #测试url response = requests.get(url=url,headers=headers) response.encoding = 'utf-8' title = re.findall('<title data-react-helmet="true">(.*?)</title>',response.text)[0] video_title =re.sub('[#@。“”&\- 抖音]','',title) #re取视频标题 data = re.findall('playApi(.*?)playAddrH265',response.text)[0] #取加密url data_url =requests.utils.unquote(data).replace('","','').replace('":"','https:') #解密 print(video_title,data_url) #打印输出标题跟url video_url = requests.get(url=data_url,headers=headers).content with open('D:/video/'+video_title+'.mp4',mode='wb')as f: #文件保存 路径,可自己修改 f.write(video_url) except Exception as e: print(e)
-
-
-
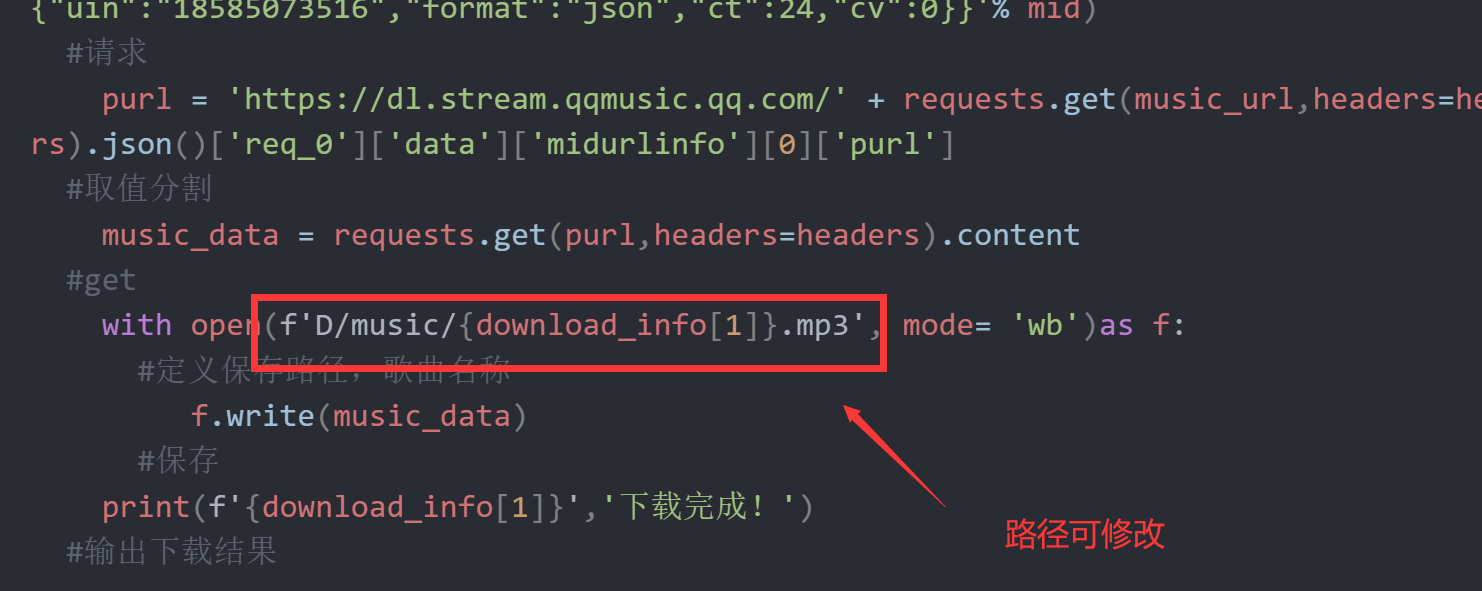
Python爬取QQVIP音乐 介绍 这几天都在研究爬虫,然后捣鼓一下午写好了这个,可以爬取QQ付费音乐 :@(赞一个) (技术有限,只能爬取部分) 有个bug,cookei过期,好像就用不了了{dotted startColor="#ff6c6c" endColor="#1989fa"/}PS:需要导入两个模块{card-describe title="引用模块"} requests prettytable as pt 需在D盘新建music文件夹,不然报错,也可以自定义修改保存路径 {dotted startColor="#ff6c6c" endColor="#1989fa"/}快速导入模块方法如下:win+r 输入cmd在cmd里面分别复制粘贴回车进行了pip install -i https://pypi.doubanio.com/simple/ requestspip install -i https://pypi.doubanio.com/simple/ prettytable{/card-describe}效果代码 import requests import prettytable as pt #一个格式输出的模块 geshou = input('请输入你想要下载的歌手或者歌曲名:') #输入歌手名字 url = f'http://u.y.qq.com/cgi-bin/musicu.fcg?data=%7B%22comm%22:%7B%22ct%22:%2219%22,%22cv%22:%221882%22,%22uin%22:%220%22%7D,%22searchMusic%22:%7B%22method%22:%22DoSearchForQQMusicDesktop%22,%22module%22:%22music.search.SearchCgiService%22,%22param%22:%7B%22grp%22:1,%22num_per_page%22:30,%22page_num%22:1,%22query%22:%22%7B{geshou}%7D%22,%22search_type%22:0%7D%7D%7D%0A' #f可打印输出 data = requests.get(url).json() #获取url json zhi = data['searchMusic']['data']['body']['zhida']['list'][0] #json取值 song = zhi['track_list']['items'] tb = pt.PrettyTable() #打印表格 tb.field_names = ['序号','歌名','状态'] #打印表格 music_info_list = [] numbers = 0 #定义歌曲序号 for list in song: #for循环 id = list['mid'] #取歌曲id name = list['name']#取歌曲昵称 zt = '√' # 状态 # print(numbers,name,zt) #测试输出 tb.add_row([numbers,name,zt]) #赋予表格内容 music_info_list.append([id,name,'下载成功']) numbers += 