搜索到
18
篇与
的结果
-
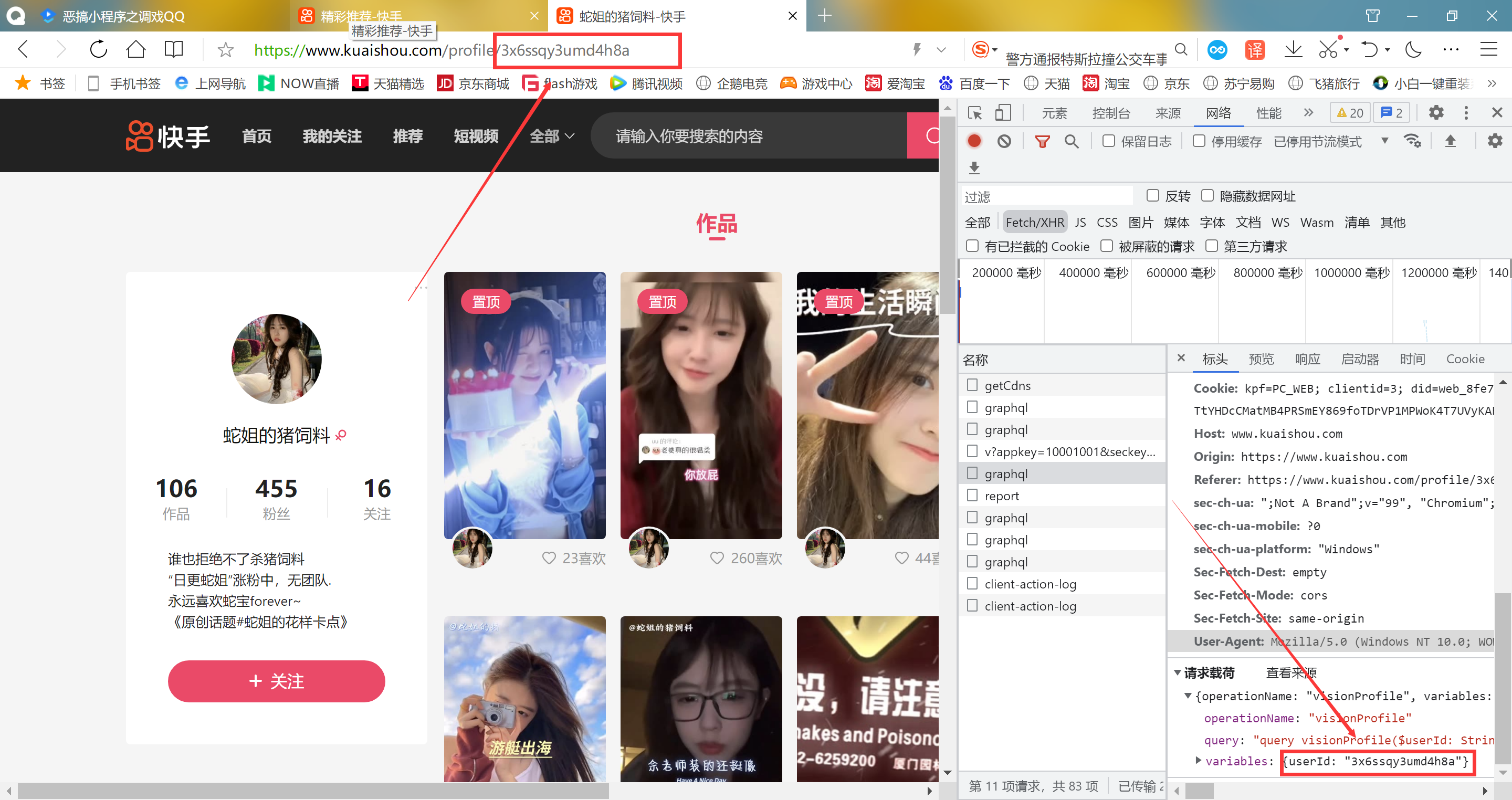
 Python 批量爬取快手点赞视频 前言 好久没有分享爬虫了,随便分享一个之前写的吧,也没看见有人发布这种爬虫,代码也很简单,这个只能批量爬取 自己点赞视频。嗯嗯...是需要抓取cookie的,就是快手喜欢列表cookie,直接看截图:抓包按F12进入开发人员就可以抓了,记得刷新页面才会出现数据包说明 模块自己导入,视频默认保存到D:/video/文件夹,可以自己更改 下面代码自带了cookie,需要更换自己抓包效果代码import requests import re import os cookie ='kpf=PC_WEB; clientid=3; did=web_36aa4b497d25f5a44d48448da60afe50; didv=1687578212131; clientid=3; kpf=PC_WEB; kpn=KUAISHOU_VISION; _did=web_244010593DBE3F9B; ksliveShowClipTip=true; userId=3561544837; kpn=KUAISHOU_VISION; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqAB7j4FNJ3gbkzArjNtSCbdWOMoNmx1qbzusHDTZFf8CLiaBK0j0p7Sy5980HE9Q6WZ1LIU2oMY6zpVG0ETh8k6WOwYNPPKtBNmaPhN92KIHFPL6EPhpd7YKqcbeCopAZVjDsVBohAyZT9oAAtnvlHO4YpC2kitedh_ohGIblSJnrrAtdOvWc1xoEi-RjY0ms0ZD73nxvS3hmz1gJx_Qc7bChoStEyT9S95saEmiR8Dg-bb1DKRIiAId7DYCn2lhOUlYHyKsUDE-ZpLEcSd42tmMjdhGFiBRSgFMAE; kuaishou.server.web_ph=cd2589031aefc1a54981a4d60e57e7033071' ## 这里填你自己的cookie值,自己抓包吧 if not os.path.exists('D:/video/'): os.mkdir(('D:/video/')) ## 这里可修改保存地址 def get_next(pcursor): json = { 'operationName': "visionProfileLikePhotoList", 'query': "fragment photoContent on PhotoEntity {\n id\n duration\n caption\n originCaption\n likeCount\n viewCount\n commentCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n musicBlocked\n __typename\n}\n\nfragment feedContent on Feed {\n type\n author {\n id\n name\n headerUrl\n following\n headerUrls {\n url\n __typename\n }\n __typename\n }\n photo {\n ...photoContent\n __typename\n }\n canAddComment\n llsid\n status\n currentPcursor\n tags {\n type\n name\n __typename\n }\n __typename\n}\n\nquery visionProfileLikePhotoList($pcursor: String, $page: String, $webPageArea: String) {\n visionProfileLikePhotoList(pcursor: $pcursor, page: $page, webPageArea: $webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n ...feedContent\n __typename\n }\n hostName\n pcursor\n __typename\n }\n}\n", 'variables': {"userId": 'id', "pcursor": pcursor, "page": "profile"""} } headers = { 'Cookie': cookie, 'Host': "www.kuaishou.com", 'Origin': "https://www.kuaishou.com", 'Referer': f"https://www.kuaishou.com/profile/{id}", 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.68", } url = 'https://www.kuaishou.com/graphql' response = requests.post(url=url, headers=headers, json=json) json_data = response.json() feeds = json_data['data']['visionProfileLikePhotoList']['feeds'] pcursor = json_data['data']['visionProfileLikePhotoList']['pcursor'] len_num = len(feeds) for feed in range(0, len_num): photoUrl = feeds[feed]['photo']['photoUrl'] originCaption = feeds[feed]['photo']['originCaption'] originCaption = re.sub('[\\/:*?<>|\\n#@)\》\."\《(\r]', '', originCaption) print(originCaption, photoUrl) with open(f'D:/video/{originCaption}''.mp4',mode='wb')as f: video = requests.get(photoUrl).content f.write(video) if pcursor=='no_more': return '' get_next(pcursor) get_next("")
Python 批量爬取快手点赞视频 前言 好久没有分享爬虫了,随便分享一个之前写的吧,也没看见有人发布这种爬虫,代码也很简单,这个只能批量爬取 自己点赞视频。嗯嗯...是需要抓取cookie的,就是快手喜欢列表cookie,直接看截图:抓包按F12进入开发人员就可以抓了,记得刷新页面才会出现数据包说明 模块自己导入,视频默认保存到D:/video/文件夹,可以自己更改 下面代码自带了cookie,需要更换自己抓包效果代码import requests import re import os cookie ='kpf=PC_WEB; clientid=3; did=web_36aa4b497d25f5a44d48448da60afe50; didv=1687578212131; clientid=3; kpf=PC_WEB; kpn=KUAISHOU_VISION; _did=web_244010593DBE3F9B; ksliveShowClipTip=true; userId=3561544837; kpn=KUAISHOU_VISION; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqAB7j4FNJ3gbkzArjNtSCbdWOMoNmx1qbzusHDTZFf8CLiaBK0j0p7Sy5980HE9Q6WZ1LIU2oMY6zpVG0ETh8k6WOwYNPPKtBNmaPhN92KIHFPL6EPhpd7YKqcbeCopAZVjDsVBohAyZT9oAAtnvlHO4YpC2kitedh_ohGIblSJnrrAtdOvWc1xoEi-RjY0ms0ZD73nxvS3hmz1gJx_Qc7bChoStEyT9S95saEmiR8Dg-bb1DKRIiAId7DYCn2lhOUlYHyKsUDE-ZpLEcSd42tmMjdhGFiBRSgFMAE; kuaishou.server.web_ph=cd2589031aefc1a54981a4d60e57e7033071' ## 这里填你自己的cookie值,自己抓包吧 if not os.path.exists('D:/video/'): os.mkdir(('D:/video/')) ## 这里可修改保存地址 def get_next(pcursor): json = { 'operationName': "visionProfileLikePhotoList", 'query': "fragment photoContent on PhotoEntity {\n id\n duration\n caption\n originCaption\n likeCount\n viewCount\n commentCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n musicBlocked\n __typename\n}\n\nfragment feedContent on Feed {\n type\n author {\n id\n name\n headerUrl\n following\n headerUrls {\n url\n __typename\n }\n __typename\n }\n photo {\n ...photoContent\n __typename\n }\n canAddComment\n llsid\n status\n currentPcursor\n tags {\n type\n name\n __typename\n }\n __typename\n}\n\nquery visionProfileLikePhotoList($pcursor: String, $page: String, $webPageArea: String) {\n visionProfileLikePhotoList(pcursor: $pcursor, page: $page, webPageArea: $webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n ...feedContent\n __typename\n }\n hostName\n pcursor\n __typename\n }\n}\n", 'variables': {"userId": 'id', "pcursor": pcursor, "page": "profile"""} } headers = { 'Cookie': cookie, 'Host': "www.kuaishou.com", 'Origin': "https://www.kuaishou.com", 'Referer': f"https://www.kuaishou.com/profile/{id}", 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.68", } url = 'https://www.kuaishou.com/graphql' response = requests.post(url=url, headers=headers, json=json) json_data = response.json() feeds = json_data['data']['visionProfileLikePhotoList']['feeds'] pcursor = json_data['data']['visionProfileLikePhotoList']['pcursor'] len_num = len(feeds) for feed in range(0, len_num): photoUrl = feeds[feed]['photo']['photoUrl'] originCaption = feeds[feed]['photo']['originCaption'] originCaption = re.sub('[\\/:*?<>|\\n#@)\》\."\《(\r]', '', originCaption) print(originCaption, photoUrl) with open(f'D:/video/{originCaption}''.mp4',mode='wb')as f: video = requests.get(photoUrl).content f.write(video) if pcursor=='no_more': return '' get_next(pcursor) get_next("") -
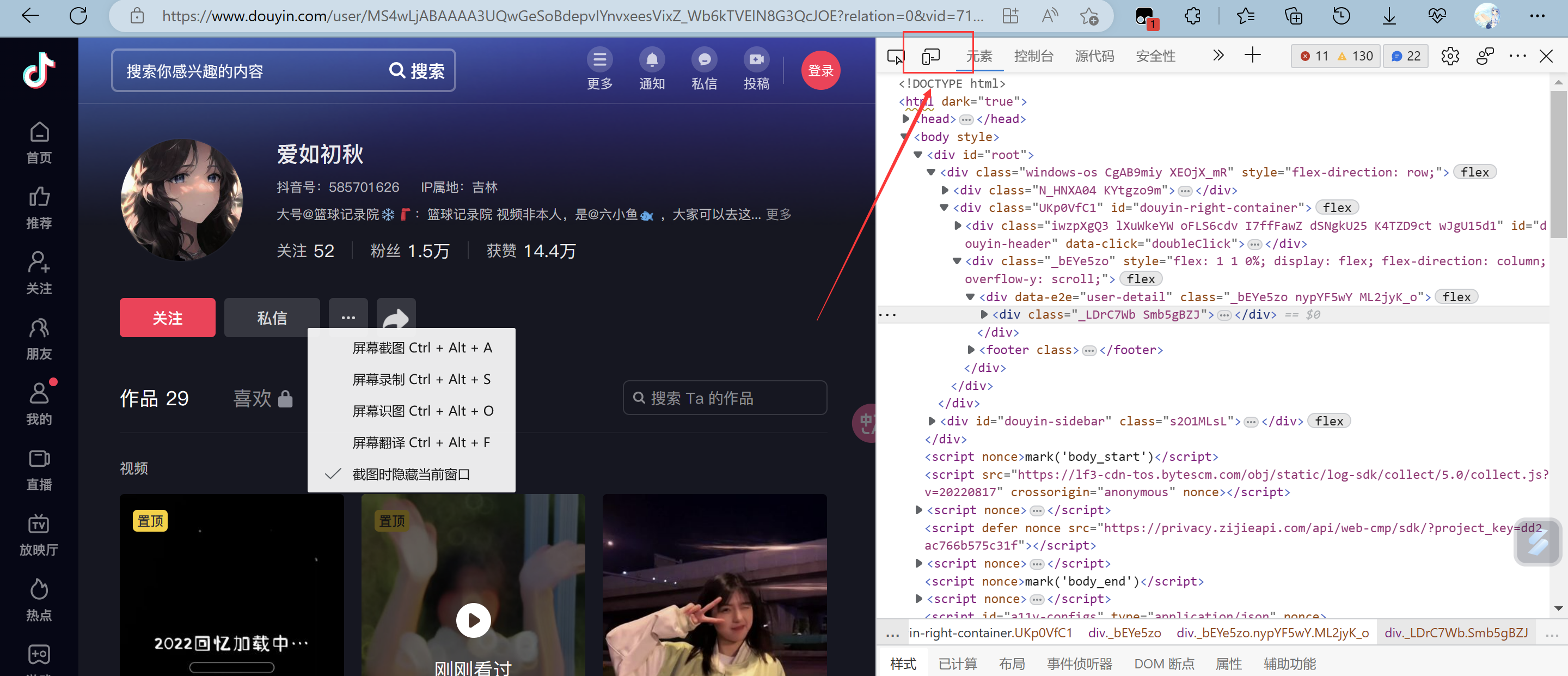
Python批量爬取抖音图集 【失效】 介绍 自己捣鼓几个小时写的,我百度搜了,也没什么爬取抖音图集的爬虫,然后就自己写了,此贴只是分享学习心得跟笔记,切勿使用爬虫做违法违规的事情 :@(尴尬) 搞不懂cookie值,跟请求链接是怎么生成的,写完成功一天,就失效了 :@(口水) 无语死了食用方法 使用requests跟selenium模块,操作很麻烦,selenium使用的是3.141.0版本的 :@(内伤) 然后下载好的浏览器驱动要放在python解释器同级目录,然后复制这个目录,在代码33行修改{card-default label="操作比较复杂(真的很复杂) " width=""}首先导入需要的库 requests、selenium==3.141.0下载对应谷歌浏览器驱动包,可以查看之前的 爬取抖音主页设置好浏览器驱动路径,在代码33行 cookie值抓取,需要自己抓取TEST_JSON链接里面的cookie值 点击这个链接,然后跳转浏览器,里面是json内容,按f12进入开发人员 复制好cookie值 粘贴上去就好了{/card-default}操作方法 模块下载跟浏览器驱动下载,{tabs}{tabs-pane label="requests模块导入"}win+r,输入cmd,在命令行输入下面导入命令指令:pip install requests或pip install -i https://pypi.doubanio.com/simple/ requests{/tabs-pane}{tabs-pane label="selenium模块导入"}指令:pip install -i https://pypi.doubanio.com/simple/ selenium==3.141.0{/tabs-pane}{tabs-pane label="谷歌浏览器驱动"}使用的是谷歌浏览器,查看你自己的浏览器版本,下载对应的驱动器,驱动器链接:https://registry.npmmirror.com/binary.html?path=chromedriver查看这里跟你差不多的版本,我选择的是下面的版本然后下载这个win谷歌浏览器驱动,解压之后把这个chromedriver.exe放在python解释器同级目录python同级目录,然后复制这个chromedriver.exe位置链接,放在下面代码路径进行了这里填你的绝对路径,不填会报错{/tabs-pane}{/tabs}效果{card-list}{card-list-item}{/card-list-item}{/card-list}代码""" 只能爬取图集。。 