1 print(tb) #输出表格样式 headers = { headers = { 'cookie': 'pgv_pvid=408238320; fqm_pvqid=c12454a0-4580-4d49-b886-2bf22db76a9e; ts_uid=7308117800; RK=mnvFA8P8ep; ptcz=e886f2438004cd93a6548c522422af8d91ee8453d3fb8d0d838fe4e98863764e; euin=oKvsNKElNKEkon**; tmeLoginType=2; pac_uid=1_469979950; iip=0; o_cookie=1469979950; tvfe_boss_uuid=bf2125500525cd30; pgv_info=ssid=s8054603064; _qpsvr_localtk=0.3553167419354355; fqm_sessionid=fbb172c4-1e70-4c71-bed7-a7c049452ae6; ts_refer=i.y.qq.com/; ariaDefaultTheme=undefined; ts_last=y.qq.com/n/ryqq/search; login_type=1; qm_keyst=Q_H_L_5ScLucJrkG-lUI0lfjBuXm5idKRNPJQ5gOi6AQa-45tBhho-xvsERMA; wxopenid=; psrf_qqopenid=413A01BF0479B022D91B709C577DF361; psrf_qqaccess_token=ABFD4D3D17C22695A37D62587674B6EA; psrf_access_token_expiresAt=1684934769; qqmusic_key=Q_H_L_5ScLucJrkG-lUI0lfjBuXm5idKRNPJQ5gOi6AQa-45tBhho-xvsERMA; wxrefresh_token=; psrf_qqunionid=9EB7B4A00E86499307EADADC8B935FD1; qm_keyst=Q_H_L_5ScLucJrkG-lUI0lfjBuXm5idKRNPJQ5gOi6AQa-45tBhho-xvsERMA; uin=1469979950; psrf_musickey_createtime=1677158769; psrf_qqrefresh_token=C4FF1DABB43775D586C194BF1F17934D; wxunionid=', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50' } #模拟请求 } while True: input_index = eval(input("请输入你要下载的歌曲序号(按-1退出):")) #定义输出 if input_index == -1: #输入-1退出输入 break #退出 download_info = music_info_list[input_index] #取歌曲名称 mid = download_info[0] #取歌曲mid music_url = ('https://u.y.qq.com/cgi-bin/musicu.fcg?format=json&data={"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"358840384","songmid":["%s"],"songtype":[0],"uin":"1443481947","loginflag":1,"platform":"20"}},"comm":{"uin":"18585073516","format":"json","ct":24,"cv":0}}'% mid) #请求 purl = 'https://dl.stream.qqmusic.qq.com/' + requests.get(music_url,headers=headers).json()['req_0']['data']['midurlinfo'][0]['purl'] #取值分割 music_data = requests.get(purl,headers=headers).content #get with open(f'D/music/{download_info[1]}.mp3', mode= 'wb')as f: #定义保存路径,歌曲名称 f.write(music_data) #保存 print(f'{download_info[1]}','下载完成!') print(purl) #输出下载结果
-
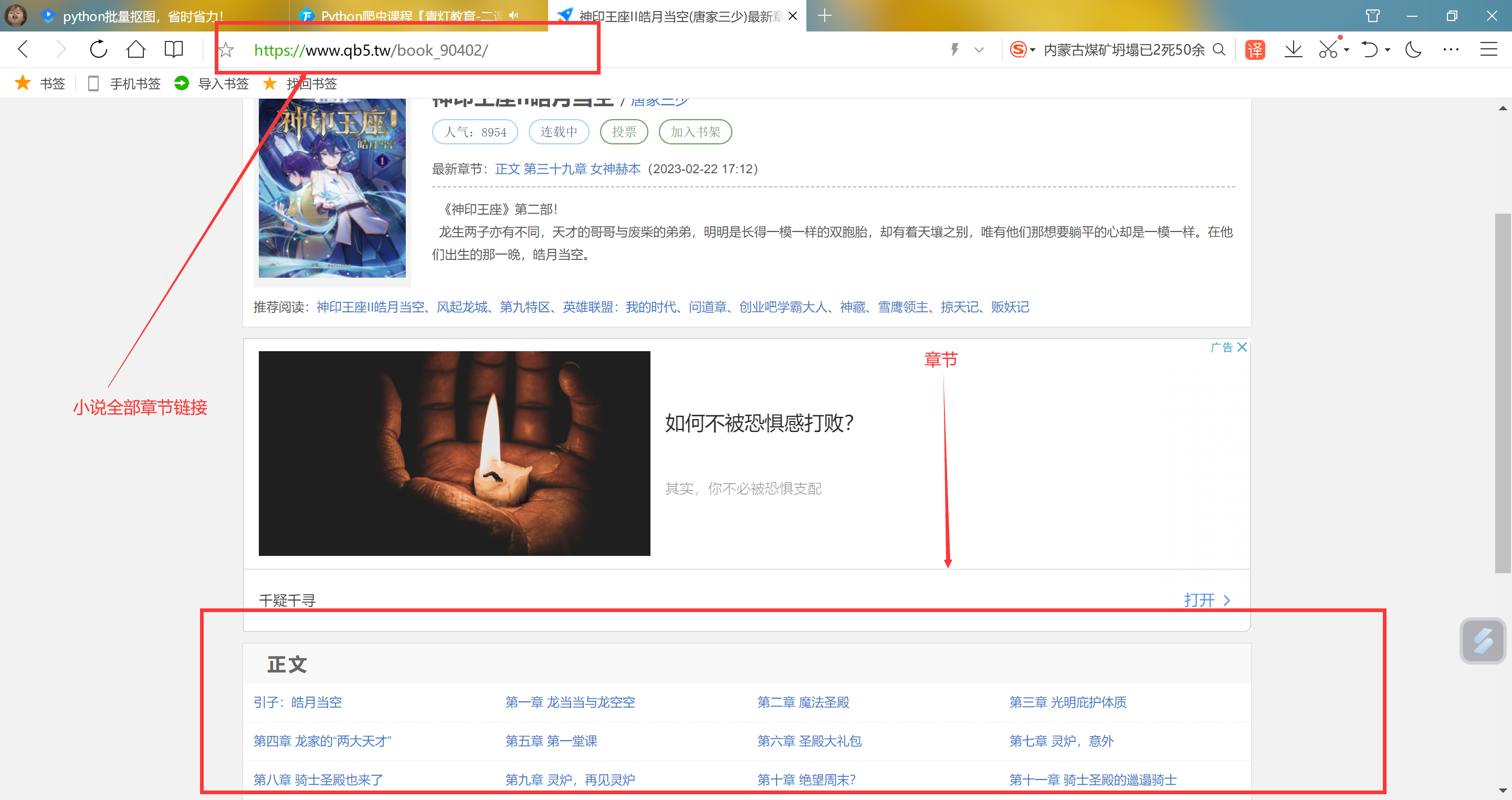