不懂的可以联系1469979950 """ import re import requests import time import os from selenium import webdriver #引用模块 selenium==3.141.0 try: data_url = input('输入你要爬取的主页链接(仅爬取图集)>>>') cookie =input('输入cookie值(\033[36m第一次爬取可乱输入,按下面提示输入cookie值\033[0m)>>>') headers = { 'cookie': 'douyin.com; ttwid=1%7CWi46JI7KdSaF9yqta1kL28XUbEiDv91IIfMOxY-EhZ0%7C1675841330%7C89a9430cc447d8576d53d4fbc9546dfa417bc4e88d586762cbe878514cc1df57; passport_csrf_token=9d7dab91f7a045a68d9fa2deb1f60b0c; passport_csrf_token_default=9d7dab91f7a045a68d9fa2deb1f60b0c; s_v_web_id=verify_ldvcnlvk_10t9slUd_4n0m_42o1_8p9b_8ZRx0cAV4nv5; home_can_add_dy_2_desktop=%220%22; xgplayer_user_id=646767496422; passport_assist_user=CkGmgQ_jszMN1m-PPWYjH_QNdsf_8klBB_8wS0bJsZWcfTnMc97HC73w9WNOnHbLoE1PnrcXtGsuQy6FV7HUCWBMZhpICjxihoJBypQ-JpI9KH--ZN_-TY41fsc-wLsvlbmXM97JsrDcbP2eTP44_kJCdfLHGFu-6P8ZZJ6MfHQMHRAQsrKpDRiJr9ZUIgEDDUbOBg%3D%3D; n_mh=1a3e5XCqMARKIH9Y88jP23zsLolfuhxxp5ZQomXRvOY; sso_uid_tt=c2f6884d45856a3a866e96b167c36a10; sso_uid_tt_ss=c2f6884d45856a3a866e96b167c36a10; toutiao_sso_user=ab04894ee6c7df3eeecec15922d832ea; toutiao_sso_user_ss=ab04894ee6c7df3eeecec15922d832ea; sid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; ssid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; odin_tt=fc686e88a993cd8b3c475705e2e286b79bea48c0f1571b1d71907cb4bc263bd8e81c55f29d0d2d82e6f2f828e0f9322ffc9a0c11a8d50f931542468903f614d5; passport_auth_status=f7cba991b8c1ae560c1f55df240d23f4%2C; passport_auth_status_ss=f7cba991b8c1ae560c1f55df240d23f4%2C; uid_tt=4b64917790b6f7fa2f4452c2c2322ae0; uid_tt_ss=4b64917790b6f7fa2f4452c2c2322ae0; sid_tt=052095ac92e67fd17382c560a00588f4; sessionid=052095ac92e67fd17382c560a00588f4; sessionid_ss=052095ac92e67fd17382c560a00588f4; sid_guard=052095ac92e67fd17382c560a00588f4%7C1676475573%7C5183995%7CSun%2C+16-Apr-2023+15%3A39%3A28+GMT; sid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; ssid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; LOGIN_STATUS=1; store-region=cn-hn; store-region-src=uid; douyin.com; strategyABtestKey=%221677080469.918%22; bd_ticket_guard_client_data=eyJiZC10aWNrZXQtZ3VhcmQtdmVyc2lvbiI6MiwiYmQtdGlja2V0LWd1YXJkLWNsaWVudC1jZXJ0IjoiLS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tXG5NSUlDRkRDQ0FicWdBd0lCQWdJVVpoK2V0RUhDZlB4SjBJUnhGMFFKcGhhRXVjMHdDZ1lJS29aSXpqMEVBd0l3XG5NVEVMTUFrR0ExVUVCaE1DUTA0eElqQWdCZ05WQkFNTUdYUnBZMnRsZEY5bmRXRnlaRjlqWVY5bFkyUnpZVjh5XG5OVFl3SGhjTk1qTXdNakUxTVRVek9UTXdXaGNOTXpNd01qRTFNak16T1RNd1dqQW5NUXN3Q1FZRFZRUUdFd0pEXG5UakVZTUJZR0ExVUVBd3dQWW1SZmRHbGphMlYwWDJkMVlYSmtNRmt3RXdZSEtvWkl6ajBDQVFZSUtvWkl6ajBEXG5BUWNEUWdBRUpHUW1kaWNMU1hHQXl4QzE2ZlplVFNhdXpqNjI4T3o2RUYydTJaaG1HUTh0NnRCS1BZZjRGSnkrXG52S3ZEWTBTNExwMHg4T2NXSnpHM1p0bHdvcnV3SXFPQnVUQ0J0akFPQmdOVkhROEJBZjhFQkFNQ0JhQXdNUVlEXG5WUjBsQkNvd0tBWUlLd1lCQlFVSEF3RUdDQ3NHQVFVRkJ3TUNCZ2dyQmdFRkJRY0RBd1lJS3dZQkJRVUhBd1F3XG5LUVlEVlIwT0JDSUVJTGkxVmVSK01UVElWQ3NEMzQ4ZitCNDBwYkNxUTZvaVBvbGIyQ0c4ckxKbU1Dc0dBMVVkXG5Jd1FrTUNLQUlES2xaK3FPWkVnU2pjeE9UVUI3Y3hTYlIyMVRlcVRSZ05kNWxKZDdJa2VETUJrR0ExVWRFUVFTXG5NQkNDRG5kM2R5NWtiM1Y1YVc0dVkyOXRNQW9HQ0NxR1NNNDlCQU1DQTBnQU1FVUNJUUNtS3MwTktNZ1BUaVdiXG4wRzdNN2s0K2ZOckNIRmRMc0FCVmErUnpwWUZBR1FJZ0E4czE4dS95MHZKOEd0YVlGVjNHQzdTVXJ3bTdITVZBXG5XTkV0ZTVTUkw3cz1cbi0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS1cbiJ9; csrf_session_id=a20f3074e912cd7499eb53ecdc4db1a9; _tea_utm_cache_1243=undefined; MONITOR_WEB_ID=0d0f5307-22e5-4da5-9733-509ce9a07bff; __ac_nonce=063f637ba00a0a8d51802; __ac_signature=_02B4Z6wo00f017RWXlgAAIDDNFSkGepfEH-0dlrAAI7sBLimHJxVv1T5BysGBkNlcpvr3LeKyLCmY4XZwDrZ0jqSxokT6IUn7HfSFn.hlK-QNAZuu532oIbDVIs0LIs4.MYYg6YpRUbfLUFk66; VIDEO_FILTER_MEMO_SELECT=%7B%22expireTime%22%3A1677685307532%2C%22type%22%3A1%7D; tt_scid=77Cu9dRAW7f0mFfa6zzUUQROFT8L1BR0CaDGGuTexi1Q8PTvg7FzDpvupBEHERJq5644; download_guide=%221%2F20230222%22; FOLLOW_LIVE_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F0%2F1677081445546%22; FOLLOW_NUMBER_YELLOW_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F1677080845546%2F0%22; msToken=1KOGSu7iKfb2VJQJ89TVgUWYYeX3eXGQof9T1ZSz027OKe8TVsgg_okULDbFjWGCq6MUnIo-5aUW6cgPiYGVHZQy1xSFwiE5HoBgl5gh5PrLoGvRpTmtGdJ3hU9-StVk; msToken=FbYQeqlbqNPVPa6dRII68yh3bHHd67y1lWGYIVDyOlYcydKxzxSC80eRqQR2bC_P4W75pjmlT3eZSD2gMMXYmpvA5KweN62l-c_nq7O0iSO6yo0e_KhyglwRWCwESIM=; passport_fe_beating_status=false', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.190.400 QQBrowser/11.5.5240.400' }#这个是主页页面请求头 head ={ 'cookie':cookie, 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50' }#这个是json页面请求头 data=requests.get(data_url,headers=headers).text title =re.findall('<title data-react-helmet="true">(.*?) - 抖音</title>',data)[0] #取抖音主页昵称 introduce=re.findall('<meta data-react-helmet="true" name="description" content="(.*?)"/>',data)[0] #取主页简介 zp=re.findall('作品</span><span class="J6IbfgzH" data-e2e="user-tab-count">(.*?)</span>',data)[0] #取作品数 print('\033[34m\n===============================================================') #打印出信息 print('|爬取目标:',title) print('|主页介绍:',introduce) print('|目标主页:',data_url) print('|作品总数:',zp) print('\033[32m|tips:爬取的时候,切勿关闭浏览器,验证也需要自己过,让浏览器自动下滑到底部,不然图集链接获取不到。\033[0m') print('\033[32m|tips:下面遇到报错\033[31mExpecting value: line 1 column 1 (char 0)\033[0m报错,就是cookie失效,需要自己抓取 \n\033[0m') print('\033[31m====================== 程序开始运行。。。===========================\033[0m') except ValueError: print('\033[31m输入链接错误,请输入正确的抖音主页链接\033[0m') exit() driver= webdriver.Chrome(r'D:\python\chromedriver.exe') # 引用chromedriver.exe程序,填你自己谷歌浏览器驱动路径 statr =time.time() #计时 driver.get(f'{data_url}') def drop_down(): for x in range(1, 30, 4): time.sleep(2) #延时 j = x / 9 js = 'document.documentElement.scrollTop=document.documentElement.scrollHeight * %f'%j #下滑 driver.execute_script(js) drop_down() #页面下滑 lis = driver.find_elements_by_css_selector('.Eie04v01') #取标签 #selenium取值 # print(lis) num =1 for li in lis: try: url = li.find_element_by_css_selector('a').get_attribute('href') #取作品页面url #下面路径 print('\n=============正在爬取第', zp, '/', num, '个图集作品=============\n') print('图集内容:',url) url =re.sub('https://www.douyin.com/note/','',url).split() #id拼接 num +=1 for i in url: img_url ='https://www.douyin.com/web/api/v2/aweme/iteminfo/?reflow_source=reflow_page&item_ids='+i print('\nTEST_JSON:>>>>',img_url) #打印输出 json url print('\t\t\t\t\033[32m点击上面链接跳转浏览器,按开发人员抓取cookie值,然后重新运行程序输入cookie值即可\033[0m') data =requests.get(url=img_url,headers=head).json() #请求json页面取值 # print(data) img = data['item_list'][0]['images'] #取图片url name =data['item_list'][0]['desc'] #取图片标题 name =re.sub('[\\/:*?<>|\\n#@)\》/\."\/ /《(\r]','',name) #替换特殊字符 if not os.path.exists(f'D:/image/{name}'): #判断文件夹是否存在 os.mkdir((f'D:/image/{name}')) #不存在则新建 for k,j in enumerate(img): #取值 image =j['url_list'][3] print(name+'_'+str(k),image) data1 =requests.get(url=image,headers=headers).content with open(f'D:/image/{name}/{name}_{k}.jpg',mode='wb')as f: f.write(data1) except Exception as e: #报错跳过执行下一条 print('第',num,'个图集爬取失败!错误内容:\033[31m',e,'\033[0m') #输出报错内容 end =time.time() #计时 print('====================================') print('\n\n爬取完毕!!!') try: print('程序运行时间:',end - statr,'秒') #输出程序运行时间 except Exception as e: print('\n\033[31m览器加载超时或验证错误,请重新再试\033[0m') import re import requests import os headers ={ 'cookie': 'douyin.com; ttwid=1%7CWi46JI7KdSaF9yqta1kL28XUbEiDv91IIfMOxY-EhZ0%7C1675841330%7C89a9430cc447d8576d53d4fbc9546dfa417bc4e88d586762cbe878514cc1df57; passport_csrf_token=9d7dab91f7a045a68d9fa2deb1f60b0c; passport_csrf_token_default=9d7dab91f7a045a68d9fa2deb1f60b0c; s_v_web_id=verify_ldvcnlvk_10t9slUd_4n0m_42o1_8p9b_8ZRx0cAV4nv5; home_can_add_dy_2_desktop=%220%22; xgplayer_user_id=646767496422; passport_assist_user=CkGmgQ_jszMN1m-PPWYjH_QNdsf_8klBB_8wS0bJsZWcfTnMc97HC73w9WNOnHbLoE1PnrcXtGsuQy6FV7HUCWBMZhpICjxihoJBypQ-JpI9KH--ZN_-TY41fsc-wLsvlbmXM97JsrDcbP2eTP44_kJCdfLHGFu-6P8ZZJ6MfHQMHRAQsrKpDRiJr9ZUIgEDDUbOBg%3D%3D; n_mh=1a3e5XCqMARKIH9Y88jP23zsLolfuhxxp5ZQomXRvOY; sso_uid_tt=c2f6884d45856a3a866e96b167c36a10; sso_uid_tt_ss=c2f6884d45856a3a866e96b167c36a10; toutiao_sso_user=ab04894ee6c7df3eeecec15922d832ea; toutiao_sso_user_ss=ab04894ee6c7df3eeecec15922d832ea; sid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; ssid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; odin_tt=fc686e88a993cd8b3c475705e2e286b79bea48c0f1571b1d71907cb4bc263bd8e81c55f29d0d2d82e6f2f828e0f9322ffc9a0c11a8d50f931542468903f614d5; passport_auth_status=f7cba991b8c1ae560c1f55df240d23f4%2C; passport_auth_status_ss=f7cba991b8c1ae560c1f55df240d23f4%2C; uid_tt=4b64917790b6f7fa2f4452c2c2322ae0; uid_tt_ss=4b64917790b6f7fa2f4452c2c2322ae0; sid_tt=052095ac92e67fd17382c560a00588f4; sessionid=052095ac92e67fd17382c560a00588f4; sessionid_ss=052095ac92e67fd17382c560a00588f4; sid_guard=052095ac92e67fd17382c560a00588f4%7C1676475573%7C5183995%7CSun%2C+16-Apr-2023+15%3A39%3A28+GMT; sid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; ssid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; LOGIN_STATUS=1; store-region=cn-hn; store-region-src=uid; douyin.com; strategyABtestKey=%221677080469.918%22; bd_ticket_guard_client_data=eyJiZC10aWNrZXQtZ3VhcmQtdmVyc2lvbiI6MiwiYmQtdGlja2V0LWd1YXJkLWNsaWVudC1jZXJ0IjoiLS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tXG5NSUlDRkRDQ0FicWdBd0lCQWdJVVpoK2V0RUhDZlB4SjBJUnhGMFFKcGhhRXVjMHdDZ1lJS29aSXpqMEVBd0l3XG5NVEVMTUFrR0ExVUVCaE1DUTA0eElqQWdCZ05WQkFNTUdYUnBZMnRsZEY5bmRXRnlaRjlqWVY5bFkyUnpZVjh5XG5OVFl3SGhjTk1qTXdNakUxTVRVek9UTXdXaGNOTXpNd01qRTFNak16T1RNd1dqQW5NUXN3Q1FZRFZRUUdFd0pEXG5UakVZTUJZR0ExVUVBd3dQWW1SZmRHbGphMlYwWDJkMVlYSmtNRmt3RXdZSEtvWkl6ajBDQVFZSUtvWkl6ajBEXG5BUWNEUWdBRUpHUW1kaWNMU1hHQXl4QzE2ZlplVFNhdXpqNjI4T3o2RUYydTJaaG1HUTh0NnRCS1BZZjRGSnkrXG52S3ZEWTBTNExwMHg4T2NXSnpHM1p0bHdvcnV3SXFPQnVUQ0J0akFPQmdOVkhROEJBZjhFQkFNQ0JhQXdNUVlEXG5WUjBsQkNvd0tBWUlLd1lCQlFVSEF3RUdDQ3NHQVFVRkJ3TUNCZ2dyQmdFRkJRY0RBd1lJS3dZQkJRVUhBd1F3XG5LUVlEVlIwT0JDSUVJTGkxVmVSK01UVElWQ3NEMzQ4ZitCNDBwYkNxUTZvaVBvbGIyQ0c4ckxKbU1Dc0dBMVVkXG5Jd1FrTUNLQUlES2xaK3FPWkVnU2pjeE9UVUI3Y3hTYlIyMVRlcVRSZ05kNWxKZDdJa2VETUJrR0ExVWRFUVFTXG5NQkNDRG5kM2R5NWtiM1Y1YVc0dVkyOXRNQW9HQ0NxR1NNNDlCQU1DQTBnQU1FVUNJUUNtS3MwTktNZ1BUaVdiXG4wRzdNN2s0K2ZOckNIRmRMc0FCVmErUnpwWUZBR1FJZ0E4czE4dS95MHZKOEd0YVlGVjNHQzdTVXJ3bTdITVZBXG5XTkV0ZTVTUkw3cz1cbi0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS1cbiJ9; csrf_session_id=a20f3074e912cd7499eb53ecdc4db1a9; _tea_utm_cache_1243=undefined; MONITOR_WEB_ID=0d0f5307-22e5-4da5-9733-509ce9a07bff; __ac_nonce=063f637ba00a0a8d51802; __ac_signature=_02B4Z6wo00f017RWXlgAAIDDNFSkGepfEH-0dlrAAI7sBLimHJxVv1T5BysGBkNlcpvr3LeKyLCmY4XZwDrZ0jqSxokT6IUn7HfSFn.hlK-QNAZuu532oIbDVIs0LIs4.MYYg6YpRUbfLUFk66; VIDEO_FILTER_MEMO_SELECT=%7B%22expireTime%22%3A1677685307532%2C%22type%22%3A1%7D; tt_scid=77Cu9dRAW7f0mFfa6zzUUQROFT8L1BR0CaDGGuTexi1Q8PTvg7FzDpvupBEHERJq5644; download_guide=%221%2F20230222%22; FOLLOW_LIVE_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F0%2F1677081445546%22; FOLLOW_NUMBER_YELLOW_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F1677080845546%2F0%22; msToken=1KOGSu7iKfb2VJQJ89TVgUWYYeX3eXGQof9T1ZSz027OKe8TVsgg_okULDbFjWGCq6MUnIo-5aUW6cgPiYGVHZQy1xSFwiE5HoBgl5gh5PrLoGvRpTmtGdJ3hU9-StVk; msToken=FbYQeqlbqNPVPa6dRII68yh3bHHd67y1lWGYIVDyOlYcydKxzxSC80eRqQR2bC_P4W75pjmlT3eZSD2gMMXYmpvA5KweN62l-c_nq7O0iSO6yo0e_KhyglwRWCwESIM=; passport_fe_beating_status=false', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.190.400 QQBrowser/11.5.5240.400' } # get =input('输入你需要爬取的抖音主页') url = 'https://www.douyin.com/user/MS4wLjABAAAAwN8fRkQsYGvl3T0aF7PRFffd1yM7hDA7DUhNMPMWpaY' data =requests.get(url=url,headers=headers) data.encoding = 'utf-8' # print(data.text) title = re.findall('<p class="__0w4MvO">(.*?)</p>',data.text) img =re.findall('<li class="Eie04v01"><div><a href="//(.*?)" class="B3AsdZT9 chmb2GX8"',data.text) num=1 print(title) for i in img: img_url= 'https://'+i print(img_url) data =requests.get(url=img_url,headers=headers) data.encoding='utf-8' # print(data.text) img_url=re.findall('<div class="qylGvmT4"><img class="V5BLJkWV" src="(.*?)"',data.text) title =re.findall('<h1 class="A_DQnbx8"><span><span class="Nu66P_ba"><span><span><span><span>(.*?)</span></span></span></span></span></span></h1>',data.text) for a,c in enumerate(img_url): images =re.sub('amp;','',c) for b in title: if not os.path.exists(f'D:/image/{b}/'): # 判断文件夹是否存在 os.mkdir((f'D:/image/{b}/')) print(title[0]+f'{a}',images) data1 = requests.get(url=images, headers=headers).content with open(f'D:/image/{b}/{b}_{a}.jpg', mode='wb') as f: f.write(data1) num += 1 笔记 写个笔记 记录一下知识点 :@(长草)time.time()函数time.time() #可用作计时 #例子 statr =time.time() ....... end =time.time() print('程序运行时间:',end - statr,'秒')更换颜色 在Python中,可以使用ANSI控制码来实现在终端输出文本时改变字体颜色。下面是一些常用的ANSI控制码:"\033[0m":重置终端颜色设置。"\033[30m":设置字体颜色为黑色。"\033[31m":设置字体颜色为红色。"\033[32m":设置字体颜色为绿色。"\033[33m":设置字体颜色为黄色。"\033[34m":设置字体颜色为蓝色。"\033[35m":设置字体颜色为紫色。"\033[36m":设置字体颜色为青色。"\033[37m":设置字体颜色为白色。例如,如果要将输出的文本设置为红色,可以使用以下代码:print("\033[31mHello World\033[0m")这将会输出红色的"Hello World"。
-