Python爬取网页小说 介绍 小白,懂得不多,随便分享一下自己写的 :@(看热闹) 只写了这个小说站点:https://www.qb5.tw 因为很多网站html标签不一样,我只适配写了这个,如有想要爬取的站点,可以联系我,我试试(尽量,我小白) ::(滑稽)修改 下面代码里面都标注了,你自己看看,不懂的可以联系博主(仅限www.qb5.tw站点章节链接){dotted startColor="#ff6c6c" endColor="#1989fa"/}获取文章链接 如果正则表达式,内容没有替换成功,可以Ctrl+h,一键替换文本里面内容效果 代码""" 我就写了这个站点:www.qb5.tw 那按道理也只能爬这个网站 其他站点没去测试 """ import requests import re novel = input('请输入你想要下载小说链接(仅支持www.qb5.tw):') name = input('请输入你保存小说名字') chapter = novel data = requests.get(chapter).text # 获取网页内容 info_list = re.findall('<dd><a href="(.*?)">(.*?)</a></dd>',data) # re正则表达式,获取链接,小说标题 for info in info_list: # for循环 sub_url = (info[0]) # 取小说url title = (info[1]) # 取小说标题 url = novel + sub_url # 小说链接,需要爬取其他的小说,在这里改一下(就写了这个站点,www.qb5.tw)其他网站没去测试 res = requests.get(url,).text # 取网页内容 text= re.findall('<div id="content">.*?</div>',res)[0] # 正则表达式取小说内容 text = title +'\n\n\n\n'+ text.replace('<div id="nr1"> 全本小说网 www.qb5.tw,最快更新<a href="https://www.qb5.tw/book_116659/">',' ').replace('<div id="content"> 全本小说网 www.qb5.tw,最快更新',' ').replace('&nbs... -->><br><center class="red">本章未完,点击下一页继续阅读</center>',' ').replace('新书上传,希望大家可以先收藏、推荐,正式连载将于5月20号。',' ').replace('本章未完,点击下一页继续阅读</center>',' ').replace(' -->><br><center class="red">','').replace('<br ... -->><br><center class="red">本章未完,点击下一页继续阅读</center>',' ').replace('<div id="nr1"> ','').replace('<br />','\n').replace(' ',' ').replace('每日更新:暂定每天上午10点左右一章、12点左右一章。 </div>',' ').replace(' <br><br>',' ').replace('宇宙职业选手</a>最新章节!<br><br> ','').replace(' ','').replace('</div>',' ').replace('...','\n\n\n\n') # 正则表达式,替换不需要的内容(标签、广告、html标签) # print(text) open(f'{name}.txt',mode='a',encoding='utf-8').write(text) # 写入文件,编码,这里可以自定义文件名字 print('下载成功√'+'\t'+title ) #输出打印
-
网站压力测试工具 介绍 一个网站到底能够承受多大的用户访问量,这应该是很多站长最关心的一个问题,也可以测一测性能,记录一下。 :@(肿包) Apache Bench{card-describe title=" "}Apache Bench 又叫做 AB,是 Apache 附带的一个小工具,专门用于对服务器进行压力测试的。ab 命令会创建很多的并发访问线程,模拟多个访问者同时对某一 URL 进行访问,可用来测试 Apache 的负载压力,也可以测试 nginx、lighthttp、IIS 等其它 Web 服务器的压力{/card-describe}{card-describe title="使用说明"}安装命令:yum install httpd-tools使用命令:ab -n 100 -c 50 https://www.qq.com/// -n 表示:每次请求数,默认不能超过1024个,-c 表示:1个请求的并发连接数,默认最大不能超过 50000// 上面的命令就是模拟 50 个并发连接 每次以 100 个请求数来测试腾讯网站的 Web 性能{/card-describe}Webbench{card-describe title=" "}Webbench 是一个在 linux 下使用的网站测压工具。