python爬虫(无聊写的) 介绍 自行测试,代码大部分都是使用re正则表达式取数据。。。代码一import re import requests import os """ 站点:ca789.com 自行测试 """ pages =int(input('输入你要爬取的页数')) types =input("输入你想要爬取的类型(toupai、meitui、oumei、katong)>>>:") if not os.path.exists(f'D:/image/{types}//'): os.mkdir((f'D:/image/{types}//')) num =1 for page in range(1,pages): url =f'https://lca789.com/pic/{types}/index_{page}.html' # 图片类型可选(toupai、meitui、oumei、卡通) print('\n===============正在爬取第',page,'页===============\n\n') print('类型:',types) data =requests.get(url) link =re.findall('<dd><a href="(.*?)" target="_blank"><h3>',data.text) for i in link: html_url ='https://lca789.com/'+i data1 =requests.get(html_url) img_url=re.findall("<img src='(.*?)'><br><br>",data1.text) title =re.findall("<title>(.*?)</title>",data1.text)[0] for i in img_url: i = re.sub("'><br><img src=|'> <br><img src='",'',i) print(title,i) data2 =requests.get(i).content with open(f'D://image//{types}//{num}.jpg',mode='wb')as f: f.write(data2) num +=1 print('\n===============爬取结束===============\n') 代码二import re import requests headers ={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.54', 'cookie': 'yabs-sid=1394784121678716100; is_gdpr=0; is_gdpr_b=CJ6rGBDZqwE=; yandexuid=9617169011678716092; yuidss=9617169011678716092; i=BXtIPJOfVAf3+Y2wHz+oX9kKFt7x2/gt1yiZdaR+c0Q3GvRek5COFcuDb8QD5Sz31xEWBn6wPoEfZqXTHuqsfsGEda4=; yp=1678802891.yu.3878431071678716100; ymex=1681308491.oyu.3878431071678716100#1994076100.yrts.1678716100#1994076100.yrtsi.1678716100', } url ='https://xn---50ppiccom-4s2r687bes0e.www-50ppic.com/?fuli.one' data =requests.get(url=url,headers=headers).text data_url =re.findall('<img src="(.*?)" /></a></div><div class="item">',data) len_num =len(data_url) print('==============共',len_num,'张图片==============') num =1 for i in data_url: print('第',num,'图片下载成功',i) title = i.split('/')[-1] image =requests.get(url=i,headers=headers) with open(f'D:/image/{title}''.jpg', mode='wb') as f: f.write(image.content) num +=1 代码三import re import requests import os pages =int(input('输入你想要爬取的页数>>>:')) if not os.path.exists('D:/text/'): os.mkdir(('D:/text/')) for page in range(1,pages): print('\n============正在爬取第',page,'页============\n') url =f'https://fulizx2.cc/index.php/art/type/id/21/page/{page}.html' data =requests.get(url) html =re.findall('<a href="(.*?)" title="(.*?)" target="_blank">(.*?)</a>',data.text) len_num =len(html) print('此页面共',len_num,'篇小说') for i in html: title= i[1] #取标题 html_url=i[0] #取后缀链接 html_url='https://fulizx2.cc/'+html_url # 网址拼接 print('《'+title+'》','\t',html_url) # 输出打印 标题跟 url data1 = requests.get(html_url) book =re.findall('<book><p>(.*?)</p></book>',data1.text) # re取小说内容 for i in book: text =re.sub('</div>|<br>','\n',i).replace('? ? ',' ') # 字符串替换 # print(text) open(f"D://text//{title}.txt",mode='a',encoding='utf-8').write(text) # 小说标题建文件名 # f.write('\n') 代码四import re import requests for page in range(1,30): url =f'https://m.woyaogexing.com/shouji/index_{page}.html' print('\n=================正在爬取第',page,'页=================\n') data =requests.get(url) data.encoding =data.apparent_encoding html_url =re.findall('<div class="m-img-wrap"><a href="(.*?)"',data.text) for i in html_url: url_html ='https://m.woyaogexing.com'+i # print(url_html) data1 =requests.get(url_html) data1.encoding =data.apparent_encoding img_url=re.findall('<a href="//(.*?)" class="swipebox">',data1.text) for i in img_url: title =re.findall('<h1 class="m-page-title">(.*?)</h1>',data1.text)[0] image ='https://'+i print(title,image) import re import requests for page in range(1,30): url =f'https://m.woyaogexing.com/touxiang/qinglv/index_{page}.html' print('\n=================正在爬取第', page, '页=================\n') data =requests.get(url) data.encoding =data.apparent_encoding html =re.findall('<a class="f-bd-4 f-elips" href="(.*?)" alt="(.*?)">',data.text) for i in html: title =i[1] html_url ='https://m.woyaogexing.com/'+i[0] data2 =requests.get(html_url) data2.encoding =data2.apparent_encoding img_url = re.findall('data-src="//(.*?)"/>',data2.text) for i in img_url: img_url = 'https://' + i print(title,img_url) 俄乌战争局势import re import requests url ='http://app.people.cn/api/v2/subjects/subjectTimelineList?articleId=771&size=20&pageToken=1&_t=1687915057&protocol=false' r =requests.get(url).json() json_data =r['item'] for i in json_data: articleTitle =i['articleTitle'] datePoint =i['datePoint'] datePoint =re.sub('\\+0800','',datePoint) datePoint =datePoint.replace('T',' ') remark =i['remark'] print(datePoint,articleTitle,remark) TESTimport re import requests url ='https://www.sstuku6.xyz/bb58/?shouye' r =requests.get(url).text # print(r) html_url =re.findall(' <h2 class="entry-title"><a href="(.*?)" target="_blank" title=',r) for i in html_url: htm_url ='https://www.sstuku6.xyz'+i rs =requests.get(htm_url).text # print(rs) img_url =re.findall('<img class="lazyload" data-src="(.*?)"',rs) img_title =re.findall('<h1 class="entry-title">(.*?)</h1>',rs)[0] for k in img_url: img =k print(img_title,k)
-
Python批量爬取写真网站 介绍 一个批量爬取写真网站的爬虫,无聊随便写的。代码也非常的简单,随便分享一下吧 :@(无语)站点:http://www.tdz4.com/效果代码import re import os import requests num =1 if not os.path.exists('D:/image/'): os.mkdir(('D:/image/')) pages =int(input('输入你要爬取的页数')) for page in range(0,pages): print(f'\n===========\t正在爬取第{page}页\t===========') url = f"http://www.tdz4.com/whzm/page/{page}" resp = requests.get(url=url) # print(resp.text) data =re.findall('<h2><a href="(.*?)">(.*?)</a></h2>',resp.text) for i in data: name =i[1] img_url=i[0] print(img_url,name) data =requests.get(url=img_url) img_url= re.findall('data-src="(.*?)"> <img',data.text) for a in img_url: print(a) data =requests.get(url=a).content with open(f'D:/image/{name}{num}.jpg',"wb")as f: f.write(data) num +=1 print('\n\n===========\t爬取完毕!!!===========\t') print(f'\n共爬取{num-1}张') 爬取url链接差不多,上面代码是爬取图片下载,下面是爬取图片url然后保存到文本!import re import os import requests num =1 if not os.path.exists('D:/image/'): os.mkdir(('D:/image/')) pages =int(input('输入你要爬取的页数')) for page in range(0,pages): print(f'\n===========\t正在爬取第{page}页\t===========') url = f"http://www.tdz4.com/whzm/page/{page}" resp = requests.get(url=url) # print(resp.text) data =re.findall('<h2><a href="(.*?)">(.*?)</a></h2>',resp.text) for i in data: name =i[1] img_url=i[0] print(img_url,name) data =requests.get(url=img_url) img_url= re.findall('data-src="(.*?)"> <img',data.text) for a in img_url: print(a) data =requests.get(url=a).content with open(f'写真.txt', mode='a', encoding='utf-8', ) as f: # 保存路径,追加写入 f.write(a) f.write('\n') num +=1 print('\n\n===========\t爬取完毕!!!===========\t') print(f'\n共爬取{num-1}张')
-
Python爬取抖音图集(半成品) 介绍 一个爬取抖音图集半成品(该帖只是分享学习心得跟思路我也是小白),写是写好了,但爬取的图片链接打开是403 :@(内伤) ,所以图片保存不了。 我用的方法是re正则获取,按道理应该需要获取url编码之后的数据,我能力不够 :@(尴尬) {card-list}{card-list-item}{/card-list-item}{/card-list}效果思路 我的思路:获取作者主页网页作品跳转a标签,进行拼接,然后访问图集链接,使用re.findall获取图片 (失败)代码import re import requests headers ={ 'cookie': 'douyin.com; ttwid=1%7CWi46JI7KdSaF9yqta1kL28XUbEiDv91IIfMOxY-EhZ0%7C1675841330%7C89a9430cc447d8576d53d4fbc9546dfa417bc4e88d586762cbe878514cc1df57; passport_csrf_token=9d7dab91f7a045a68d9fa2deb1f60b0c; passport_csrf_token_default=9d7dab91f7a045a68d9fa2deb1f60b0c; s_v_web_id=verify_ldvcnlvk_10t9slUd_4n0m_42o1_8p9b_8ZRx0cAV4nv5; home_can_add_dy_2_desktop=%220%22; xgplayer_user_id=646767496422; passport_assist_user=CkGmgQ_jszMN1m-PPWYjH_QNdsf_8klBB_8wS0bJsZWcfTnMc97HC73w9WNOnHbLoE1PnrcXtGsuQy6FV7HUCWBMZhpICjxihoJBypQ-JpI9KH--ZN_-TY41fsc-wLsvlbmXM97JsrDcbP2eTP44_kJCdfLHGFu-6P8ZZJ6MfHQMHRAQsrKpDRiJr9ZUIgEDDUbOBg%3D%3D; n_mh=1a3e5XCqMARKIH9Y88jP23zsLolfuhxxp5ZQomXRvOY; sso_uid_tt=c2f6884d45856a3a866e96b167c36a10; sso_uid_tt_ss=c2f6884d45856a3a866e96b167c36a10; toutiao_sso_user=ab04894ee6c7df3eeecec15922d832ea; toutiao_sso_user_ss=ab04894ee6c7df3eeecec15922d832ea; sid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; ssid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; odin_tt=fc686e88a993cd8b3c475705e2e286b79bea48c0f1571b1d71907cb4bc263bd8e81c55f29d0d2d82e6f2f828e0f9322ffc9a0c11a8d50f931542468903f614d5; passport_auth_status=f7cba991b8c1ae560c1f55df240d23f4%2C; passport_auth_status_ss=f7cba991b8c1ae560c1f55df240d23f4%2C; uid_tt=4b64917790b6f7fa2f4452c2c2322ae0; uid_tt_ss=4b64917790b6f7fa2f4452c2c2322ae0; sid_tt=052095ac92e67fd17382c560a00588f4; sessionid=052095ac92e67fd17382c560a00588f4; sessionid_ss=052095ac92e67fd17382c560a00588f4; sid_guard=052095ac92e67fd17382c560a00588f4%7C1676475573%7C5183995%7CSun%2C+16-Apr-2023+15%3A39%3A28+GMT; sid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; ssid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; LOGIN_STATUS=1; store-region=cn-hn; store-region-src=uid; douyin.com; strategyABtestKey=%221677080469.918%22; bd_ticket_guard_client_data=eyJiZC10aWNrZXQtZ3VhcmQtdmVyc2lvbiI6MiwiYmQtdGlja2V0LWd1YXJkLWNsaWVudC1jZXJ0IjoiLS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tXG5NSUlDRkRDQ0FicWdBd0lCQWdJVVpoK2V0RUhDZlB4SjBJUnhGMFFKcGhhRXVjMHdDZ1lJS29aSXpqMEVBd0l3XG5NVEVMTUFrR0ExVUVCaE1DUTA0eElqQWdCZ05WQkFNTUdYUnBZMnRsZEY5bmRXRnlaRjlqWVY5bFkyUnpZVjh5XG5OVFl3SGhjTk1qTXdNakUxTVRVek9UTXdXaGNOTXpNd01qRTFNak16T1RNd1dqQW5NUXN3Q1FZRFZRUUdFd0pEXG5UakVZTUJZR0ExVUVBd3dQWW1SZmRHbGphMlYwWDJkMVlYSmtNRmt3RXdZSEtvWkl6ajBDQVFZSUtvWkl6ajBEXG5BUWNEUWdBRUpHUW1kaWNMU1hHQXl4QzE2ZlplVFNhdXpqNjI4T3o2RUYydTJaaG1HUTh0NnRCS1BZZjRGSnkrXG52S3ZEWTBTNExwMHg4T2NXSnpHM1p0bHdvcnV3SXFPQnVUQ0J0akFPQmdOVkhROEJBZjhFQkFNQ0JhQXdNUVlEXG5WUjBsQkNvd0tBWUlLd1lCQlFVSEF3RUdDQ3NHQVFVRkJ3TUNCZ2dyQmdFRkJRY0RBd1lJS3dZQkJRVUhBd1F3XG5LUVlEVlIwT0JDSUVJTGkxVmVSK01UVElWQ3NEMzQ4ZitCNDBwYkNxUTZvaVBvbGIyQ0c4ckxKbU1Dc0dBMVVkXG5Jd1FrTUNLQUlES2xaK3FPWkVnU2pjeE9UVUI3Y3hTYlIyMVRlcVRSZ05kNWxKZDdJa2VETUJrR0ExVWRFUVFTXG5NQkNDRG5kM2R5NWtiM1Y1YVc0dVkyOXRNQW9HQ0NxR1NNNDlCQU1DQTBnQU1FVUNJUUNtS3MwTktNZ1BUaVdiXG4wRzdNN2s0K2ZOckNIRmRMc0FCVmErUnpwWUZBR1FJZ0E4czE4dS95MHZKOEd0YVlGVjNHQzdTVXJ3bTdITVZBXG5XTkV0ZTVTUkw3cz1cbi0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS1cbiJ9; csrf_session_id=a20f3074e912cd7499eb53ecdc4db1a9; _tea_utm_cache_1243=undefined; MONITOR_WEB_ID=0d0f5307-22e5-4da5-9733-509ce9a07bff; __ac_nonce=063f637ba00a0a8d51802; __ac_signature=_02B4Z6wo00f017RWXlgAAIDDNFSkGepfEH-0dlrAAI7sBLimHJxVv1T5BysGBkNlcpvr3LeKyLCmY4XZwDrZ0jqSxokT6IUn7HfSFn.hlK-QNAZuu532oIbDVIs0LIs4.MYYg6YpRUbfLUFk66; VIDEO_FILTER_MEMO_SELECT=%7B%22expireTime%22%3A1677685307532%2C%22type%22%3A1%7D; tt_scid=77Cu9dRAW7f0mFfa6zzUUQROFT8L1BR0CaDGGuTexi1Q8PTvg7FzDpvupBEHERJq5644; download_guide=%221%2F20230222%22; FOLLOW_LIVE_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F0%2F1677081445546%22; FOLLOW_NUMBER_YELLOW_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F1677080845546%2F0%22; msToken=1KOGSu7iKfb2VJQJ89TVgUWYYeX3eXGQof9T1ZSz027OKe8TVsgg_okULDbFjWGCq6MUnIo-5aUW6cgPiYGVHZQy1xSFwiE5HoBgl5gh5PrLoGvRpTmtGdJ3hU9-StVk; msToken=FbYQeqlbqNPVPa6dRII68yh3bHHd67y1lWGYIVDyOlYcydKxzxSC80eRqQR2bC_P4W75pjmlT3eZSD2gMMXYmpvA5KweN62l-c_nq7O0iSO6yo0e_KhyglwRWCwESIM=; passport_fe_beating_status=false', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.190.400 QQBrowser/11.5.5240.400' } get =input('输入你需要爬取的抖音主页') url = get data =requests.get(url=url,headers=headers) data.encoding = 'utf-8' # print(data.text) title = re.findall('<p class="__0w4MvO">(.*?)</p>',data.text) img =re.findall('<li class="Eie04v01"><div><a href="//(.*?)" class="B3AsdZT9 chmb2GX8"',data.text) print(title) for i in img: img_url= 'https://'+i print(img_url) data =requests.get(url=img_url,headers=headers) data.encoding='utf-8' # print(data.text) img_url=re.findall('<div class="qylGvmT4"><img class="V5BLJkWV" src="(.*?)"',data.text) title =re.findall('<h1 class="A_DQnbx8"><span><span class="Nu66P_ba"><span><span><span><span>(.*?)</span></span></span></span></span></span></h1>',data.text) print(title,img_url)
-
Python批量爬取堆糖壁纸 介绍 捣鼓一上午,无聊写的,可以批量爬取堆糖壁纸图片,可自定义设置爬取页数。 需要导入两个模块,懂python都应该怎么导入吧,我就不详细说了,图片保存路径自定义是D:/image/需要更改自己设置昂站点:https://www.duitang.com/效果{card-list}{card-list-item}{/card-list-item}{/card-list}所需库import jsonpath #需要自己导入 import requests #需要自己导入 import os #自带库,无需导入 import json #自带库,无需导入 知识点总结收获,所学习模块用法 :@(无语)1. 模拟浏览器请求资源 data = requests.get(url).text 2. 解析网页 因为是json文件,所以直接用jsonpath工具提取数据 html = json.loads(data) photo = jsonpath.jsonpath(html,"$..path") print(photo) 3. 保存代码import json import jsonpath import requests import os title =1 msg =input('输入你要爬取的内容>>>:') if not os.path.exists(f'D:/image/'): os.mkdir((f'D:/image/')) #判断是否有这个文件夹,没有则新建文件夹 for page in range(0,30): #这里自定义爬取页数 url =f'https://www.duitang.com/napi/blog/list/by_search/?kw={msg}&start={page *24}' #爬取urk headers={ 'cookie': 'js=1; _fromcat=category; Hm_lvt_d8276dcc8bdfef6bb9d5bc9e3bcfcaf4=1679106257; sessionid=de7b2587-5983-4322-86f0-ad422aae708d; _ga=GA1.2.1889637025.1680273718; _gid=GA1.2.1427858810.1680273718; Qs_lvt_476474=1679106283%2C1680273734; Qs_pv_476474=948869643746533400%2C3265479778410258000%2C1108286496701228700%2C2054902633385626000%2C2214954563826732300; Hm_lpvt_d8276dcc8bdfef6bb9d5bc9e3bcfcaf4=1680276955', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.54' } print(f'\n================开始爬取第{[page]}页{[msg]}图片================\n',) res =requests.get(url=url,headers=headers).text html =json.loads(res) #json.loads解析 img =jsonpath.jsonpath(html,"$..path") #jsonpath取值,比键值对取值更简洁 name =jsonpath.jsonpath(html,"$..msg")[0] #取图片昵称 for i in img: print(name+str(title),i) #图片名称跟序号拼接 data =requests.get(url=i,headers=headers) with open(f'D:/image/{name+str(title)}'+'.png',mode='wb')as f: # 图片保存路径,需要自己更改 f.write(data.content) title+=1 print('\n\n共爬取:',title-1,'张') print('\n==============下载完毕!!!==============')
-
Python爬取葫芦侠清凉一夏社区图片 介绍 无聊写的,批量爬取葫芦侠清凉一夏社区图片,爬取的是最新的图片链接( 爬取的是链接)想要爬取葫芦侠其他模块的,自己去葫芦侠模块抓包获取链接,放在下面url就好了 :@(无语)效果笔记(知识点)总结一下笔记 :@(亲亲)mode='a', encoding='utf-8' #追加写入,可用作爬取小说、视频、m3u8,utf-8编码 mode='a',即追加(append)模式,mode=' r' #则为读(read). ----------------------------- f.write('\n') #写入换行 ----------------------------- for i in json: img= i['images'] #取图片 title =i['title'] #取标题 for a in img: print(a) #遍历img里面所有的内容代码import requests num =0 """ 想要爬取葫芦侠其他模块的,自己取葫芦侠模块抓包 获取链接,放在上面url就好了 """ yeshu = int(input('你要爬取多少页?')) for page in range(0,yeshu): url=f'http://floor.huluxia.com/post/list/ANDROID/4.1.8?platform=2&gkey=000000&app_version=4.2.1.4&versioncode=358&market_id=tool_tencent&_key=D0CBD749E5A1DEB03FD6CA6429E41E5219895726826CD7BC44DA6CA62B585832B0250BB4AFD5D6B2D389C6E0483C2A19C708407148815CF7&device_code=%5Bd%5D6a308624-0e83-44b6-a56d-2b7020b4b33a&phone_brand_type=OP&start=&count={page*10}&cat_id=56&tag_id=0&sort_by=0' data =requests.post(url).json() #post请求 json =data['posts'] #键值对取值 for i in json: img= i['images'] #取图片 title =i['title'] #取标题 for a in img: image =requests.post(url=a) print(title,a) #打印输出 num += 1 with open(f'葫芦侠_美腿.txt', mode='a', encoding='utf-8',)as f: #保存路径,追加写入 f.write(a) f.write('\n') print('\n=============共爬取',num,'条链接=============')