它使用 fork() 模拟多个客户端同时访问我们设定的 URL,测试网站在压力下工作的性能,最多可以模拟 3万 个并发连接去测试网站的负载能力{/card-describe}{card-describe title="使用说明"}安装命令:wget http://home.tiscali.cz/~cz210552/distfiles/webbench-1.5.tar.gztar zxvf webbench-1.5.tar.gzcd webbench-1.5makemake install使用命令: webbench -c 1000 -t 30 https://www.qq.com/// -c 是并发数,-t 是运行测试时间,即 30 秒钟内中以每次 1000 个请求进行测试// 适用于小型网站压力测试,不适合中大型网站测试,它并发采用多进程实现并非线程,长时间其会大量占用内存与 CPU测试{/card-describe}测试效果 测试的效果如下,没想到 8h8g 的服务器被干倒了。当然,解决的方法也是有的,可以给服务器配置防火墙,拦截此类请求。或者购买 CDN 或 高仿 ip 都可以拦截此类攻击,大家赶快去试试吧 ! {abtn icon="" color="#ff6800" href="https://www.xiaodiblog.cn/" radius="" content="转载XDBLOG"/}
-
-
python爬取网页图片 介绍 这个能爬取一些网页图片,没开https和图片防盗链按道理应该能爬取到的。 也只能适用于一些小网页,小博客,代码也很简单 :@(看热闹) 使用了requests库 还有re正则表达式修改代码url里面内容,即可更换爬取内容# !/user/bin/env python # -*- coding: utf-8 -*- # des: 下载任何网页的图片 import re import requests def download_img(): error_count = 0 success_count = 0 url = input('请输入您要下载的图片的网址:') headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75' } web_text = requests.get(url, headers=headers).text ex = '<img.*?src="(.*?)".*?' img_list = re.findall(ex, web_text) print('图片地址:', img_list) if len(img_list) == 0: print('该网站有反爬虫机制,爬取失败,请换个网站继续尝试。') for img in img_list: try: # 补充协议头 if not (img.startswith('http') or img.startswith('https')): img = 'http:' + img img_binary = requests.get(img, headers=headers).content # 切割出最后一个字符串 file_name = img.split('/')[-1] # 切割 query字符 file_name = file_name.split('?')[0] with open(f'./img/{file_name}'+'.jpg', 'wb') as fp: fp.write(img_binary) print(file_name, ',下载成功') success_count += 1 except Exception as e: print(e) error_count += 1 continue print('下载图片结束!') return success_count, error_count if __name__ == '__main__': success_count, error_count = download_img() print(f'总计下载:{success_count},下载失败:{error_count}')
-
-