-
Python批量爬取彼岸桌面壁纸 介绍 该爬虫可以批量爬取彼岸桌面壁纸图片 ::(玫瑰) 页数 延时 爬取地址需要自己修改! 代码也很简单,自己试试吧 站点https://pic.netbian.com效果修改方法 修改爬取地址就好了,地址去官方看地址都是相对应的文件默认保存D盘image文件夹,自己可以看着改代码import re import time import requests import os headers ={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.190.400 QQBrowser/11.5.5240.400', } if not os.path.exists('D:/image/'): os.mkdir(('D:/image/')) for page in range(1,100): url = f'http://pic.netbian.com/4kdongwu/index_{page}.html' print('\n============''正在爬取第', page, '页============\n') #打印提示 time.sleep(3) #延迟 res = requests.get(url=url,headers=headers) res.encoding =res.apparent_encoding #编码 # print(res.text) img_url = re.findall('<a href="/tupian/(.*?).html" target="_blank"><img ',res.text) #取图片url # print(img_url) for img_id in img_url: # print(img_id) link = 'http://pic.netbian.com/tupian/'+img_id+'.html' # print(link) res1 = requests.get(url=link,headers=headers) res1.encoding=res1.apparent_encoding # print(res1.text) data2=re.findall('<img src="(.*?)" ',res1.text)[0] img_title =re.findall('<h1>(.*?)</h1>',res1.text)[0] img_url='http://pic.netbian.com'+data2 image =requests.get(url=img_url,headers=headers).content with open('D:/image/'+img_title+'.jpg',mode='wb')as f: f.write(image) print(img_title,img_url)
-
Python批量爬取抖音主页视频 介绍{card-describe title=" "} 这个比之前的比较方便,输入主页链接即可自动爬取主页全部视频。👀 然后这个使用了 selenium模块,这个模块使用比较麻烦,配置的东西也比较多,我尽量写清楚{/card-describe}{lamp/}保存路径修改保存路径自己在这里修改 模块导入所需模块: {card-default label="模块:selenium==3.141.0" width=""}模块:requests{/card-default}cmd 复制输入下面安装命令回车: {card-list}{card-list-item}pip install -i https://pypi.doubanio.com/simple/ selenium==3.141.0pip install -i https://pypi.doubanio.com/simple/ requests{/card-list-item}{/card-list}浏览器驱动使用的是谷歌浏览器,查看你自己的浏览器版本,下载对应的驱动器,驱动器链接:https://registry.npmmirror.com/binary.html?path=chromedriver{collapse}{collapse-item label="驱动配置设置" open}查看这里跟你差不多的版本,我选择的是下面的版本然后下载这个win谷歌浏览器驱动,解压之后把这个chromedriver.exe放在python解释器同级目录python同级目录,然后复制这个chromedriver.exe位置链接,放在下面代码路径进行了这里填你的绝对路径,不填会报错这里获取链接{/collapse-item}{/collapse}效果代码import re import requests import time import os from selenium import webdriver #引用模块 selenium==3.141.0 data_url = input('输入你要爬取抖音博主主页链接') driver= webdriver.Chrome(r'D:\python\chromedriver.exe') # 引用chromedriver.exe程序,填你自己的路径 driver.get(f'{data_url}') def drop_down(): for x in range(1, 30, 4): time.sleep(2) #延时 j = x / 9 js = 'document.documentElement.scrollTop=document.documentElement.scrollHeight * %f'%j #下滑 driver.execute_script(js) drop_down() lis = driver.find_elements_by_css_selector('.Eie04v01') #selenium取值 if not os.path.exists('D:/video/'): os.mkdir(('D:/video/')) for li in lis: try: url = li.find_element_by_css_selector('a').get_attribute('href') #下面路径 print(url) headers ={ 'cookie': 'douyin.com; ttwid=1%7CWi46JI7KdSaF9yqta1kL28XUbEiDv91IIfMOxY-EhZ0%7C1675841330%7C89a9430cc447d8576d53d4fbc9546dfa417bc4e88d586762cbe878514cc1df57; passport_csrf_token=9d7dab91f7a045a68d9fa2deb1f60b0c; passport_csrf_token_default=9d7dab91f7a045a68d9fa2deb1f60b0c; s_v_web_id=verify_ldvcnlvk_10t9slUd_4n0m_42o1_8p9b_8ZRx0cAV4nv5; home_can_add_dy_2_desktop=%220%22; xgplayer_user_id=646767496422; passport_assist_user=CkGmgQ_jszMN1m-PPWYjH_QNdsf_8klBB_8wS0bJsZWcfTnMc97HC73w9WNOnHbLoE1PnrcXtGsuQy6FV7HUCWBMZhpICjxihoJBypQ-JpI9KH--ZN_-TY41fsc-wLsvlbmXM97JsrDcbP2eTP44_kJCdfLHGFu-6P8ZZJ6MfHQMHRAQsrKpDRiJr9ZUIgEDDUbOBg%3D%3D; n_mh=1a3e5XCqMARKIH9Y88jP23zsLolfuhxxp5ZQomXRvOY; sso_uid_tt=c2f6884d45856a3a866e96b167c36a10; sso_uid_tt_ss=c2f6884d45856a3a866e96b167c36a10; toutiao_sso_user=ab04894ee6c7df3eeecec15922d832ea; toutiao_sso_user_ss=ab04894ee6c7df3eeecec15922d832ea; sid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; ssid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; odin_tt=fc686e88a993cd8b3c475705e2e286b79bea48c0f1571b1d71907cb4bc263bd8e81c55f29d0d2d82e6f2f828e0f9322ffc9a0c11a8d50f931542468903f614d5; passport_auth_status=f7cba991b8c1ae560c1f55df240d23f4%2C; passport_auth_status_ss=f7cba991b8c1ae560c1f55df240d23f4%2C; uid_tt=4b64917790b6f7fa2f4452c2c2322ae0; uid_tt_ss=4b64917790b6f7fa2f4452c2c2322ae0; sid_tt=052095ac92e67fd17382c560a00588f4; sessionid=052095ac92e67fd17382c560a00588f4; sessionid_ss=052095ac92e67fd17382c560a00588f4; sid_guard=052095ac92e67fd17382c560a00588f4%7C1676475573%7C5183995%7CSun%2C+16-Apr-2023+15%3A39%3A28+GMT; sid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; ssid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; LOGIN_STATUS=1; store-region=cn-hn; store-region-src=uid; douyin.com; strategyABtestKey=%221677080469.918%22; bd_ticket_guard_client_data=eyJiZC10aWNrZXQtZ3VhcmQtdmVyc2lvbiI6MiwiYmQtdGlja2V0LWd1YXJkLWNsaWVudC1jZXJ0IjoiLS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tXG5NSUlDRkRDQ0FicWdBd0lCQWdJVVpoK2V0RUhDZlB4SjBJUnhGMFFKcGhhRXVjMHdDZ1lJS29aSXpqMEVBd0l3XG5NVEVMTUFrR0ExVUVCaE1DUTA0eElqQWdCZ05WQkFNTUdYUnBZMnRsZEY5bmRXRnlaRjlqWVY5bFkyUnpZVjh5XG5OVFl3SGhjTk1qTXdNakUxTVRVek9UTXdXaGNOTXpNd01qRTFNak16T1RNd1dqQW5NUXN3Q1FZRFZRUUdFd0pEXG5UakVZTUJZR0ExVUVBd3dQWW1SZmRHbGphMlYwWDJkMVlYSmtNRmt3RXdZSEtvWkl6ajBDQVFZSUtvWkl6ajBEXG5BUWNEUWdBRUpHUW1kaWNMU1hHQXl4QzE2ZlplVFNhdXpqNjI4T3o2RUYydTJaaG1HUTh0NnRCS1BZZjRGSnkrXG52S3ZEWTBTNExwMHg4T2NXSnpHM1p0bHdvcnV3SXFPQnVUQ0J0akFPQmdOVkhROEJBZjhFQkFNQ0JhQXdNUVlEXG5WUjBsQkNvd0tBWUlLd1lCQlFVSEF3RUdDQ3NHQVFVRkJ3TUNCZ2dyQmdFRkJRY0RBd1lJS3dZQkJRVUhBd1F3XG5LUVlEVlIwT0JDSUVJTGkxVmVSK01UVElWQ3NEMzQ4ZitCNDBwYkNxUTZvaVBvbGIyQ0c4ckxKbU1Dc0dBMVVkXG5Jd1FrTUNLQUlES2xaK3FPWkVnU2pjeE9UVUI3Y3hTYlIyMVRlcVRSZ05kNWxKZDdJa2VETUJrR0ExVWRFUVFTXG5NQkNDRG5kM2R5NWtiM1Y1YVc0dVkyOXRNQW9HQ0NxR1NNNDlCQU1DQTBnQU1FVUNJUUNtS3MwTktNZ1BUaVdiXG4wRzdNN2s0K2ZOckNIRmRMc0FCVmErUnpwWUZBR1FJZ0E4czE4dS95MHZKOEd0YVlGVjNHQzdTVXJ3bTdITVZBXG5XTkV0ZTVTUkw3cz1cbi0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS1cbiJ9; csrf_session_id=a20f3074e912cd7499eb53ecdc4db1a9; _tea_utm_cache_1243=undefined; MONITOR_WEB_ID=0d0f5307-22e5-4da5-9733-509ce9a07bff; __ac_nonce=063f637ba00a0a8d51802; __ac_signature=_02B4Z6wo00f017RWXlgAAIDDNFSkGepfEH-0dlrAAI7sBLimHJxVv1T5BysGBkNlcpvr3LeKyLCmY4XZwDrZ0jqSxokT6IUn7HfSFn.hlK-QNAZuu532oIbDVIs0LIs4.MYYg6YpRUbfLUFk66; VIDEO_FILTER_MEMO_SELECT=%7B%22expireTime%22%3A1677685307532%2C%22type%22%3A1%7D; tt_scid=77Cu9dRAW7f0mFfa6zzUUQROFT8L1BR0CaDGGuTexi1Q8PTvg7FzDpvupBEHERJq5644; download_guide=%221%2F20230222%22; FOLLOW_LIVE_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F0%2F1677081445546%22; FOLLOW_NUMBER_YELLOW_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F1677080845546%2F0%22; msToken=1KOGSu7iKfb2VJQJ89TVgUWYYeX3eXGQof9T1ZSz027OKe8TVsgg_okULDbFjWGCq6MUnIo-5aUW6cgPiYGVHZQy1xSFwiE5HoBgl5gh5PrLoGvRpTmtGdJ3hU9-StVk; msToken=FbYQeqlbqNPVPa6dRII68yh3bHHd67y1lWGYIVDyOlYcydKxzxSC80eRqQR2bC_P4W75pjmlT3eZSD2gMMXYmpvA5KweN62l-c_nq7O0iSO6yo0e_KhyglwRWCwESIM=; passport_fe_beating_status=false', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.190.400 QQBrowser/11.5.5240.400' } # url = 'https://www.douyin.com/video/6950985129997126952' #测试url response = requests.get(url=url,headers=headers) response.encoding = 'utf-8' title = re.findall('<title data-react-helmet="true">(.*?)</title>',response.text)[0] video_title =re.sub('[#@。“”&\- 抖音]','',title) #re取视频标题 data = re.findall('playApi(.*?)playAddrH265',response.text)[0] #取加密url data_url =requests.utils.unquote(data).replace('","','').replace('":"','https:') #解密 print(video_title,data_url) #打印输出标题跟url video_url = requests.get(url=data_url,headers=headers).content with open('D:/video/'+video_title+'.mp4',mode='wb')as f: #文件保存 路径,可自己修改 f.write(video_url) except Exception as e: print(e)
-
Python爬取抖音主页视频 介绍 技术有限,只使用了requests模块,爬取操作过程有点复杂,一次大概爬取20个视频,该帖只是分享学习心得。 :@(小怒) 已更新批量爬取抖音视频,请移步 批量爬取抖音操作步骤{card-list}{card-list-item}打开作者主页,按F12或者右键点击检查,进入开发人员选项 :@(汗) 按了这个按键之后,刷新一下网页需要抓取作者下面视频,看此图把这值复制到python编辑器回车进行了效果{/card-list-item}{/card-list}代码import requests data_url= input('输入抖音主页url链接') url = f'{data_url}' headers ={ 'Cookie': 'ttwid=1%7CNYBsOJjLZ2AsV5W4Iz4ZzspVZTkn2KyMX7W0XiixtQQ%7C1667296084%7Cd2307abe2d42dca1611e1830098224cad0edc815aeb9b025161e95d3bc2302cc; passport_csrf_token=925a434d5c62ddccb4b938b7fda2d766; passport_csrf_token_default=925a434d5c62ddccb4b938b7fda2d766; s_v_web_id=verify_le3vazcc_eKdzRY18_VbQm_4b0c_Bqjq_OMI7a8xreQcv; tt_scid=BnKWC8SzLa7R2CY4QfSzwRW1JqcNfsG3h1FzEnkhBsb7s773aVwkWE3VnK6xT2Fjfc8b; SEARCH_RESULT_LIST_TYPE=%22single%22; download_guide=%223%2F20230224%22; strategyABtestKey=%221677550434.211%22; n_mh=FskDsKYpXNjKBP0t6Gko5ZTJydFA7S4umyMW4C5obHE; passport_auth_status=2bb728821b62c7a71d1073a297196011%2C; passport_auth_status_ss=2bb728821b62c7a71d1073a297196011%2C; FOLLOW_LIVE_POINT_INFO=%22MS4wLjABAAAAsPPiLKnMyCVF_v9F8i8KJQ7ftqflDrcZRkYRM_MqTRk%2F1677600000000%2F0%2F1677550508469%2F0%22; store-region=cn-hn; store-region-src=uid; LOGIN_STATUS=0; sid_guard=cf9d3b21a4a97290783acfc26a21bb7d%7C1677556074%7C21600%7CTue%2C+28-Feb-2023+09%3A47%3A54+GMT; uid_tt=1b092a049e575cc02094b4ebcd067e49; uid_tt_ss=1b092a049e575cc02094b4ebcd067e49; sid_tt=cf9d3b21a4a97290783acfc26a21bb7d; sessionid=cf9d3b21a4a97290783acfc26a21bb7d; sessionid_ss=cf9d3b21a4a97290783acfc26a21bb7d; sid_ucp_v1=1.0.0-KDNmZjg5MmIxODUxNjVjNWQzNDRiMWFiMzA4ZDAwNzhjOTgwYTUwNTIKCBDq8vWfBhgNGgJobCIgY2Y5ZDNiMjFhNGE5NzI5MDc4M2FjZmMyNmEyMWJiN2Q; ssid_ucp_v1=1.0.0-KDNmZjg5MmIxODUxNjVjNWQzNDRiMWFiMzA4ZDAwNzhjOTgwYTUwNTIKCBDq8vWfBhgNGgJobCIgY2Y5ZDNiMjFhNGE5NzI5MDc4M2FjZmMyNmEyMWJiN2Q; VIDEO_FILTER_MEMO_SELECT=%7B%22expireTime%22%3A1678172191557%2C%22type%22%3A1%7D; home_can_add_dy_2_desktop=%221%22; __ac_nonce=063fdb7ac006195a4e835; __ac_signature=_02B4Z6wo00f010S0ygAAAIDDyDaEjsgEw3dEhM6AALLbRvWRtTjaphY65KhY1LF3sMoI.W00lFeOONJBRI3kfNWjEVqP2Ile4WG9a30aSj2F4ieYktiLBKGOZxABE0FoWqP-7auPzTk42JO.15; msToken=GF3L_CnlFMvFZqTifNPlPYaldF-_wjhYnKOkEy7X2GLfhpa0LP3UbvzERsgfyq0XzOWyedW9IsRBoLOu0RwSedpls81d7uuBviHSIDOcgQWHQ3RAxsB5GixrpEU7UCM=; msToken=7PJMuDzhOpSyMzTM12rynp74R9GHeaZSF_GxEDzr-F3IajHONmF4YV_Al31OyhInsseEIVudv7lTeGWO2SDyNiWeP4QyVc_eLcEuUE8Uao93mce3I8EpB39le8dyvBU=', 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Mobile Safari/537.36' } rsq = requests.get(url=url,headers=headers).json() data = rsq['aweme_list'] len_num = len(data) for i in range(0,len_num): title = data[i]['desc'] url = data[i]['video']['play_addr_lowbr']['url_list'][0] print(title,url) video = requests.get(url=url,headers=headers).content with open(f'C:/Users/枫/Desktop/img/imgs/{title}'+ '.mp4',mode='wb')as f: f.write(video) print('共下载:',len_num)
-
-
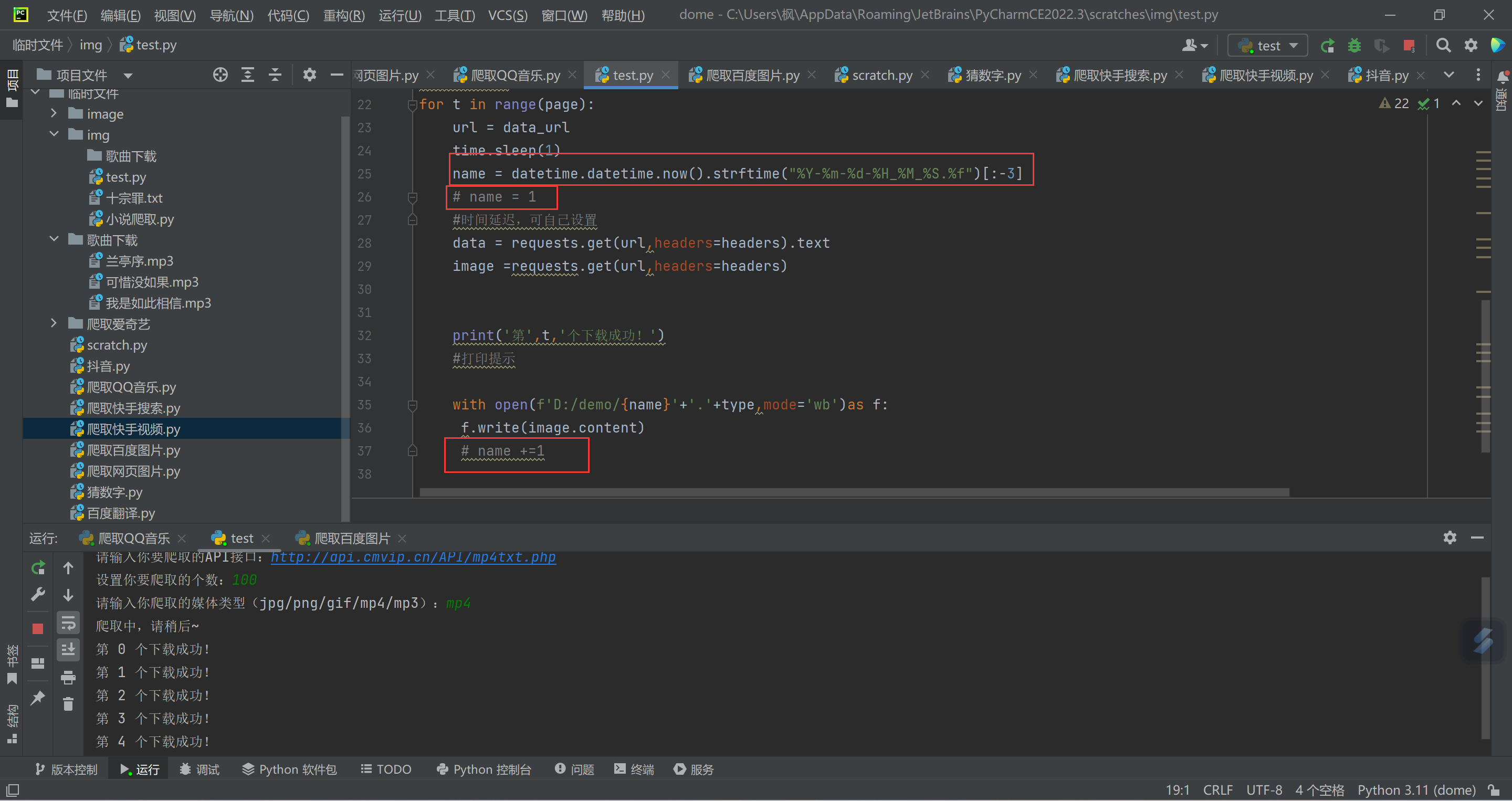
Python爬取API接口内容保存 介绍 这个可以爬取API站点接口内容,能爬取视频、音频、图片并且保存到本地,自己写出来的 可以设置爬取页数,延时什么的。 下面代码都注释了,自己看看吧,不会的联系博主!?{lamp/}ps:爬取的文件都是按数字顺序的如果你中断爬取,再次爬取的时候会覆盖之前的文件所以文件名是时间戳如需按数字顺序保存,请去掉这个注释,添加这个注释即可效果图代码import requests import datetime import time import os data_url =input('请输入你要爬取的API接口:') #输入api接口站点 page =int(input('设置你要爬取的个数:')) #输入你想要爬取的个数 type = input('请输入你爬取的媒体类型(jpg/png/gif/mp4/mp3):') #保存类型 print('爬取中,请稍后~') headers ={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50' #请求头 } if not os.path.exists('D:/demo/'): os.mkdir(('D:/demo/')) #定义文件名字 for t in range(page): url = data_url time.sleep(1) name = datetime.datetime.now().strftime("%Y-%m-%d-%H_%M_%S.%f")[:-3] # name = 1 #时间延迟,可自己设置 data = requests.get(url,headers=headers).text image =requests.get(url,headers=headers) print('第',t,'个下载成功!') #打印提示 with open(f'D:/demo/{name}'+'.'+type,mode='wb')as f: f.write(image.content) # name +=1
-
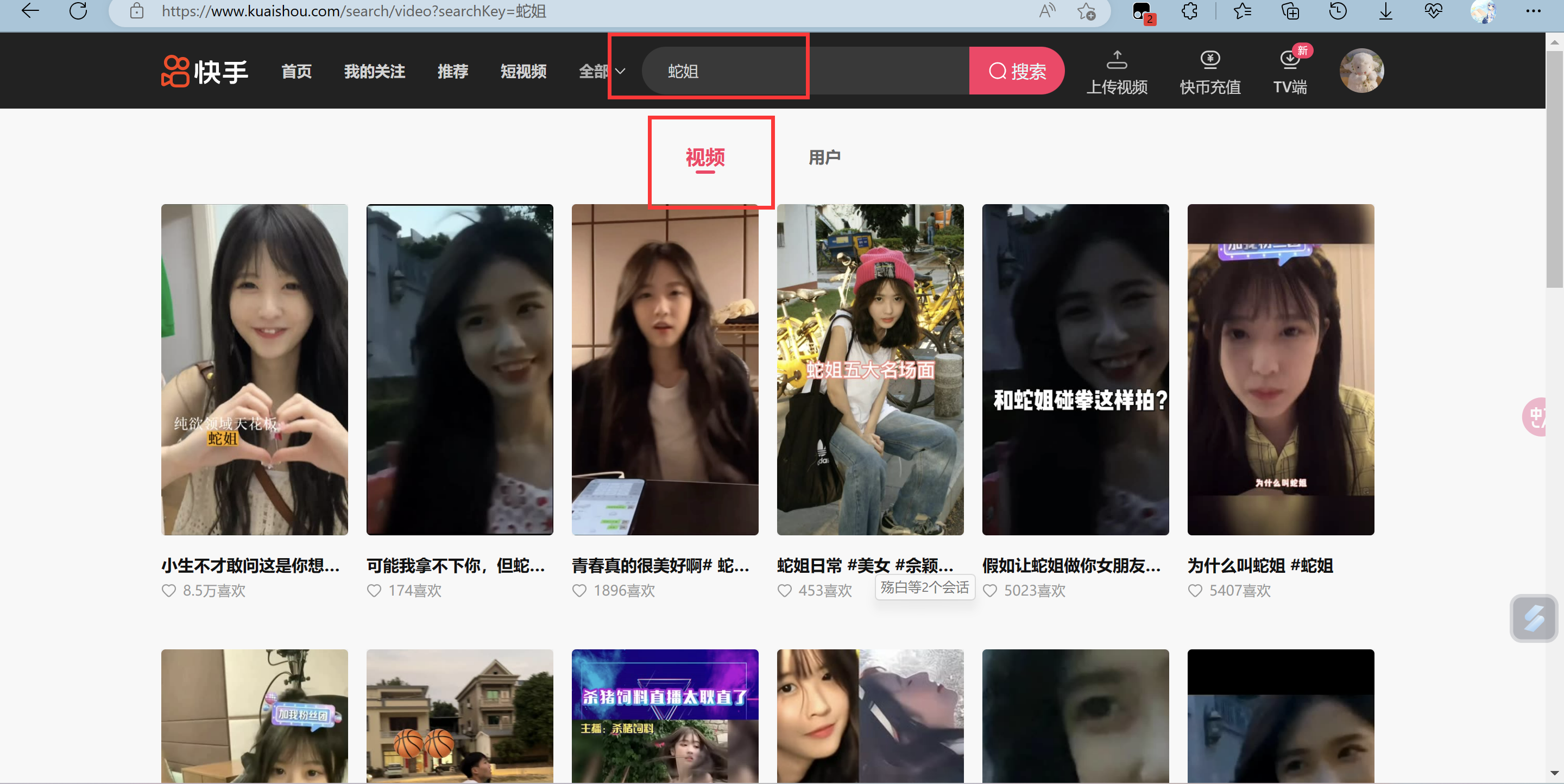
Python爬取快手搜索页面视频 介绍 这个跟上个快手帖子差不多,但可设置爬取页面,嗯嗯 随便分享一下吧!这个爬取的是快手搜索页面下面的视频?效果别忘记在D盘新建video文件夹也可以自己修改下面代码路径 代码import requests import re name =input('请输入你要爬取的内容') page =input('请输入你要爬取的页数') json = { 'operationName': "visionSearchPhoto", 'query': "fragment photoContent on PhotoEntity {\n id\n duration\n caption\n originCaption\n likeCount\n viewCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n musicBlocked\n __typename\n}\n\nfragment feedContent on Feed {\n type\n author {\n id\n name\n headerUrl\n following\n headerUrls {\n url\n __typename\n }\n __typename\n }\n photo {\n ...photoContent\n __typename\n }\n canAddComment\n llsid\n status\n currentPcursor\n tags {\n type\n name\n __typename\n }\n __typename\n}\n\nquery visionSearchPhoto($keyword: String, $pcursor: String, $searchSessionId: String, $page: String, $webPageArea: String) {\n visionSearchPhoto(keyword: $keyword, pcursor: $pcursor, searchSessionId: $searchSessionId, page: $page, webPageArea: $webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n ...feedContent\n __typename\n }\n searchSessionId\n pcursor\n aladdinBanner {\n imgUrl\n link\n __typename\n }\n __typename\n }\n}\n", 'variables': {'keyword': name, 'pcursor': page, 'page': "search",}, } headers = { 'Cookie': "kpf=PC_WEB; clientid=3; did=web_8fe7e63f0eb61560a3d9d584a0192980; didv=1676463621529; ktrace-context=1|MS43NjQ1ODM2OTgyODY2OTgyLjQ1MTk4MTEzLjE2NzY1MjM4MzIxMzQuMjE3Mzk4|MS43NjQ1ODM2OTgyODY2OTgyLjYyNjI3Mzg5LjE2NzY1MjM4MzIxMzQuMjE3Mzk5|0|graphql-server|webservice|false|NA; userId=1448552402; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqABHECygd_FAYtj391KlgQ26rwaUEmFI-rxQsP1qmfmA-_rwKkThSPxfFNebSG0e1hVLgS627iuFjUW0aOStjm-lzRJQD5xkI7jI2pR9zDT6HHSHuyRmJQLNBGQ3XZNn0zjAwrOD0XvHpPWKLxspPJHFgLkvC-faqh1sleDAbprtd3uMJqpP3-2dzA42q823RlLJqC406oJkGvgDjeMnIQt4hoSnIqSq99L0mk4jolsseGdcwiNIiDPok1ufZOQoy1uG6Y5fWcP8CbK1qh5dscVxn3PcsG6KCgFMAE; kuaishou.server.web_ph=27aa693d1ac88453398b2d8a6c9e9fb51229; kpn=KUAISHOU_VISION", 'Host': "www.kuaishou.com", 'Origin': "https://www.kuaishou.com", 'Referer': f"https://www.kuaishou.com/search/video?searchKey=%E8%9B%87%E5%A7%90", 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.190.400 QQBrowser/11.5.5240.400" #请求头 } url = 'https://www.kuaishou.com/graphql' #快手链接 response = requests.post(url=url,headers=headers,json=json) json_data = response.json() feeds = json_data['data']['visionSearchPhoto']['feeds'] for feed in feeds: titil = feed['photo']['caption'] #取视频标题 video_url = feed['photo']['photoUrl'] #取视频链接url titil = re.sub('[\\/:*?<>|\\n#@)\》\."\《(\r]','',titil) #正则表达式替换特殊符号 print(titil,video_url) #打印提示 with open(f'D:/video/{titil}''.mp4',mode='wb')as f: #保存路径 video = requests.get(video_url).content f.write(video) print('\n\n') print('下载完毕!!!')