宝塔面板挂载数据盘 介绍 相信有很多站长们在购买服务器之后,感觉服务器数据盘有点少,然后这几天都在捣鼓API站点,然后占用了好几个G。 然后闲着没事在宝塔论坛看到一键挂载脚本的方法,可以让你宝塔多出好几十个G ::(你懂的) 我这服务器配置原本只有40G,挂载之后多出59G :@(惊喜)代码CentOS系统挂载命令yum install wget -y && wget -O auto_disk.sh http://blog.i1r.cc/assets/auto_disk.sh && bash auto_disk.shUbuntu系统挂载命令wget -O auto_disk.sh http://blog.i1r.cc/assets/auto_disk.sh && sudo bash auto_disk.sh说明自动挂载脚本说明: 1.默认将数据盘挂载到/www目录2.服务器上已存在/www目录,为了您的数据安全,挂载工具会自动跳过3.服务器之前安装过Windows系统,需要手动删除NTFS分区,挂载工具会直接跳过NTFS分区4.若您的磁盘已分区,且未挂载,工具会自动将分区挂载到/www5.若您的磁盘是新磁盘,工具会自动分区并格式化成ext4文件系统6.本工具只自动挂载一个分区,若您有多块数据盘,请手动挂载未被自动挂载的磁盘7.若要挂载到其它目录,请在第一个参数传入目录名8.只有一个磁盘或www目录已被挂载的情况下,自动退出脚本,不执行任何操作宝塔里面自带一键挂载的程序,可以去商城里面看看,自己一步一步操作比较好挂载之后可能出现后台打不开问题,去修改一下服务器安全组就好了ps:挂载数据盘的时候一定记得备份一下数据,数据无价
-
分享35个可以白嫖的小网站(设计师最爱) 介绍都是免费的白嫖党最爱 ::(滑稽)一、图片1 pixabay:https://pixabay.com/zh/2 Unsplash:https://unsplash.com/3 Pexels:https://www.pexels.com/zh-cn/4 Foodiesfeed :https://www.foodiesfeed.com5 CC零图片网:https://cc0.cn/6 Logo神器:https://www.logosc.cn/so/二、图标1 iconfont:https://www.iconfont.cn/2 iconstore:https://iconstore.co/3 unDraw:https://undraw.co/illustrations4 ICONFINDER:https://www.iconfinder.com/5 ICONS8:https://icons8.com/6 lcon park:https://iconpark.oceanengine.com/official三 、矢量图/免抠PNG/PSD模板1 freepik:https://www.freepik.com/2 free-PSD-templates:https://free-psd-templates.com/3 365psd:https://365psd.com/4 pngimage:http://pngimg.com/5 CLEANPNG:https://www.cleanpng.com/四、 壁纸1 wallhaven:https://wallhaven.cc/2 Wallpaper Abyss:https://wall.alphacoders.com/3 极简壁纸:https://bz.zzzmh.cn/ 五、 视频1 Videezy :https://www.videezy.com/2 Videvo:https://www.videvo.net/3 mixkit:https://mixkit.co/4 distill:https://wedistill.io/六 、音频1 audionautix :https://audionautix.com/2 Freepd:https://freepd.com/3 Freesound:https://freesound.org/4 耳聆网:https://www.ear0.com/5 淘声网:https://www.tosound.com/七、 字体1 字由:https://www.hellofont.cn/2 100font:https://www.100font.com/八、 PPT模板1 OfficePLUS:http://www.officeplus.cn/Template/Home.shtml2 PPT超级市场:http://ppt.sotary.com/web/wxapp/index.html3 51PPT模板:http://www.51pptmoban.com/ppt/4 PPT汇:https://www.ppthui.com/5 优品PPT:http://www.ypppt.com/{message type="success" content="超好的素材网站合集超赞 ! ! !"/}