-
-
-
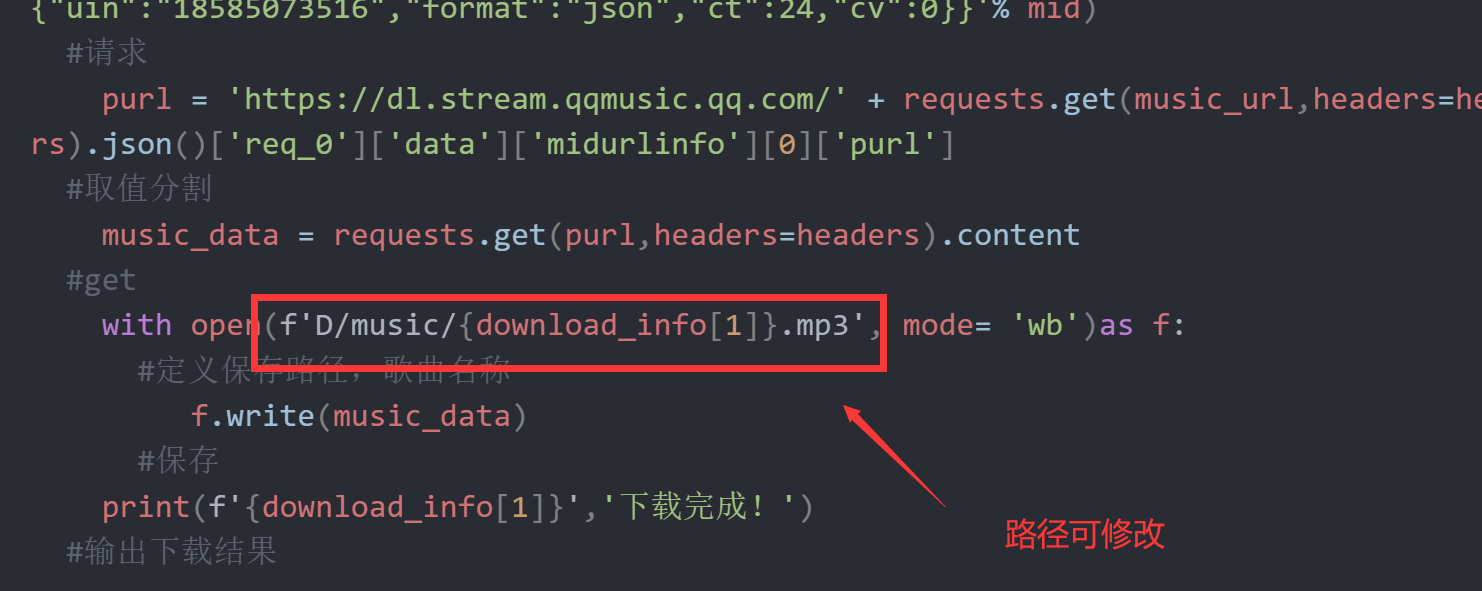
Python爬取QQVIP音乐 介绍 这几天都在研究爬虫,然后捣鼓一下午写好了这个,可以爬取QQ付费音乐 :@(赞一个) (技术有限,只能爬取部分) 有个bug,cookei过期,好像就用不了了{dotted startColor="#ff6c6c" endColor="#1989fa"/}PS:需要导入两个模块{card-describe title="引用模块"} requests prettytable as pt 需在D盘新建music文件夹,不然报错,也可以自定义修改保存路径 {dotted startColor="#ff6c6c" endColor="#1989fa"/}快速导入模块方法如下:win+r 输入cmd在cmd里面分别复制粘贴回车进行了pip install -i https://pypi.doubanio.com/simple/ requestspip install -i https://pypi.doubanio.com/simple/ prettytable{/card-describe}效果代码 import requests import prettytable as pt #一个格式输出的模块 geshou = input('请输入你想要下载的歌手或者歌曲名:') #输入歌手名字 url = f'http://u.y.qq.com/cgi-bin/musicu.fcg?data=%7B%22comm%22:%7B%22ct%22:%2219%22,%22cv%22:%221882%22,%22uin%22:%220%22%7D,%22searchMusic%22:%7B%22method%22:%22DoSearchForQQMusicDesktop%22,%22module%22:%22music.search.SearchCgiService%22,%22param%22:%7B%22grp%22:1,%22num_per_page%22:30,%22page_num%22:1,%22query%22:%22%7B{geshou}%7D%22,%22search_type%22:0%7D%7D%7D%0A' #f可打印输出 data = requests.get(url).json() #获取url json zhi = data['searchMusic']['data']['body']['zhida']['list'][0] #json取值 song = zhi['track_list']['items'] tb = pt.PrettyTable() #打印表格 tb.field_names = ['序号','歌名','状态'] #打印表格 music_info_list = [] numbers = 0 #定义歌曲序号 for list in song: #for循环 id = list['mid'] #取歌曲id name = list['name']#取歌曲昵称 zt = '√' # 状态 # print(numbers,name,zt) #测试输出 tb.add_row([numbers,name,zt]) #赋予表格内容 music_info_list.append([id,name,'下载成功']) numbers += 1 print(tb) #输出表格样式 headers = { headers = { 'cookie': 'pgv_pvid=408238320; fqm_pvqid=c12454a0-4580-4d49-b886-2bf22db76a9e; ts_uid=7308117800; RK=mnvFA8P8ep; ptcz=e886f2438004cd93a6548c522422af8d91ee8453d3fb8d0d838fe4e98863764e; euin=oKvsNKElNKEkon**; tmeLoginType=2; pac_uid=1_469979950; iip=0; o_cookie=1469979950; tvfe_boss_uuid=bf2125500525cd30; pgv_info=ssid=s8054603064; _qpsvr_localtk=0.3553167419354355; fqm_sessionid=fbb172c4-1e70-4c71-bed7-a7c049452ae6; ts_refer=i.y.qq.com/; ariaDefaultTheme=undefined; ts_last=y.qq.com/n/ryqq/search; login_type=1; qm_keyst=Q_H_L_5ScLucJrkG-lUI0lfjBuXm5idKRNPJQ5gOi6AQa-45tBhho-xvsERMA; wxopenid=; psrf_qqopenid=413A01BF0479B022D91B709C577DF361; psrf_qqaccess_token=ABFD4D3D17C22695A37D62587674B6EA; psrf_access_token_expiresAt=1684934769; qqmusic_key=Q_H_L_5ScLucJrkG-lUI0lfjBuXm5idKRNPJQ5gOi6AQa-45tBhho-xvsERMA; wxrefresh_token=; psrf_qqunionid=9EB7B4A00E86499307EADADC8B935FD1; qm_keyst=Q_H_L_5ScLucJrkG-lUI0lfjBuXm5idKRNPJQ5gOi6AQa-45tBhho-xvsERMA; uin=1469979950; psrf_musickey_createtime=1677158769; psrf_qqrefresh_token=C4FF1DABB43775D586C194BF1F17934D; wxunionid=', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50' } #模拟请求 } while True: input_index = eval(input("请输入你要下载的歌曲序号(按-1退出):")) #定义输出 if input_index == -1: #输入-1退出输入 break #退出 download_info = music_info_list[input_index] #取歌曲名称 mid = download_info[0] #取歌曲mid music_url = ('https://u.y.qq.com/cgi-bin/musicu.fcg?format=json&data={"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"358840384","songmid":["%s"],"songtype":[0],"uin":"1443481947","loginflag":1,"platform":"20"}},"comm":{"uin":"18585073516","format":"json","ct":24,"cv":0}}'% mid) #请求 purl = 'https://dl.stream.qqmusic.qq.com/' + requests.get(music_url,headers=headers).json()['req_0']['data']['midurlinfo'][0]['purl'] #取值分割 music_data = requests.get(purl,headers=headers).content #get with open(f'D/music/{download_info[1]}.mp3', mode= 'wb')as f: #定义保存路径,歌曲名称 f.write(music_data) #保存 print(f'{download_info[1]}','下载完成!') print(purl) #输出下载结果
-
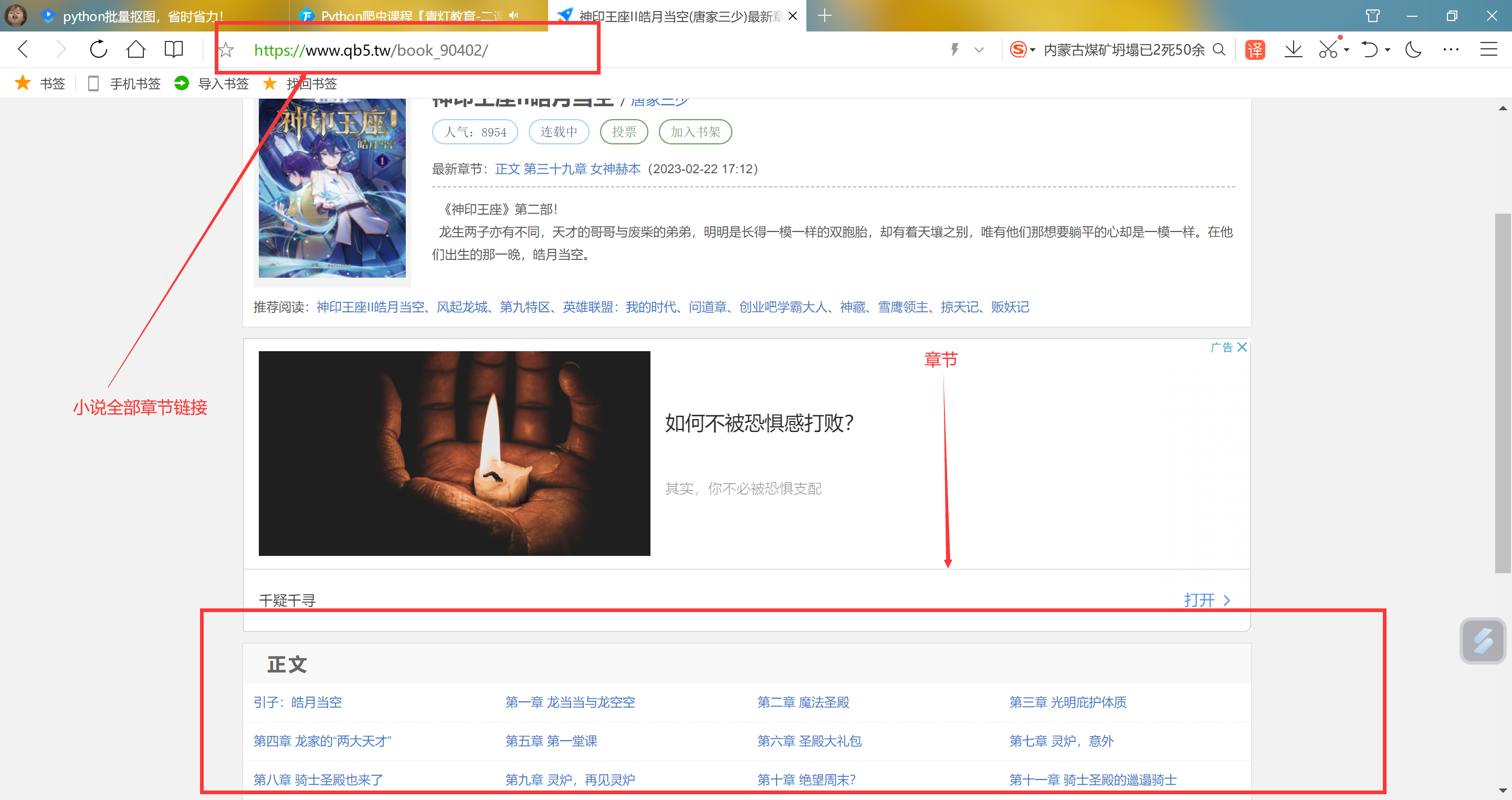
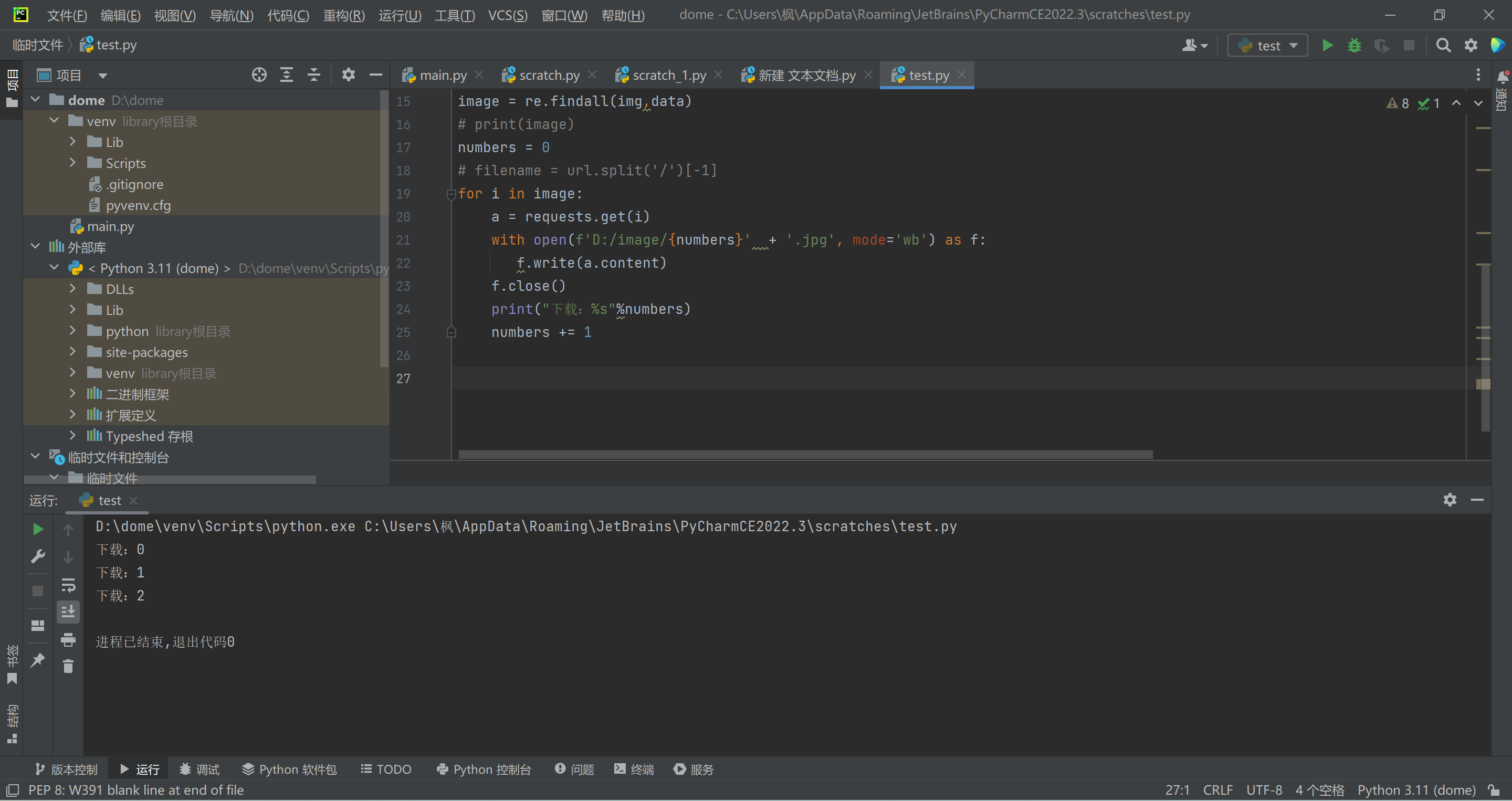
Python爬取网页小说 介绍 小白,懂得不多,随便分享一下自己写的 :@(看热闹) 只写了这个小说站点:https://www.qb5.tw 因为很多网站html标签不一样,我只适配写了这个,如有想要爬取的站点,可以联系我,我试试(尽量,我小白) ::(滑稽)修改 下面代码里面都标注了,你自己看看,不懂的可以联系博主(仅限www.qb5.tw站点章节链接){dotted startColor="#ff6c6c" endColor="#1989fa"/}获取文章链接 如果正则表达式,内容没有替换成功,可以Ctrl+h,一键替换文本里面内容效果 代码""" 我就写了这个站点:www.qb5.tw 那按道理也只能爬这个网站 其他站点没去测试 """ import requests import re novel = input('请输入你想要下载小说链接(仅支持www.qb5.tw):') name = input('请输入你保存小说名字') chapter = novel data = requests.get(chapter).text # 获取网页内容 info_list = re.findall('<dd><a href="(.*?)">(.*?)</a></dd>',data) # re正则表达式,获取链接,小说标题 for info in info_list: # for循环 sub_url = (info[0]) # 取小说url title = (info[1]) # 取小说标题 url = novel + sub_url # 小说链接,需要爬取其他的小说,在这里改一下(就写了这个站点,www.qb5.tw)其他网站没去测试 res = requests.get(url,).text # 取网页内容 text= re.findall('<div id="content">.*?</div>',res)[0] # 正则表达式取小说内容 text = title +'\n\n\n\n'+ text.replace('<div id="nr1"> 全本小说网 www.qb5.tw,最快更新<a href="https://www.qb5.tw/book_116659/">',' ').replace('<div id="content"> 全本小说网 www.qb5.tw,最快更新',' ').replace('&nbs... -->><br><center class="red">本章未完,点击下一页继续阅读</center>',' ').replace('新书上传,希望大家可以先收藏、推荐,正式连载将于5月20号。',' ').replace('本章未完,点击下一页继续阅读</center>',' ').replace(' -->><br><center class="red">','').replace('<br ... -->><br><center class="red">本章未完,点击下一页继续阅读</center>',' ').replace('<div id="nr1"> ','').replace('<br />','\n').replace(' ',' ').replace('每日更新:暂定每天上午10点左右一章、12点左右一章。 </div>',' ').replace(' <br><br>',' ').replace('宇宙职业选手</a>最新章节!<br><br> ','').replace(' ','').replace('</div>',' ').replace('...','\n\n\n\n') # 正则表达式,替换不需要的内容(标签、广告、html标签) # print(text) open(f'{name}.txt',mode='a',encoding='utf-8').write(text) # 写入文件,编码,这里可以自定义文件名字 print('下载成功√'+'\t'+title ) #输出打印
-
python爬取网页图片 介绍 这个能爬取一些网页图片,没开https和图片防盗链按道理应该能爬取到的。 也只能适用于一些小网页,小博客,代码也很简单 :@(看热闹) 使用了requests库 还有re正则表达式修改代码url里面内容,即可更换爬取内容# !/user/bin/env python # -*- coding: utf-8 -*- # des: 下载任何网页的图片 import re import requests def download_img(): error_count = 0 success_count = 0 url = input('请输入您要下载的图片的网址:') headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75' } web_text = requests.get(url, headers=headers).text ex = '<img.*?src="(.*?)".*?' img_list = re.findall(ex, web_text) print('图片地址:', img_list) if len(img_list) == 0: print('该网站有反爬虫机制,爬取失败,请换个网站继续尝试。') for img in img_list: try: # 补充协议头 if not (img.startswith('http') or img.startswith('https')): img = 'http:' + img img_binary = requests.get(img, headers=headers).content # 切割出最后一个字符串 file_name = img.split('/')[-1] # 切割 query字符 file_name = file_name.split('?')[0] with open(f'./img/{file_name}'+'.jpg', 'wb') as fp: fp.write(img_binary) print(file_name, ',下载成功') success_count += 1 except Exception as e: print(e) error_count += 1 continue print('下载图片结束!') return success_count, error_count if __name__ == '__main__': success_count, error_count = download_img() print(f'总计下载:{success_count},下载失败:{error_count}')